简介
第1讲:深度学习介绍:主要是基础概念的介绍,快速过一遍。
第2讲:为什么训练网络会失败:主要是将训练网络的一些细节,局部最小值,鞍点,自适应学习率,损失函数等。这一讲的选修的梯度下降必看,新的优化器可以先不看,如果有余力可以看,主要讲了对梯度下降的一些改进。
第3讲:图像作为输入:CNN网络,必看,非常重要
第4讲:序列作为输入:先看选修的RNN,再去看自注意力机制,不要搞错顺序。因为注意力太火了,所以RNN放在了选修,不过我认为还是要先看RNN模型基础,再去看自注意力机制,为下面额Transformer模型做准备。选修中的GNN网络,可以你自己的需求,入门阶段可以先跳过不看。
第5讲:序列到序列:主要讲了Transformer模型,必看,选修的指针网络可以先不看。
第6讲:生成模型:主要是对GAN理论的介绍。看你自己研究方向,如果是GAN方向的,可以细细看下,如果入门选手,直接跳过。
第7讲:自监督学习,必看,很火。主要看关于BERT介绍相关的视频,比如模型介绍,微调,预训练等。BERT的各种变体比如Spanbert等可以先不看,同理GPT有余力就看,没余力直接跳过,不影响。
第8讲:自编码,可以先不看,取决于你的自己研究方向。
第9,10,11,12,13,14,15讲,入门阶段可以先不看【取决于你的自己研究方向】,偏理论。入门之后,再来看.
学习材料
学习日志
2022/07/08以前
在bilibili ipad上面看第一节, Colab教学, pytorc教学等.
2022/07/08 60’
重新整理资料, 建立md文件, 整理进度
2022/07/28 180’
第2讲
机器学习任务攻略
局部最小值与鞍点
批次batch和动量momentum
2022/07/29 1day
第3讲
第4讲
教学
第1讲 基本概念
机器学习基本概念简介
第2讲 基础知识
机器学习任务攻略
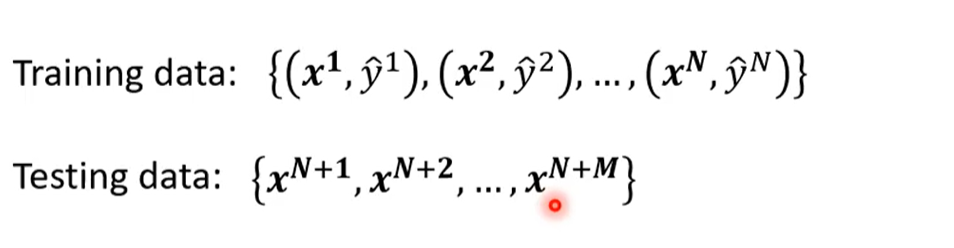
机器学习的框架:
- 找一个函数, $\theta$ 是未知的.
- 定义一个损失函数
- 最小化损失函数来更新 $\theta$
更新baseline的选项:
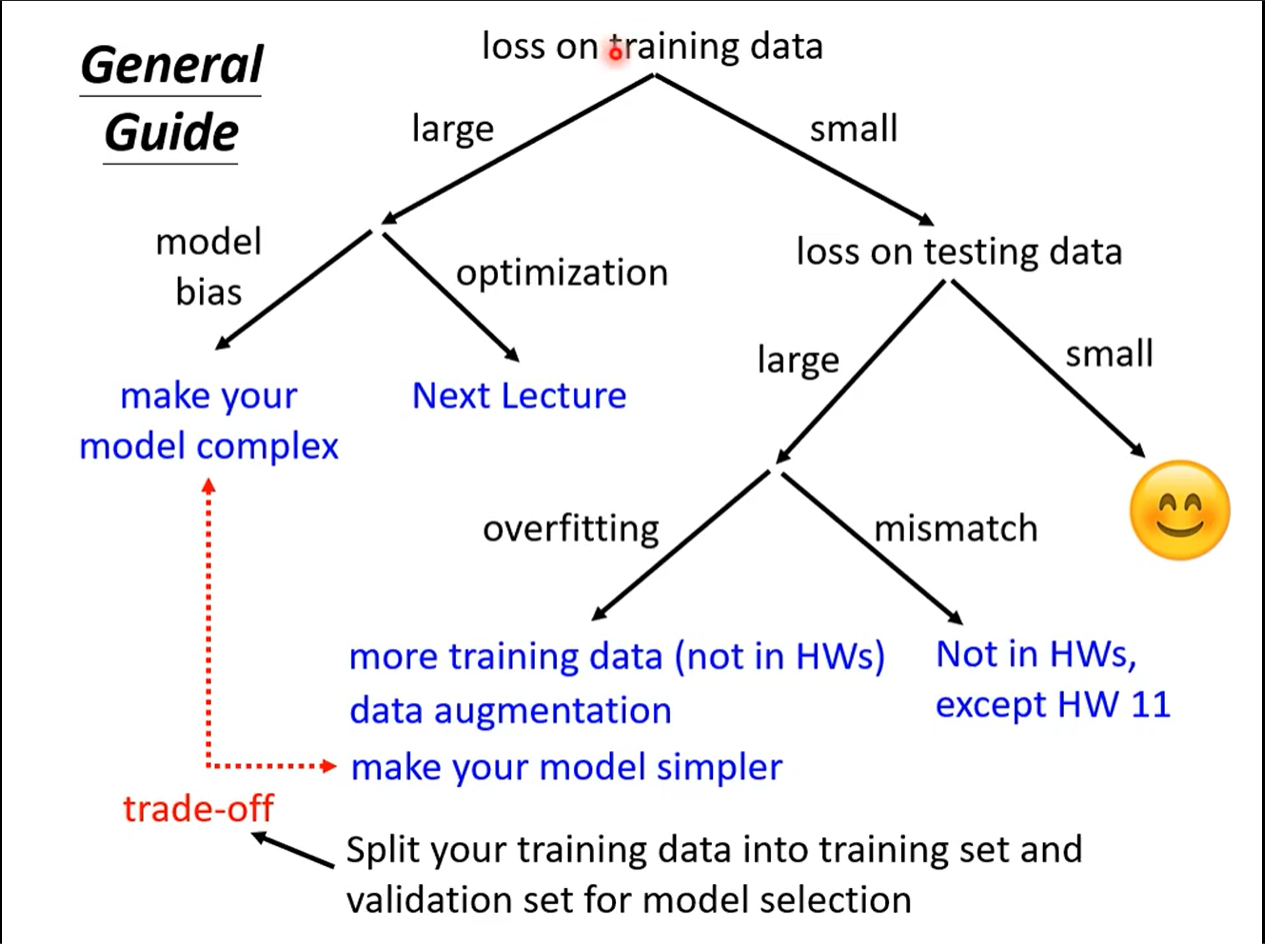
先检查traning data上面的loss, 如果很大的话说明就是在训练阶段就没学好.
Model Bias
更改模型函数的结构, 将模型设计的更加复杂.Optimization Issue
如果更深的网络的loss反而增大, 是Optimation的问题.
