一.Apriori简介
Apriori算法是求出数据集中频繁项集的算法, 求出频繁项集就可以很容易求出强规则了。
Apriori算法
二.Apriori算法


三.Apriori算法例子
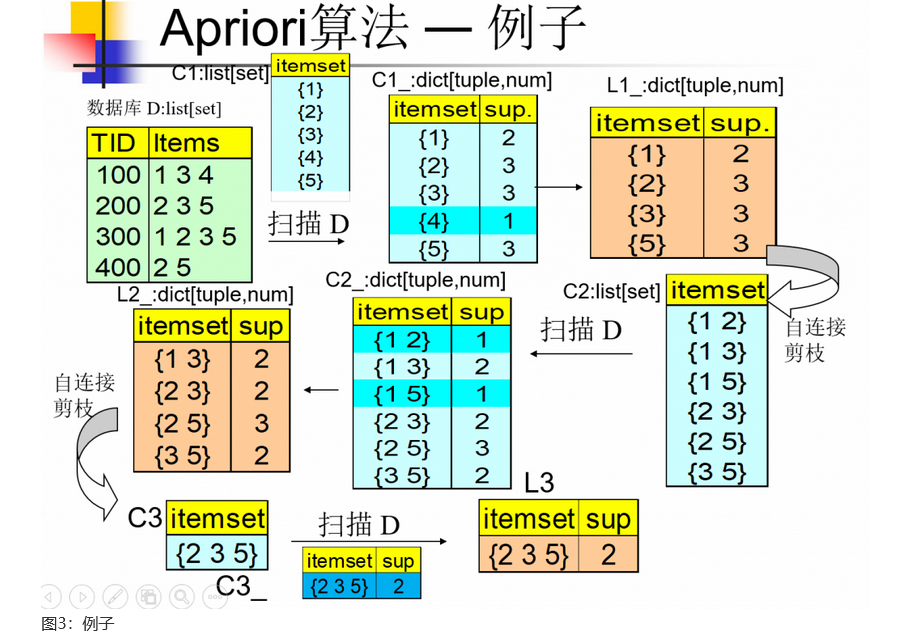
我在原来的PPT上加了点:
- 添加了C1,使得其更加具有通用性表达。
- C1,C2,C3和C1_,C2_,C3_表示不同的结构,前者是集合的list,后者是key的类型为tuple,vlaue类型为int的list。之所以这么设置是因为通过C2_和数据库datum得到C2_采用的方式是for循环嵌套,然后用set提供的A∩B==A推导出A包含于B来计数A,而C2_的key类型只能为不可变型的类型。
- tuple和set和list可以相互转换,我的程序中这种转换比较多。
- python中tuple转换一个元素用
(a,)而不是(a) - python初始化list大小:
a=[None]*10
四.代码(高亮插件有点问题,后更)
import time
def get_data_base(filename):
datum = list()
datum_item = set()
f = open(filename)
line = f.readline()
while(line):
str_list = line.split() #split返回list,默认参数分割" "。
int_list = [int (x,10) for x in str_list] #将每个输入存储为int类型,后面涉及到比较,不可以为str类型,除非数据集用单个字符表示商品类型
datum_item = set(int_list)
datum.append(datum_item)
line = f.readline()
return datum
#读入文件,生成list[set],每行记录为一个set,
#C1_:list[tuple,int]
def get_C1_(datum):
C1_ = dict()
for datum_item in datum:
for item in datum_item:
temp = (item,)#后面这个逗号说明将它转化为一个元组
if temp in C1_ :
C1_[temp] = C1_[temp]+1
else:
C1_[temp] = 1
return C1_
#由后选项集C1_和筛选次数得到频繁项集L1
#L1:dict[tuple,num]
def get_L1_itemset(C1_, frequence):
L1 = {}
for key, value in C1_.items():
if value >= frequence:
L1[key] = value
return L1
#自连接和剪枝,产生C1
#C1:list[set]
def connect_and_clip(L1):
L1_keys = list(L1.keys())#将dict的key转化为list操作
C2 = []
#自连接
for i in range(0,len(L1_keys)):
for j in range(i+1, len(L1_keys)):
C2_item = set()
#如果是L1的话不用自连接
if len(L1_keys[0]) == 1:
C2_item.add(int(L1_keys[i][0]))
C2_item.add(int(L1_keys[j][0]))
else:
before1 = L1_keys[i][0:-1]
before2 = L1_keys[j][0:-1]
last1 = L1_keys[i][-1]
last2 = L1_keys[j][-1]
#这里可能有问题,因为我之前的操作没有排序,所以before1==before2时,last1>last2也符合条件但是没有加入C2,测试样例没问题
if before1==before2 and last1 < last2:
C2_item = set(before1)
C2_item.add(last1)
C2_item.add(last2)
