一.ASCII码
世界上所有的信息存储在计算机中都是二进制010串,计算机由美国发展起来,所以美国对自己常用的信息进行了编码规范也就是ASCII码,1个字节的长度,最高位规定为0,其余7位可以表示2^7个字符也就是128个字符,比如常见的1——(0001 1111)2也就是3110,a——(0011 1101)2,也就是6110 。
二.Unicode
Unicode学名为 “Universal Multiple-Octet Coded Character Set” ,简称USC,有两种USC-2,USC-4。前者用两字节编码,后者用四字节编码。
但是随着世界的发展,其他国家也有存储自己本国文字信息的需要,拉丁文,汉字等也需要编码,所以相关组织考虑了ASCII码的基础上,将世界上所有的符号计划都用32位也就是四字节表示,可以表示100万以上个字符,人类世界足以,但是常用的不那么多,所以有16位双字节的Unicode标准(通常称作USC-2)和32位的四字节的Unicode标准(USC-4)。
通常我们见到的Unicode编码都是USC-2,下文中默认Unicode都为USC-2标准。
而为什么说是在ASCII码的基础上呢,因为如下图所示
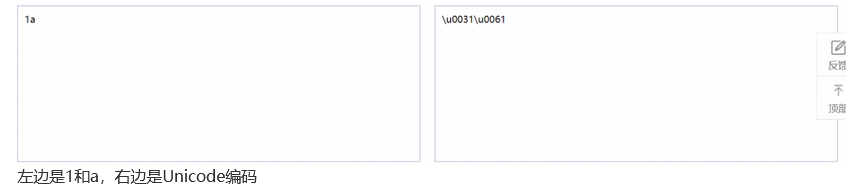
可以看到Unicode保留了ASCII的编码,只在高位扩展0而已。
三.UTF-8和UTF-16