已经降低了traning data上面的loss
查看testing data上的loss, 如果很小就可以了
但是如果很大, 此时有可能就是overfitting的情况(traning data loss大. test data loss小)
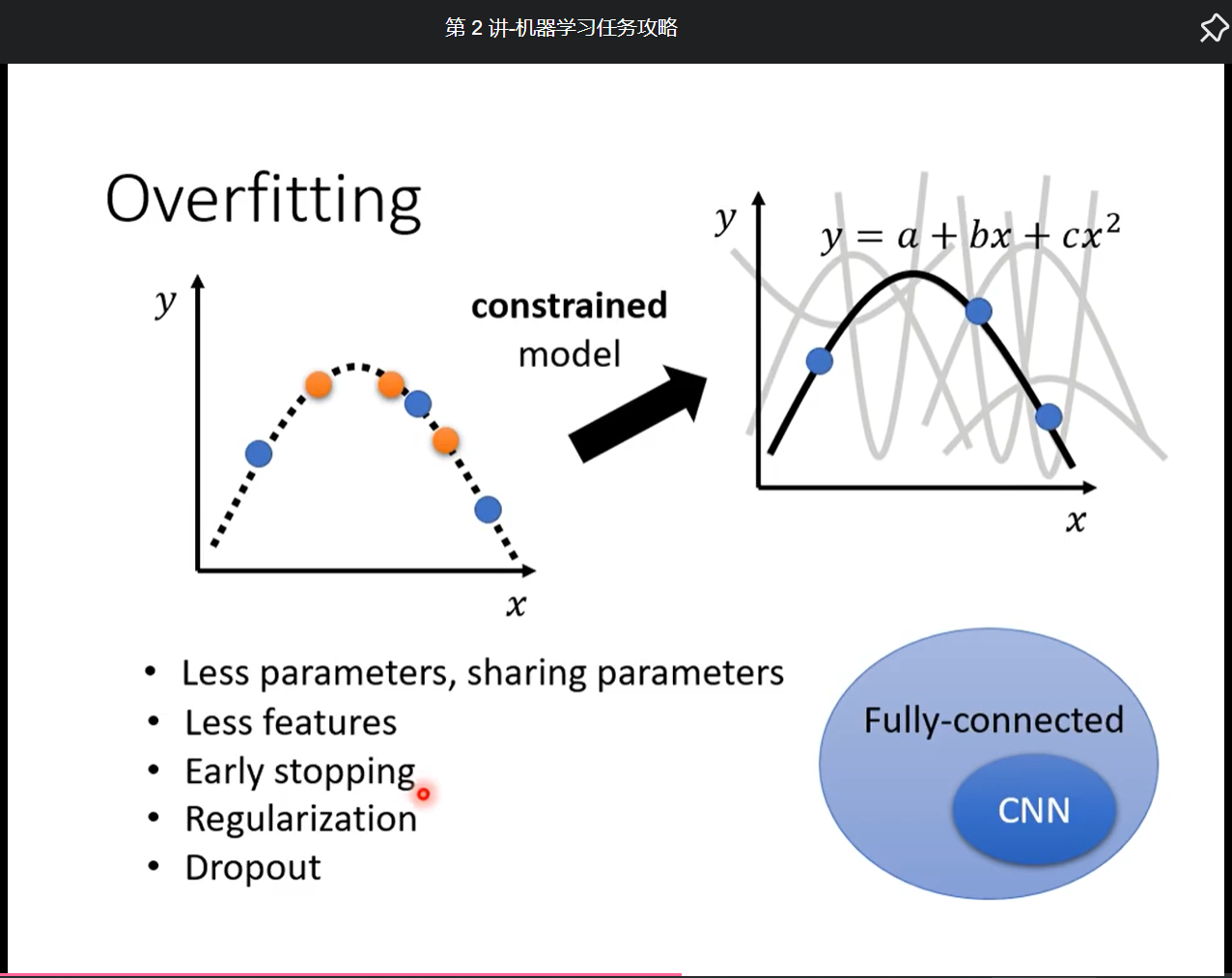
解决方法:
- 增加训练数据,
- 可以做data augmentation(反转, 变大, 但要合理不太能旋转180°),
- 给模型进行限制, 比如比较少的神经元, 共用参数(CNN就是一个没有弹性的网络), dropout, 但是也不能限制的太死, 否则就会上升为model bias.
所以需要在复杂模型和简单模型选择一个训练数据和公开测试数据上的loss都很小的一个模型.
那能不能选择一个public tranning set 的loss最小的函数呢?
不行, 因为有可能那个模型函数就是恰巧在public tranning set上面loss最小而已. 如果所有的test data都是public的话, 那就可以用直接输出test data欺骗程序了.这也就是可以在benchmark corpora上超越人类的能力.!
所以需要把test data 分为training data 和 validation data, 然后用validation data调优, 然后上传到public testing data查看分数. 最后的private testing data才可以有好的分数.
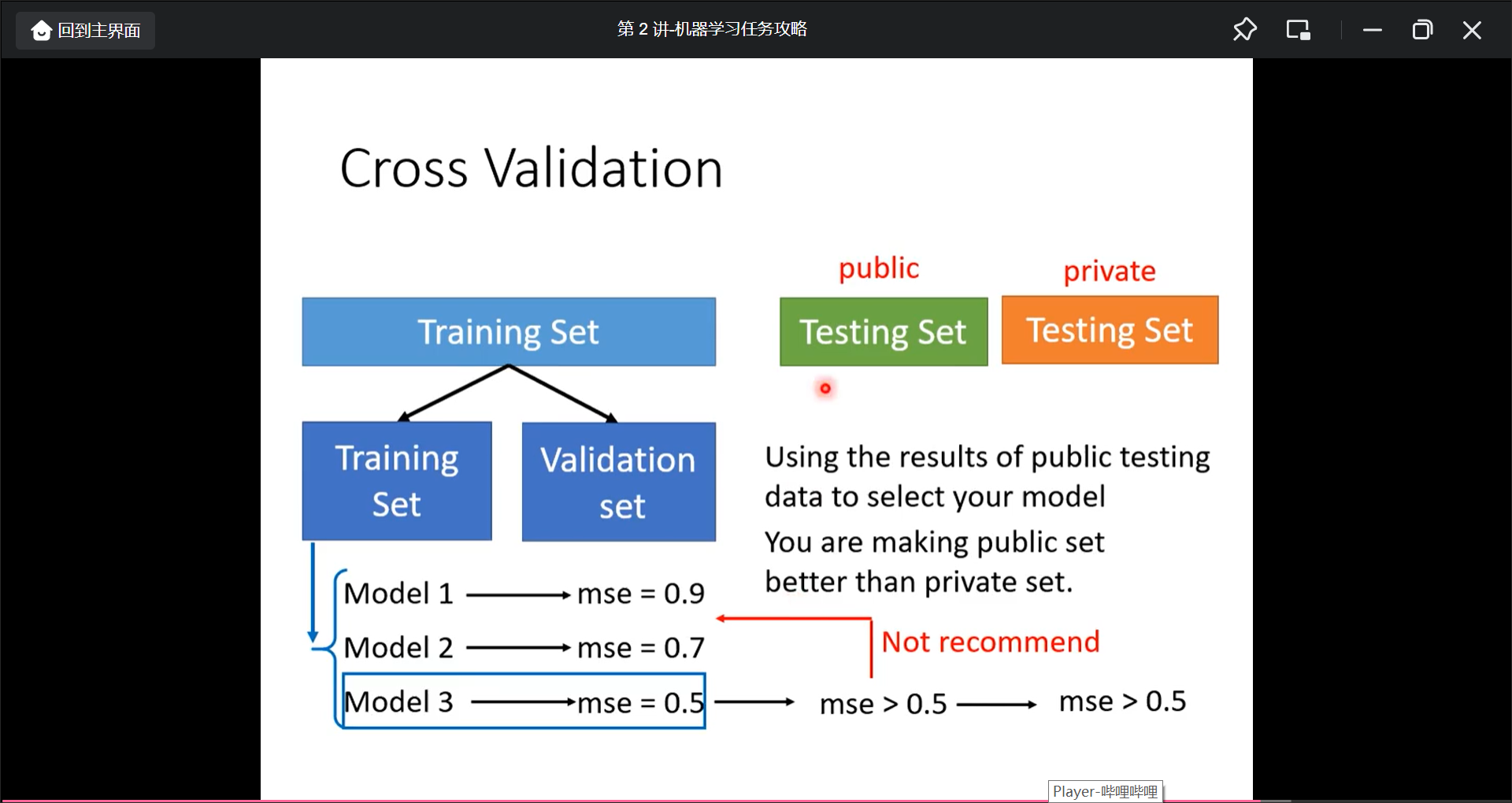
理想中用validation data mse最小的就好了, 老师说越少看public test data的分数越好.
而如何划分traning set和validation set呢
用N-fold cross validation的方法:

周五的数据进行了峰值是因为mismatch
就是预测数据的分布和训练数据的分布不相同. 辨别是否是mismatch则需要作者进行判断.
局部最小值与鞍点
本节讲optimization失败的怎么办.
当训练loss下降不下去了(微分为0)但是还比较大是什么情况
- local minima(局部最小值)
这种情况无路可走 - saddle point(鞍点)
但是这种情况再挑一个方向还可以再优化.
那如何判断是局部最小值还是鞍点呢?
