- \u开头和&#x开头是一样的,都是16进制Unicode字符的不同写法,而&#则是 unicode字符的10进制的写法.
2.爬虫返回的数据是,显然,其中&#是Unicode编码的中文,因为最终要全部编码为UTF-8上传到数据库中,所以要用正则匹配到这些串后,将他们转化为符号(UTF-8)存储,而非Unicode二进制串。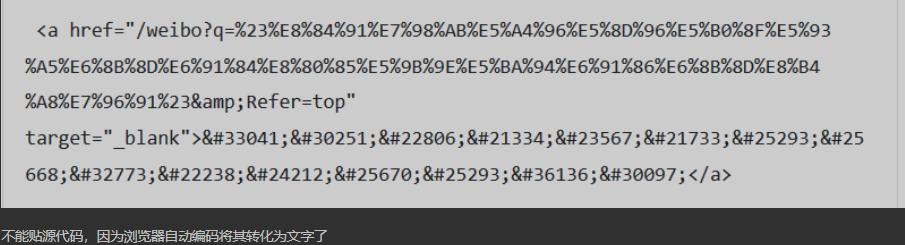
3.样例程序是这样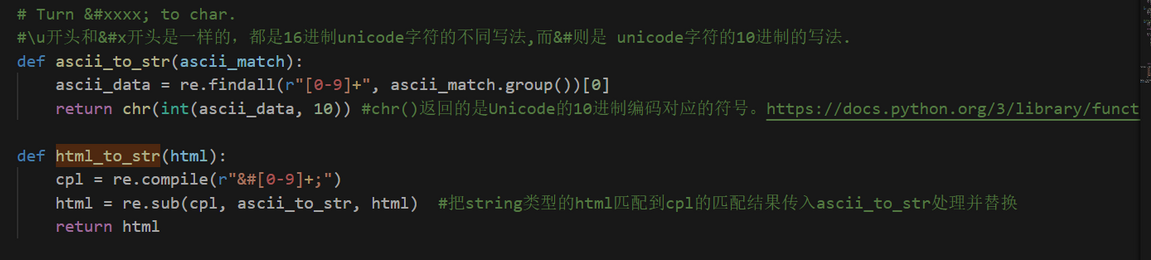
通过正则匹配到形如&#ddddd;的串,将&#和;去掉,然后把剩下的ddddd字符串转为10进制int型,然后用chr(ddddd)就可以转化为对应的符号了
4.也可以这样转换
5.参考
https://www.zhihu.com/question/21390312
https://www.jianshu.com/p/644cf8b6234a
欢迎在评论区中进行批评指正,转载请注明来源,如涉及侵权,请联系作者删除。