if (len(C2_item) != 0):#C2_item初始化为空集,如果经过前面的操作,不为0,则加入到C2中,为0则不加入,因为空集会影响判断
C2.append(C2_item)
#剪枝
#先形成L1的itemset的set,用以剪枝,剪枝的方法是求出C2的itemset的k-1阶子集,和L1的keys(tuple->set)做交集,如果结果和C2相等,则不用剪枝
L1_set = set()
for i in range(0,len(L1_keys)):
L1_set.add(L1_keys[i])
#得到需要剪掉的set的list
need_clip = []
for item in C2:#item是set
C2_itemset_subset = set()
temp_tuple = tuple(item)#因为set不可遍历,所以将set转化为tuple遍历求temp_set的k-1子集
temp_set = item.copy()#因为要形成子集而且不能改变自己,每次形成子集后又恢复”父集”,所以用了中间变量用来重复修改生成子集
#得到C2的itemset的subset子集
for item2 in temp_tuple:#item2是int
temp_set.remove(item2)#set的k-1阶子集的集合就是每次移除一个元素
C2_itemset_subset.add(tuple(temp_set))
temp_set = item.copy()
if C2_itemset_subset.intersection(L1_set) == C2_itemset_subset :#如果子集都在L1中的话,就不用剪枝了(频繁集合的子集一定是频繁的这条规则)
continue
else:
need_clip.append(item)
#剪枝
for need_clip_item in need_clip:
C2.remove(need_clip_item)
return C2
#扫描
def scan(datum, C2):
C2_ = dict()
for datum_item in datum:
for C2_item in C2:
if C2_item.intersection(datum_item) == C2_item:
temp = tuple(C2_item)
if temp in C2_ :
C2_[temp] = C2_[temp]+1
else:
C2_[temp] = 1
return C2_
'''
datum = get_data_base("datumPpt.dat")
C1_ = get_C1_(datum)
L1 = get_L1_itemset(C1_,2)
C2 = connect_and_clip(L1)
C2_ = scan(datum,C2)
print(C2_)
'''
start = time.clock()
datum = get_data_base("retail.dat")
C1_ = get_C1_(datum)
L1 = get_L1_itemset(C1_,40000)#80000条数据,频数为1000条时,运行时间700s左右,4000条时3s左右
NUM = 1000
L_list = [None]*NUM
C_list = [None]*NUM
C__list = [None]*NUM
L_list[1] = L1#下标从1开始
for i in range(1,10):
if len(L_list[i]) != 1:
C_list[i+1] = connect_and_clip(L_list[i])
C__list[i+1] = scan(datum,C_list[i+1])
L_list[i+1] = get_L1_itemset(C__list[i+1],2)
else:
break;
for i in range(1,NUM):
if L_list[i] != None:
print(i,L_list[i])
end = time.clock()
print('Running time: %s Seconds'%(end-start))
欢迎在评论区中进行批评指正,转载请注明来源,如涉及侵权,请联系作者删除。