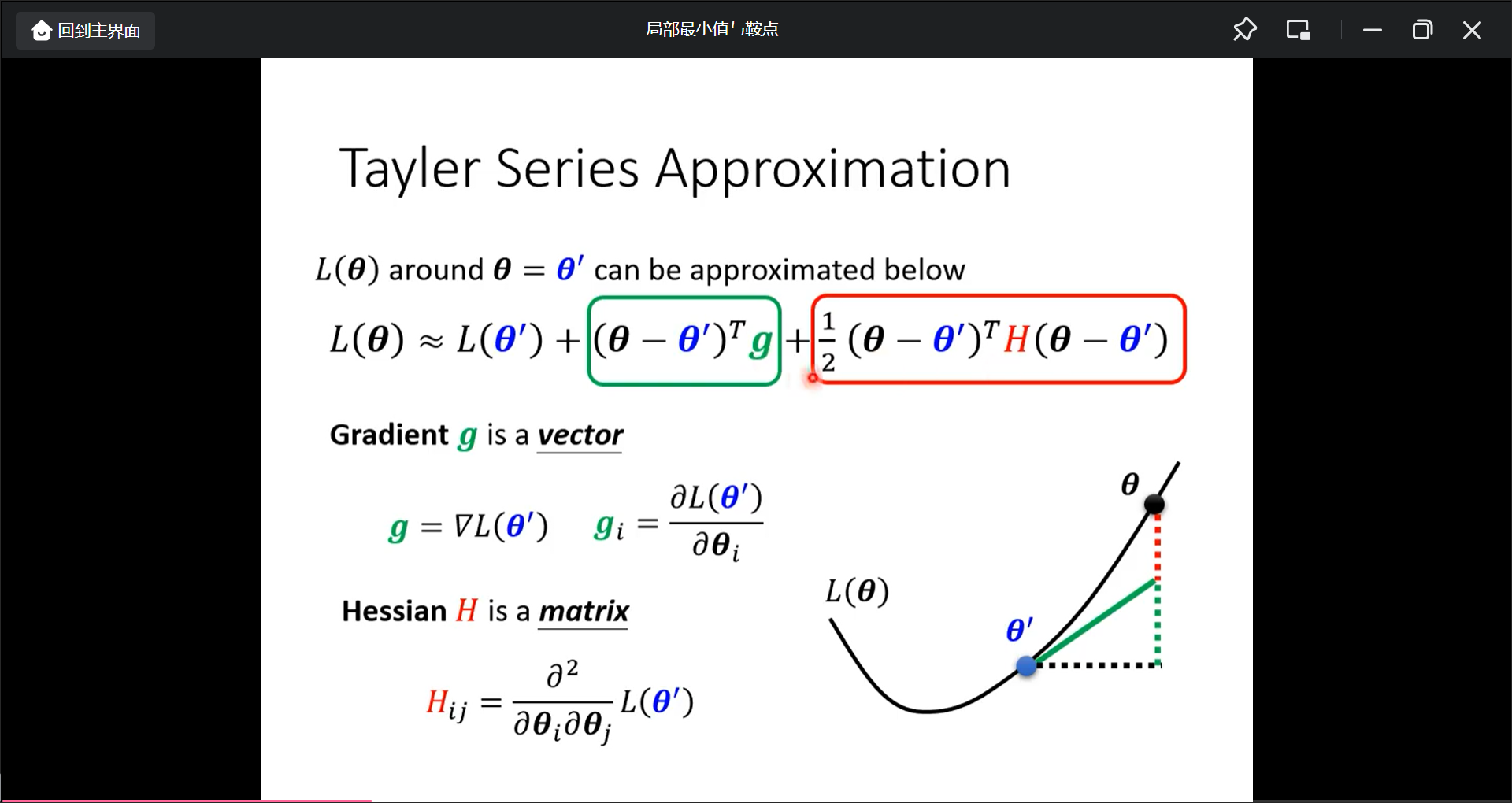
可以用后面的红色部分来判断是error surface 大概什么样子
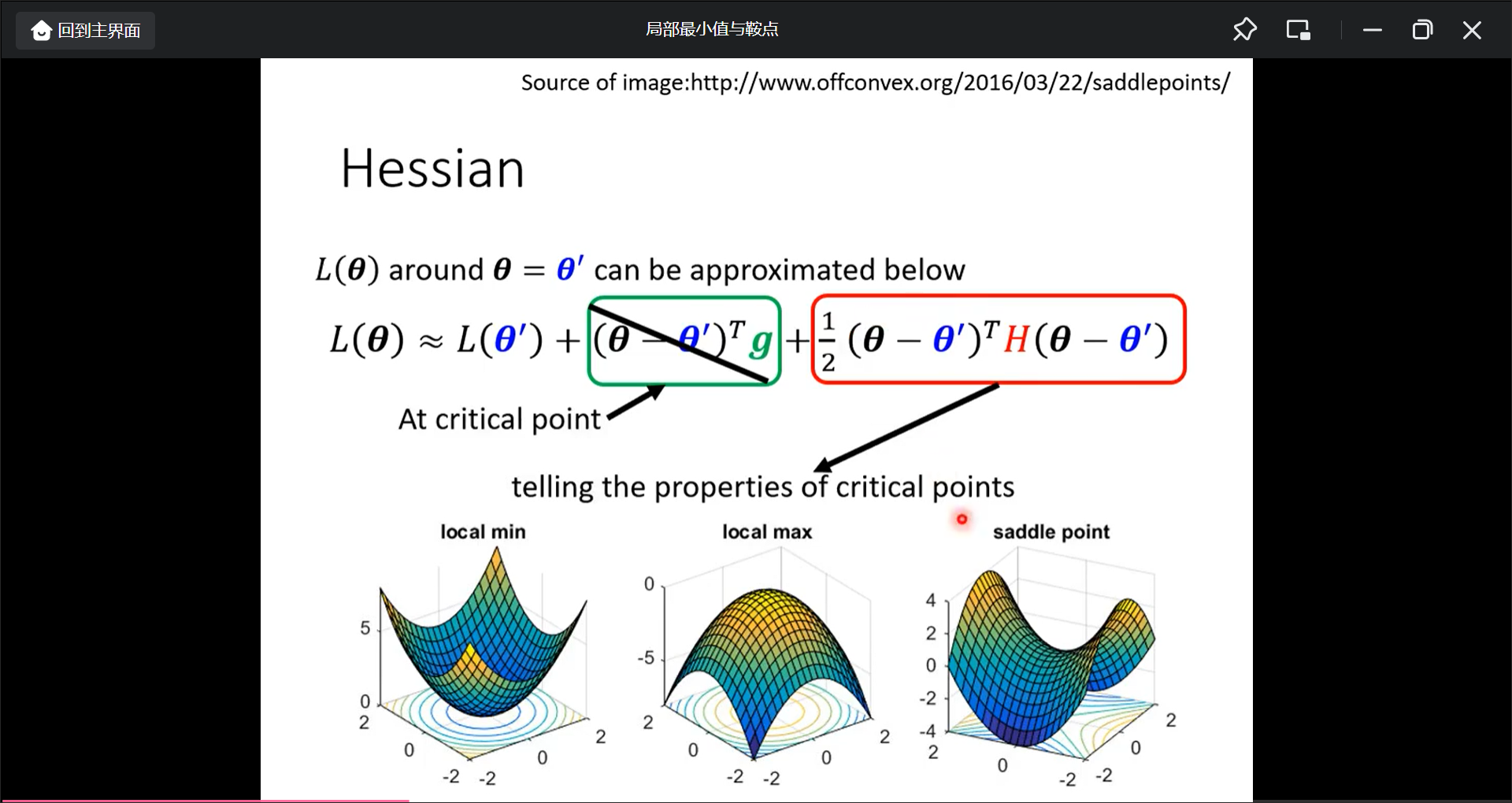
一个结论是用H矩阵的正定性来判断:

举一个例子
把所有w1和w2穷举, 然后得到loss之后画出error surface
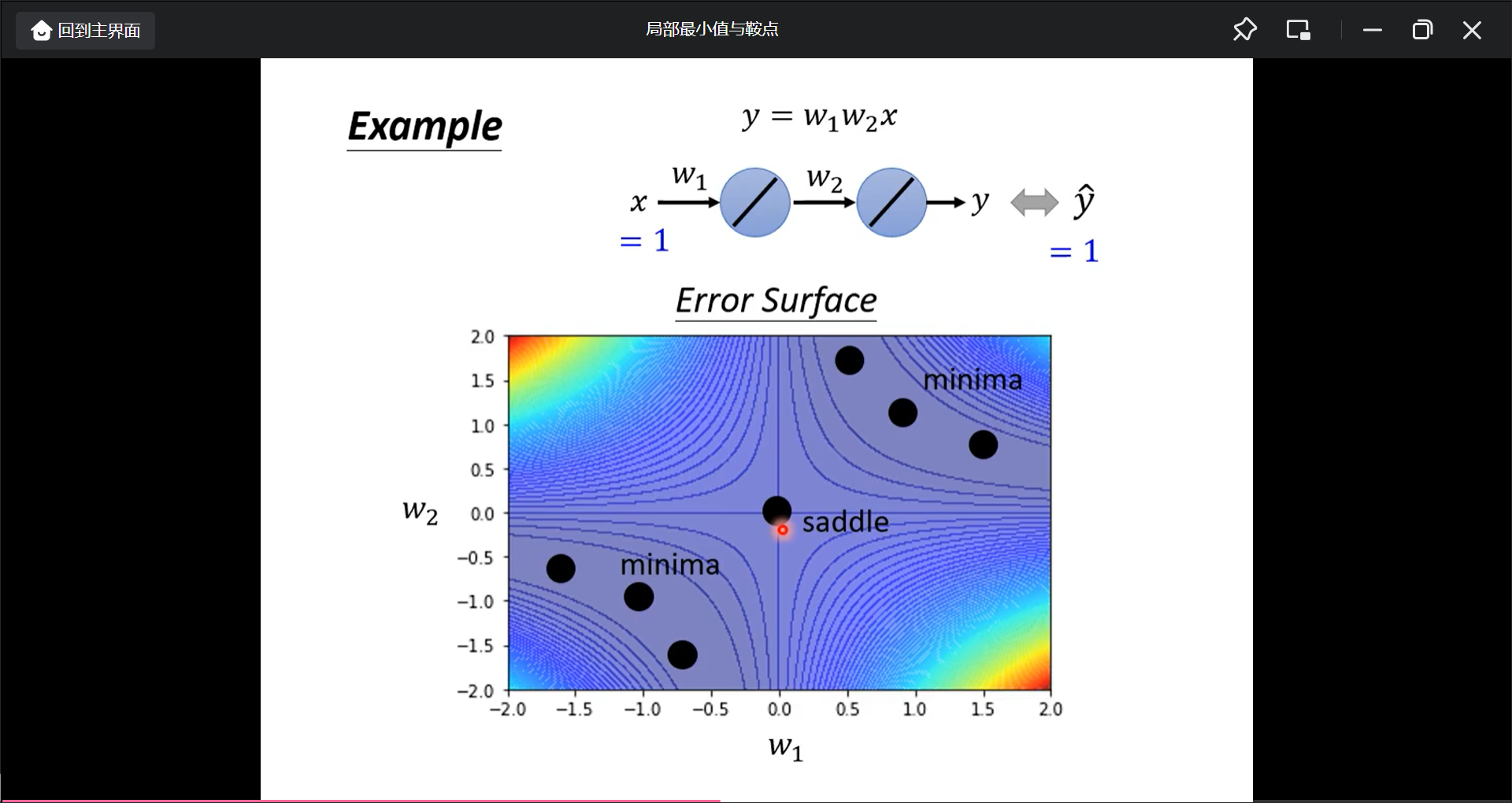
那如果不穷举呢?