UTF——Unicode 转换格式(Unicode Transformation Format,简称为UTF)。UTF-8是一种可变长度字符编码方式,以8-bit 为单元,使用1至4个字节为每个字符编码 ;UTF-16是一种可变长度字符编码方式,以16-bit 为单元,使用2个或4个字节为每个字符编码,UTF-16就是Unicode的常规编码。
已经有了Unicode编码方式,但是按照这样编码并且存储的话,每个符号都需要16位,但如果存储一些数据只需要用到很少的中文,拉丁文等,大量的都是英文(即用8位的ASCII码),也就是说,文件中将会有很多的0(因为ASCII码前面填充1个字节的0就是Unicode),文件体积就很大。
所以用变长编码的方式,减小文件大小,也就是说UTF-8按照Unicode的字符表示规定进行编码,但是做了存储优化。所以我们可以料想到UFT-8比UTF-16更好,因为最大化削减了能表示字符的比特位的位数。UTF-8最短8位,UTF-16最短16位就可以看出。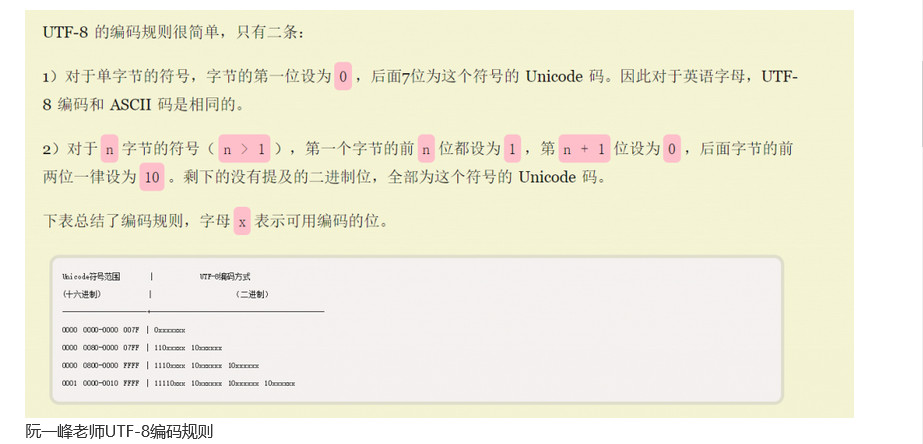
四.编码方式和实际存储
我们用TextPad填写1a,并且通过不同的编码方式(UTF-8,Unicode,Unicode(Big Endian)保存,如下图:
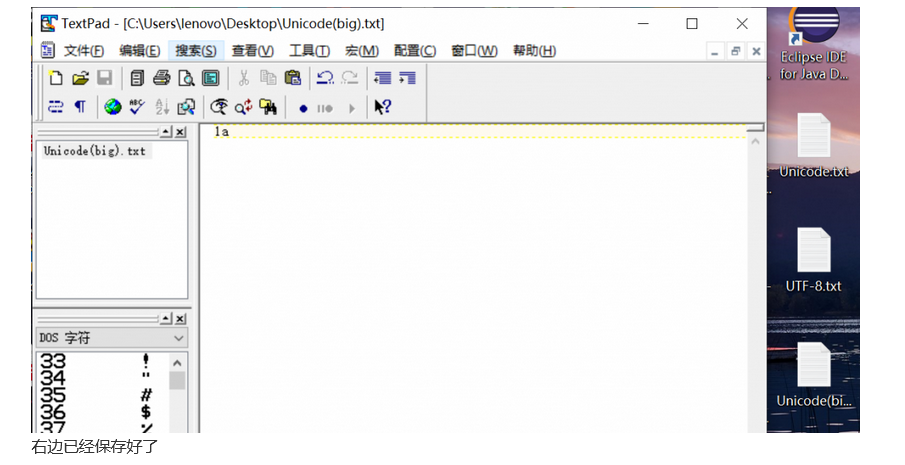