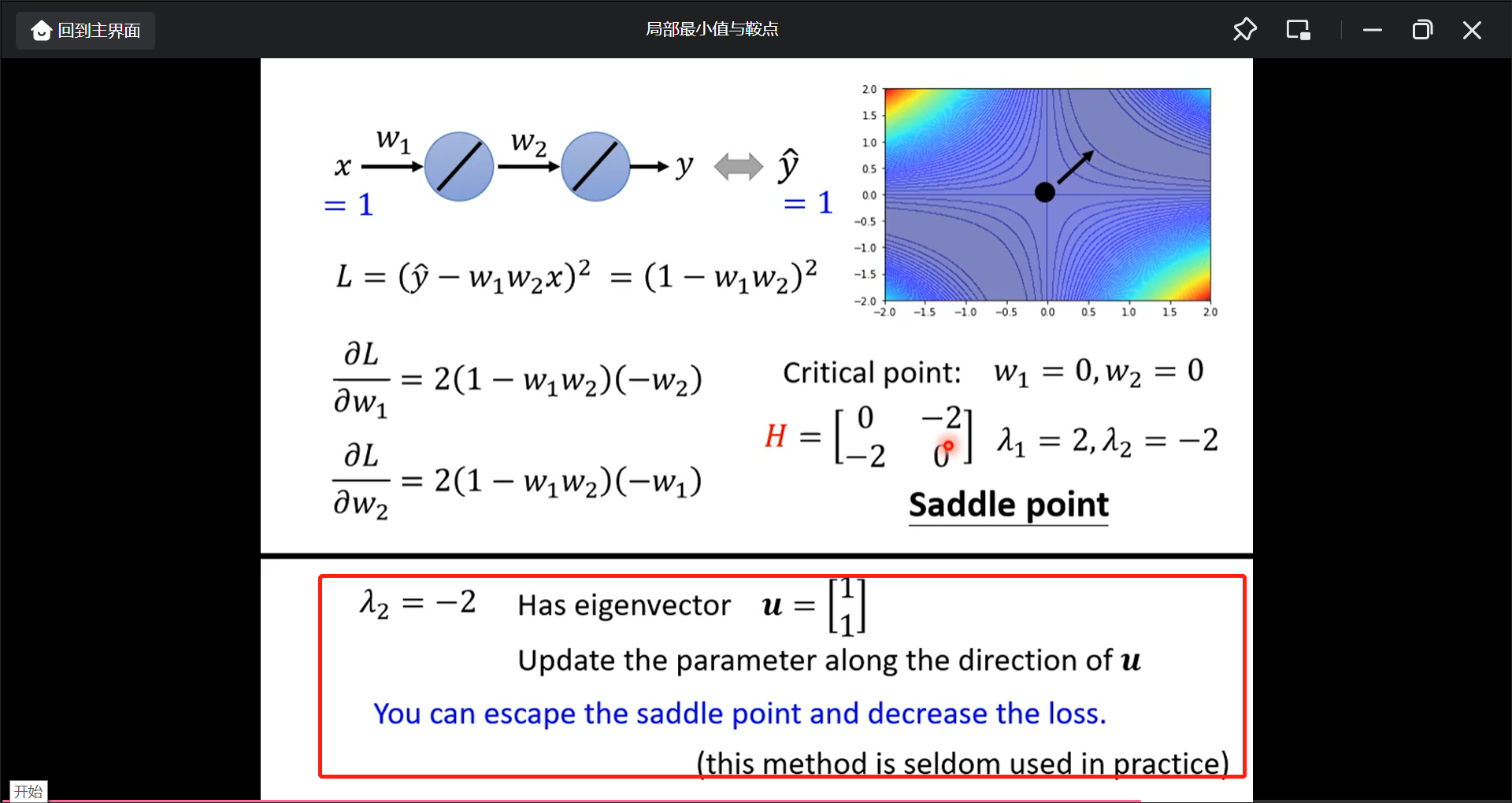
先计算一次微分g, 带入点对应值w1,w2, 看是不是critical point, 然后计算二次微分Hession, 算Hession矩阵的特征值的正负:
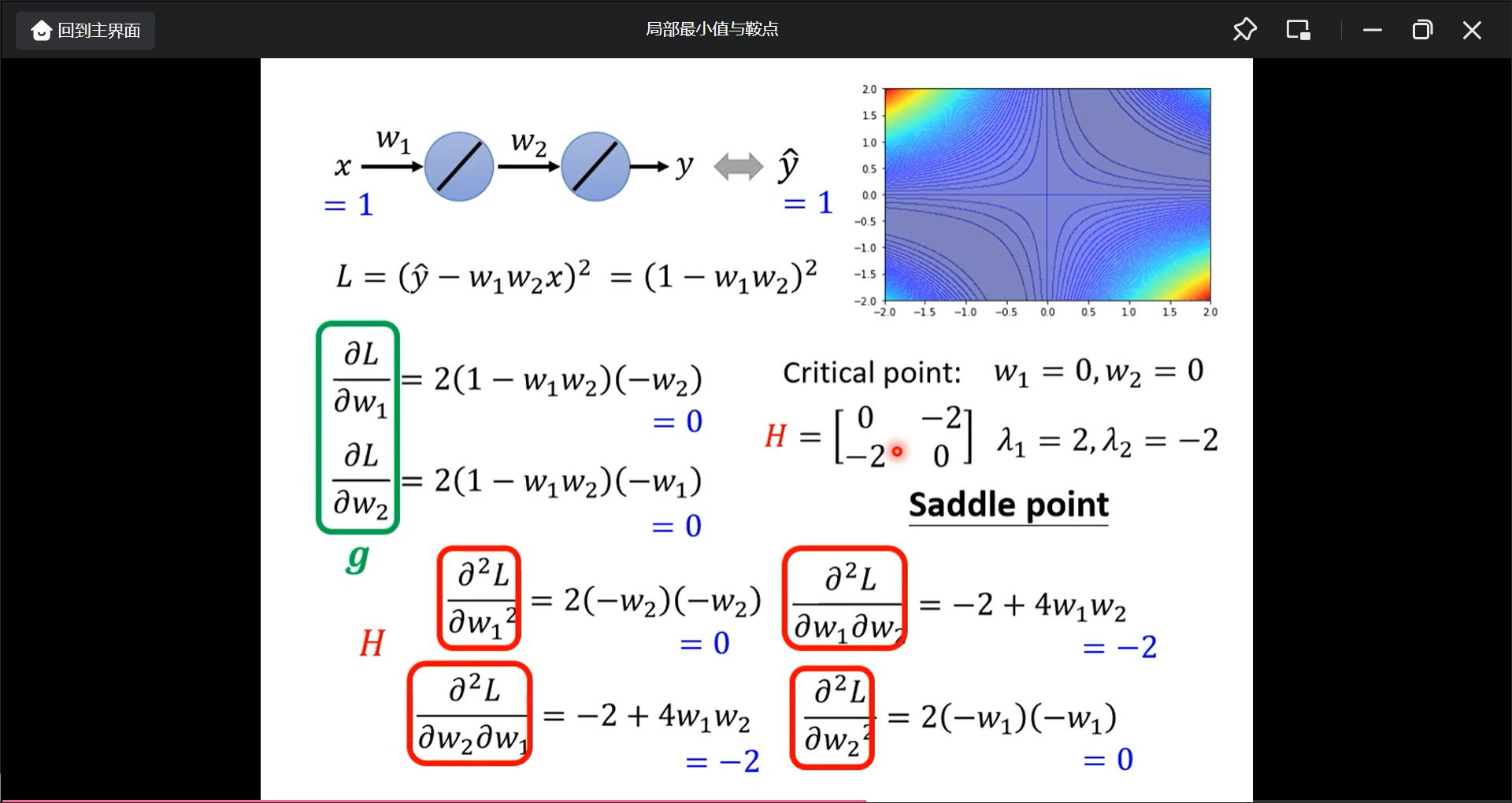
如果是saddle point的话, 这时候gradient就是0, 所以就用H(特征值和特征向量)看:

那么saddle point和local minima哪个更常见呢?
低维的最小值点从更高维看也许就是鞍点, 所以在实际中哪个更常见呢?
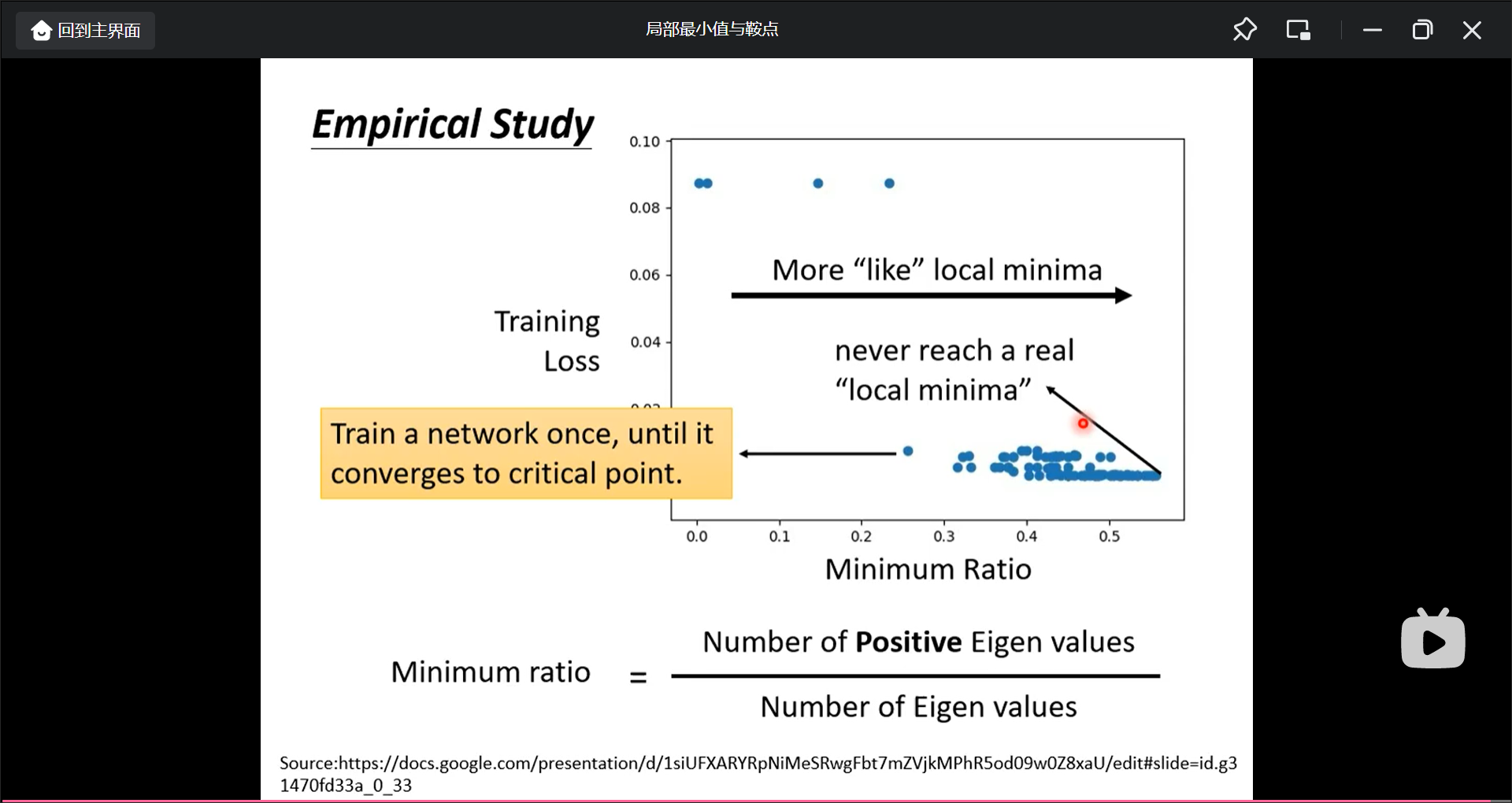
从图中看, 没有一个真正的局部最小点, 所以一个模型优化的过程是这样的:
批次(batch)和动量(momentum)
shuffle在每一次训练好都会重新划分一下batch
small batch vs large batch
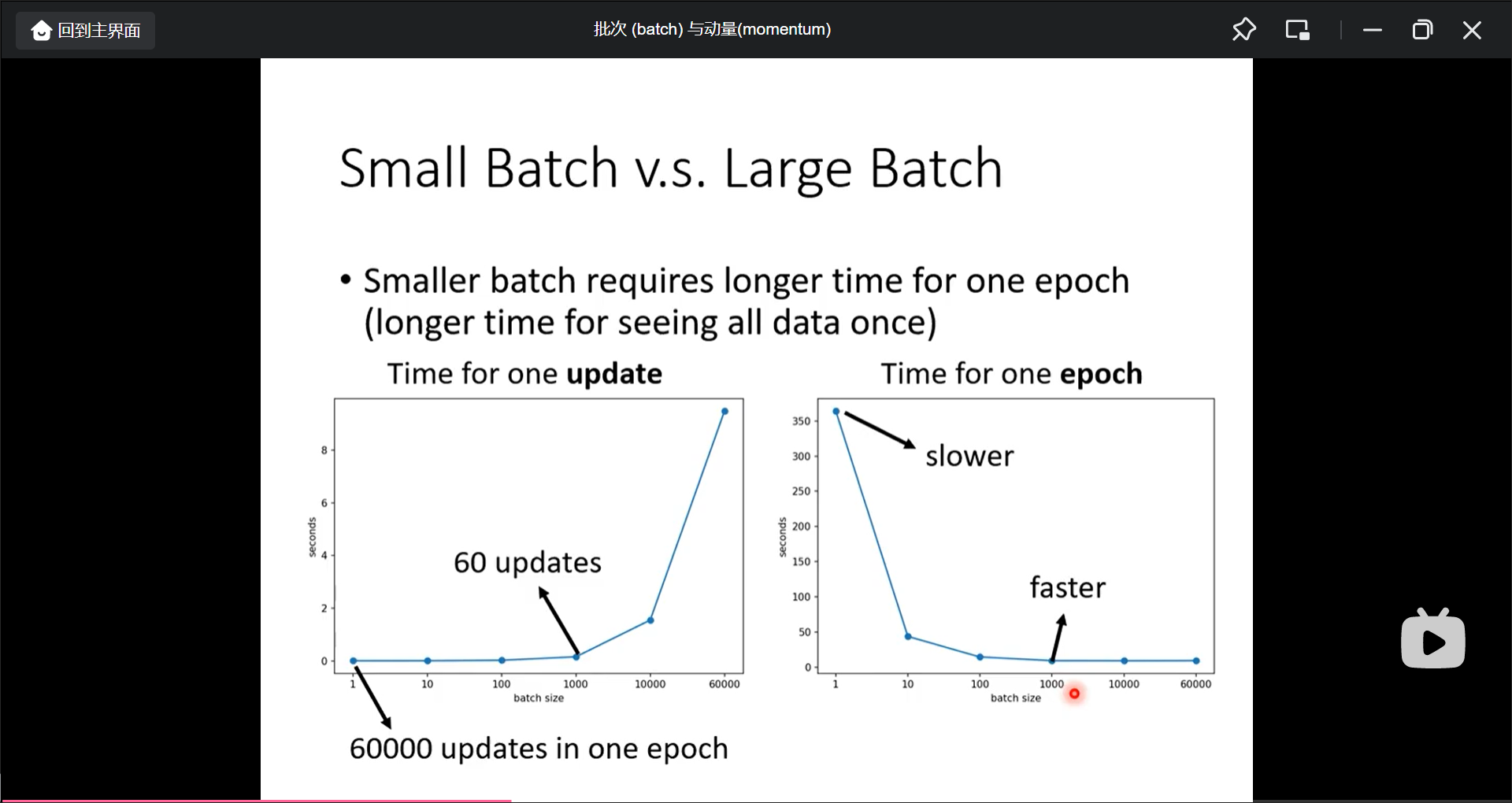
small btach的loss计算的值小, 更新的次数多
large batch的loss计算的值大, 更新的次数小