然后我们将他们用XVI32(查看文件的16进制实际存储)打开查看: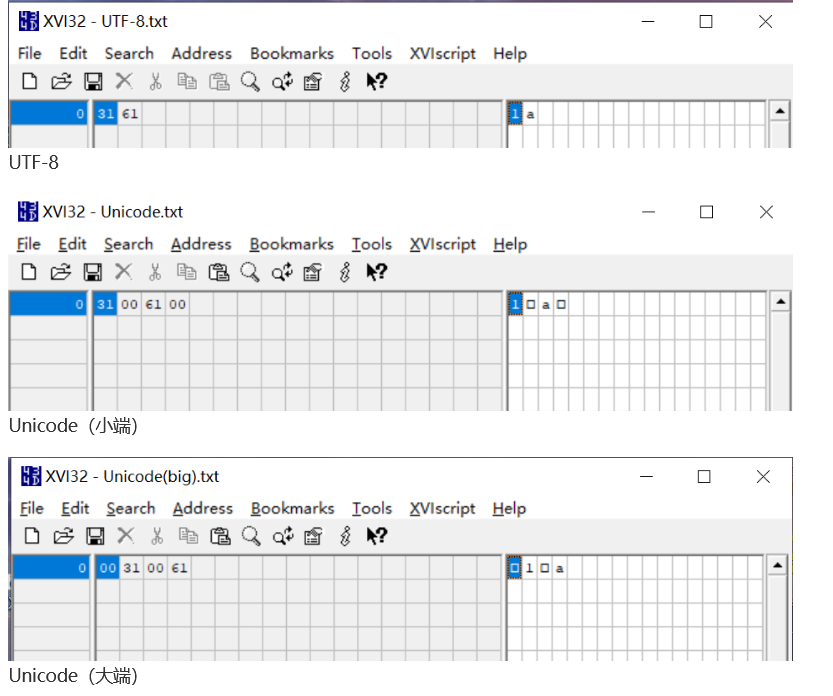
可以看到,我们用什么编码方式保存,实际的二进制位就保存为相应的编码表示,而大端和小端的区别就是,Unicode1a的编码是0031 0061,大端就保存为0031 0061,而小端保存为6100 3100。
五.编码方式和字符显示
我们经常遇到乱码的情况。
乱码就是,当作者输入了符号,然后按照A编码方式保存为文件File,而其他人收到文件后通过自己的查看器打开时,默认的编码方式是B方式,于是按照B方式解码,所以作者看到的和其他人看到的符号不一致的情况。
首先,作者我输入你好并按照UTF-8和Unicode保存成两个文件: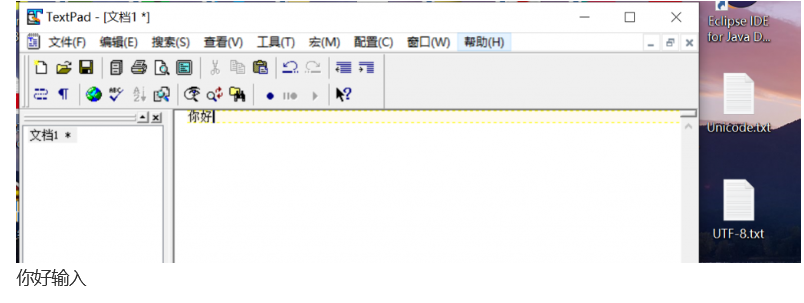
UTF-8存储,UTF-8显示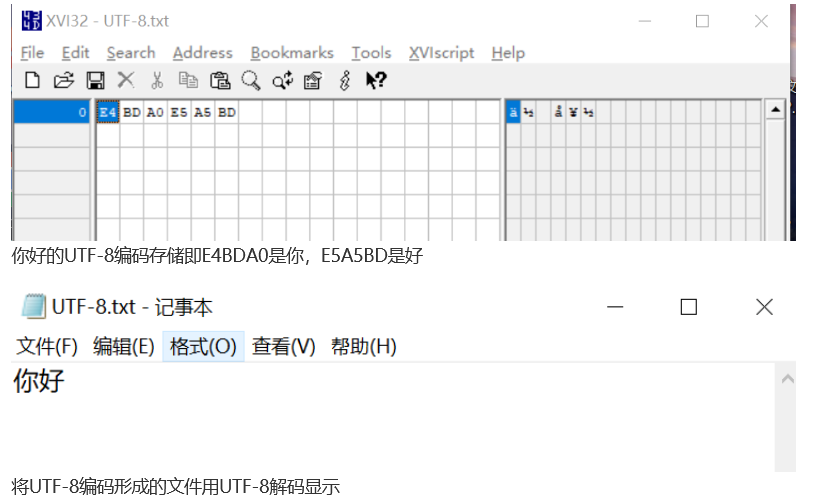
Unicode存储,UTF-8显示: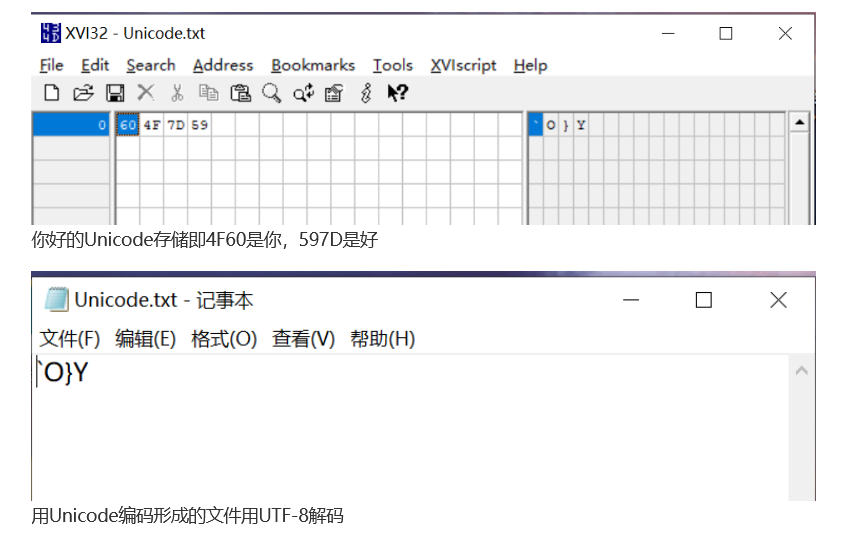
记事本的默认编码方式是UTF-8,所以我们打开记事本就是用UTF-8解码显示的过程。而XVI32软件的默认编码方式是ASCII,所以我们的Unicode编码604F7D59就被ASCII解码,4F对应的就是O,而59对应显示的就是Y。
六.参考文献
欢迎在评论区中进行批评指正,转载请注明来源,如涉及侵权,请联系作者删除。