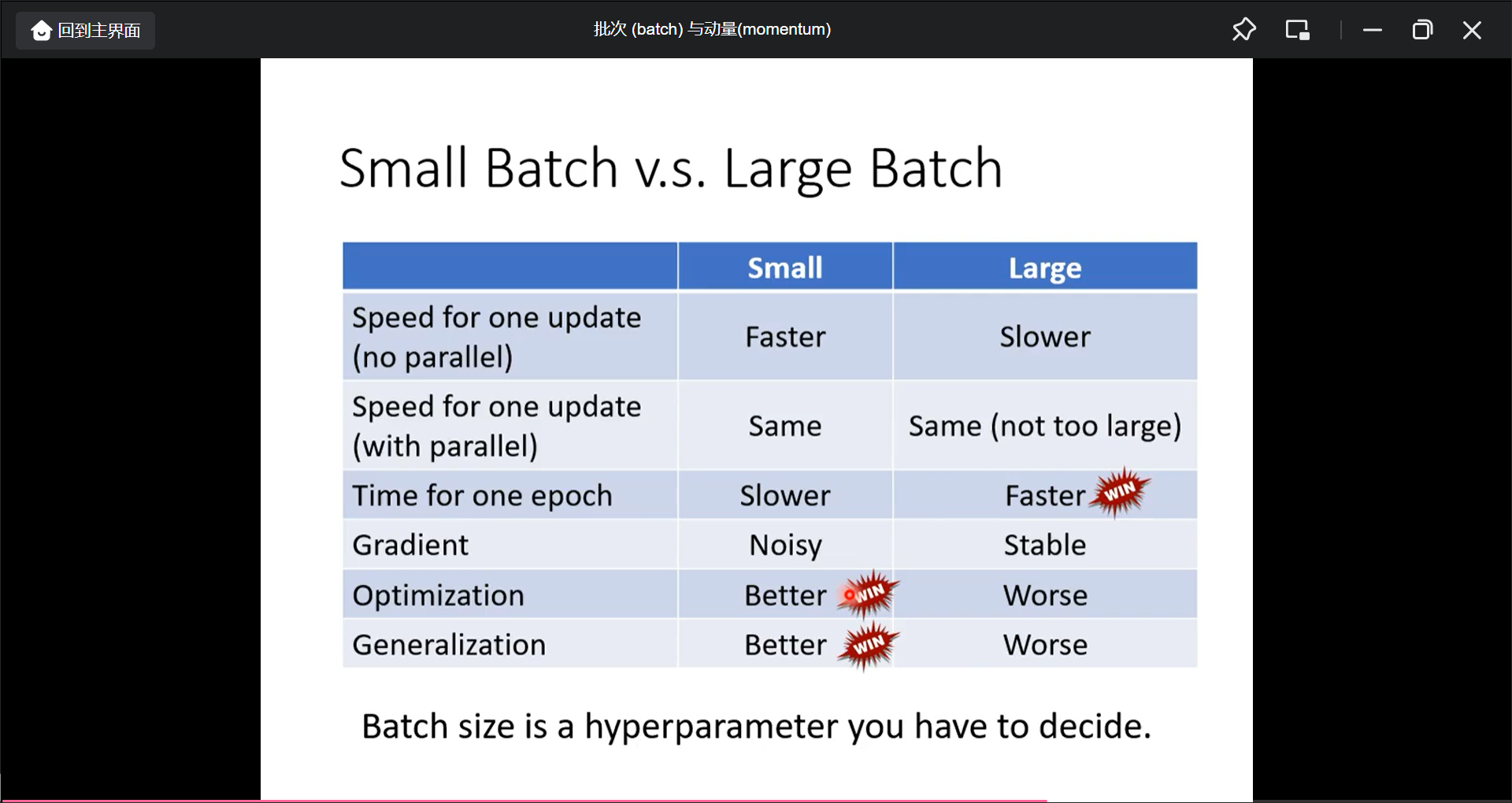
但是不一定large batch计算loss时间长, 因为有平行计算, 另外因为update不能平行计算, 所以小batch的update次数多, 一个epoch反而时间更长, 所以大batch反而更快.
快不一定意味着正确率就高, 小batch反而正确率更高:
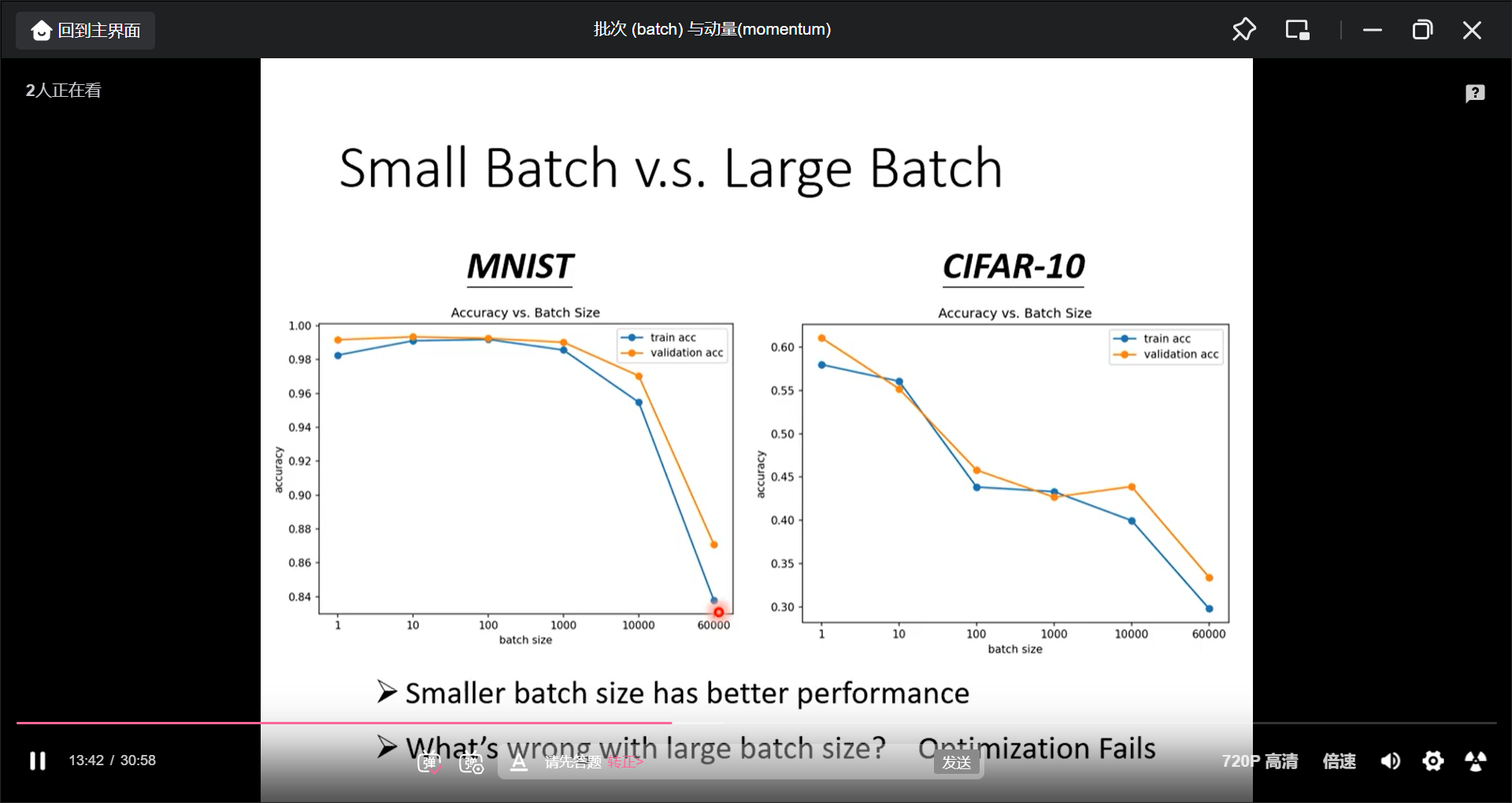
可能的原因是小btach的loss函数有点细微的差异, 所以可以不被卡在critical point.小batch对testing data反而更好
比如把大batch和小batch的准确率都训练的同样好, 但是小batch在testing 更好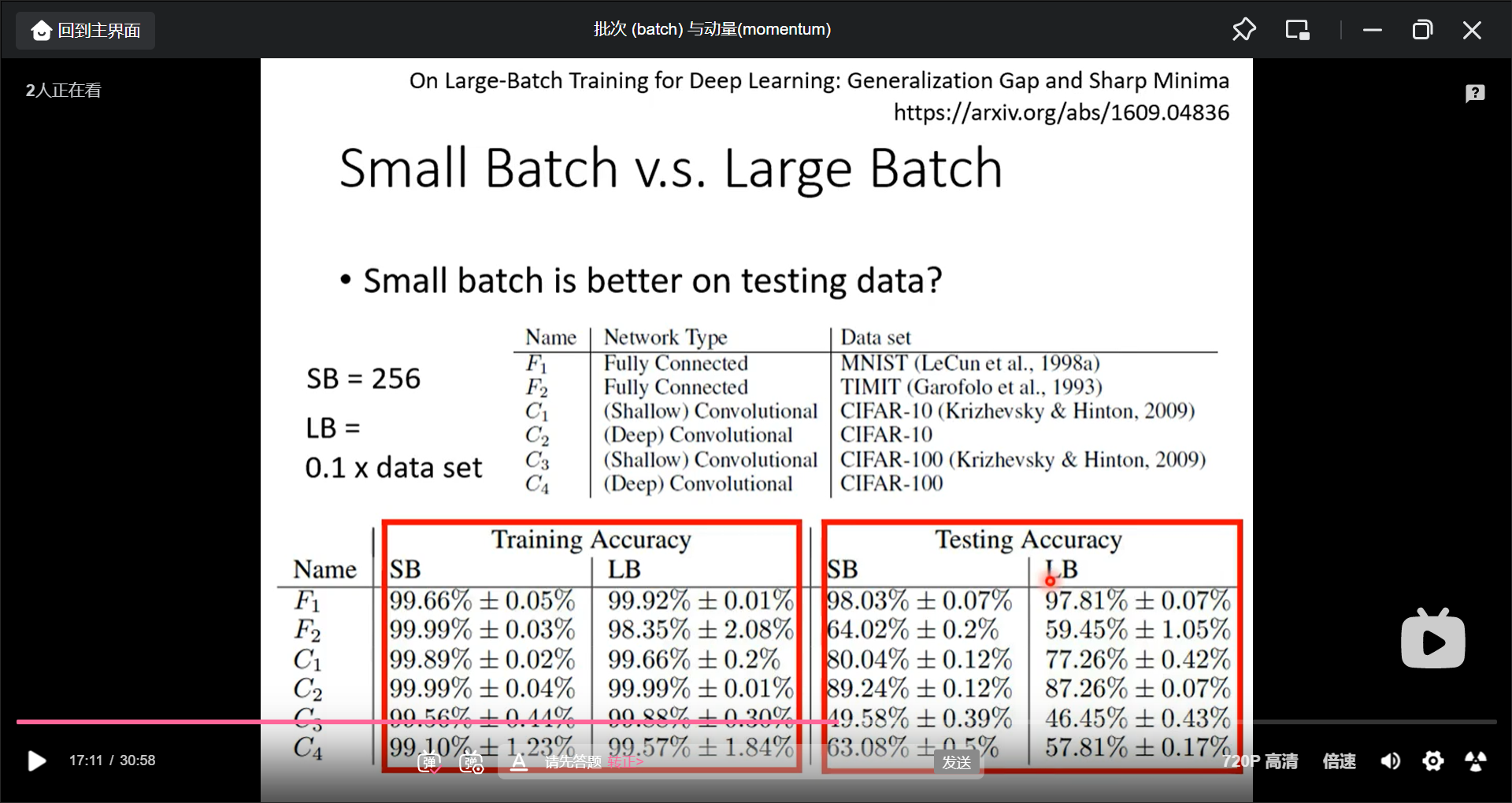
这种情况的一种可能原因是minima也有好坏之分, flat minima 和 sharp minima.
总和来看:
另一种解决局部最小点的方法是叫做momentum:
移动的方向是梯度反方向+原来方向的组合: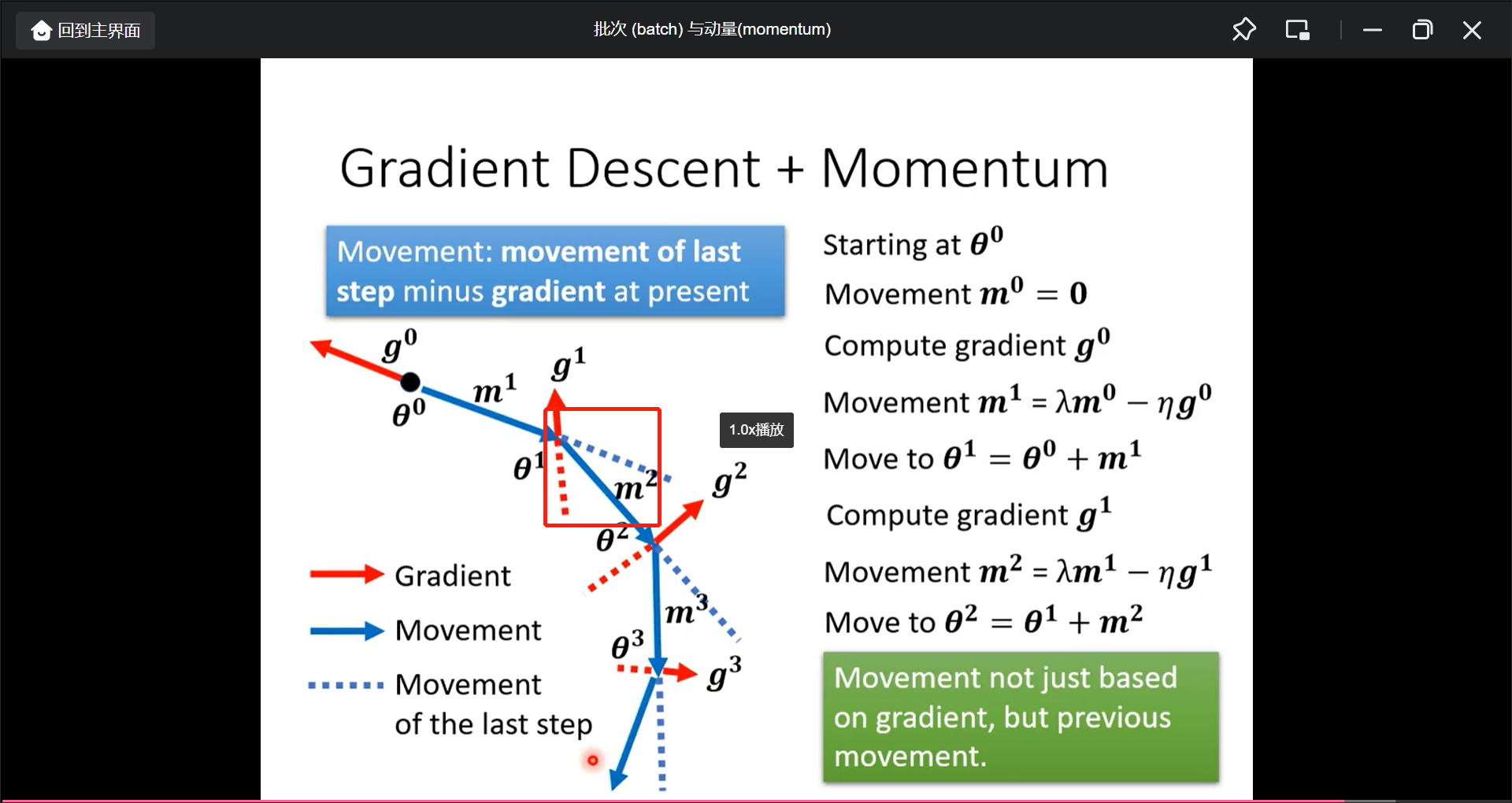
如果带入式子的话, 另一种解释方法是, 现在的移动方向考虑之前移动方向的总和:
vanilla是一般的意思
自动调整学习速率(Learning Rate)
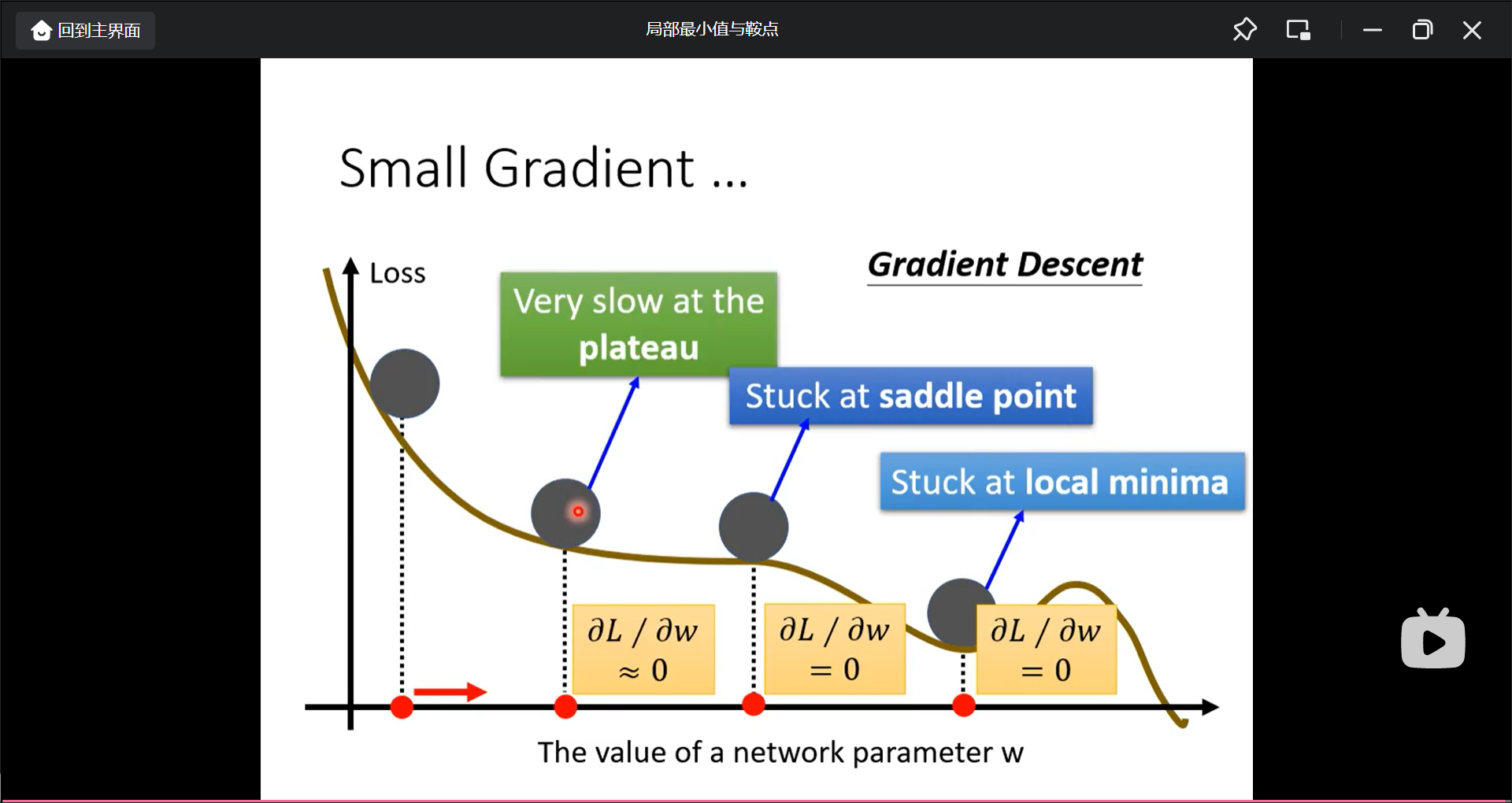
当loss不再更新的时候, 第一反应是gradient为0了, 但是真得一定吗, 但是有一种可能是gradient不为0, 但是是learning rate太大了.
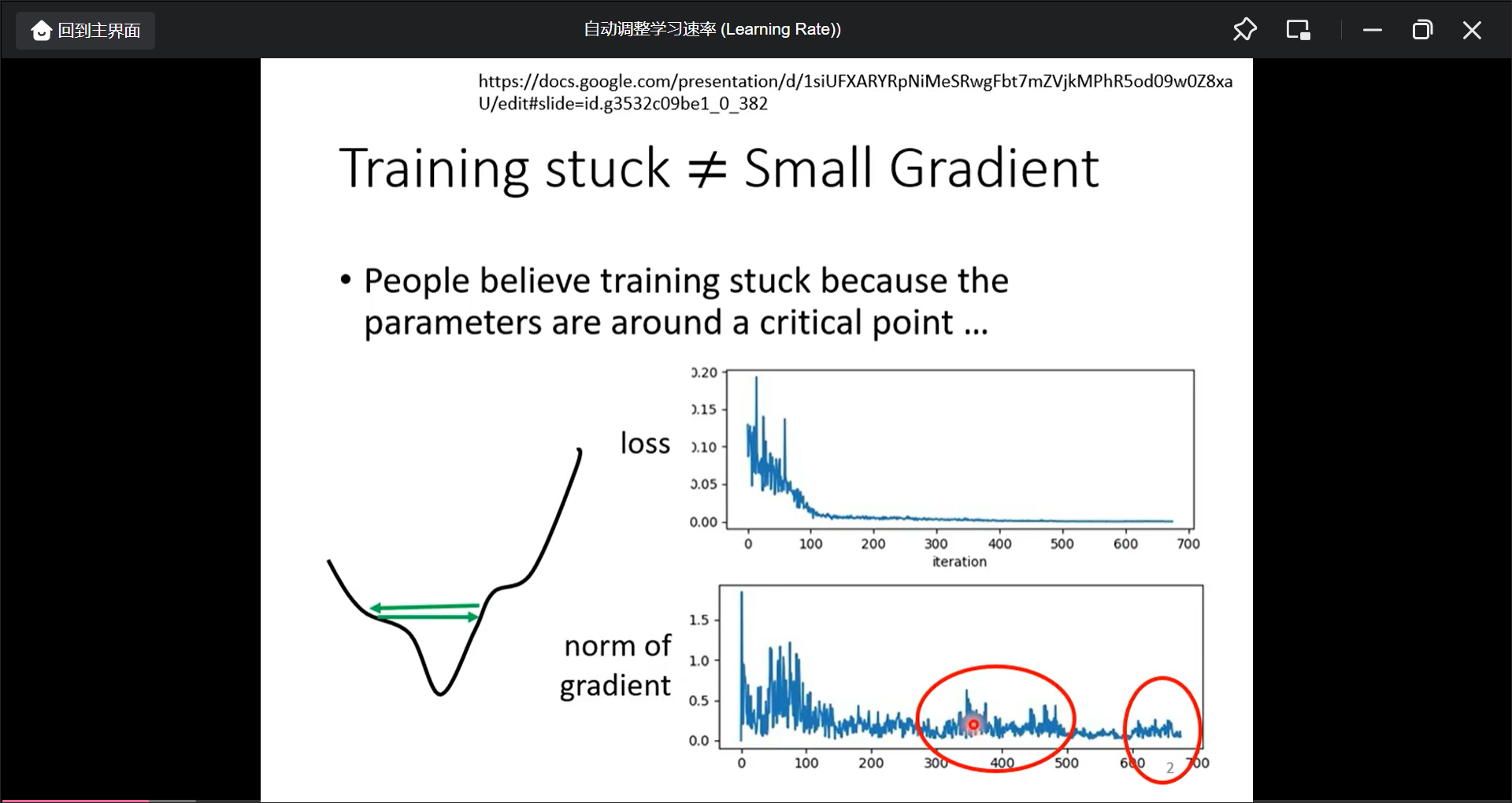
用一般的gradient decent很难达到local minima, 所以对于不同的参数需要不同的learning rate(而不是原来的固定的learning rate).
比如一个变化的学习速率例如(为了在g不同的时候有不同的learning rate):
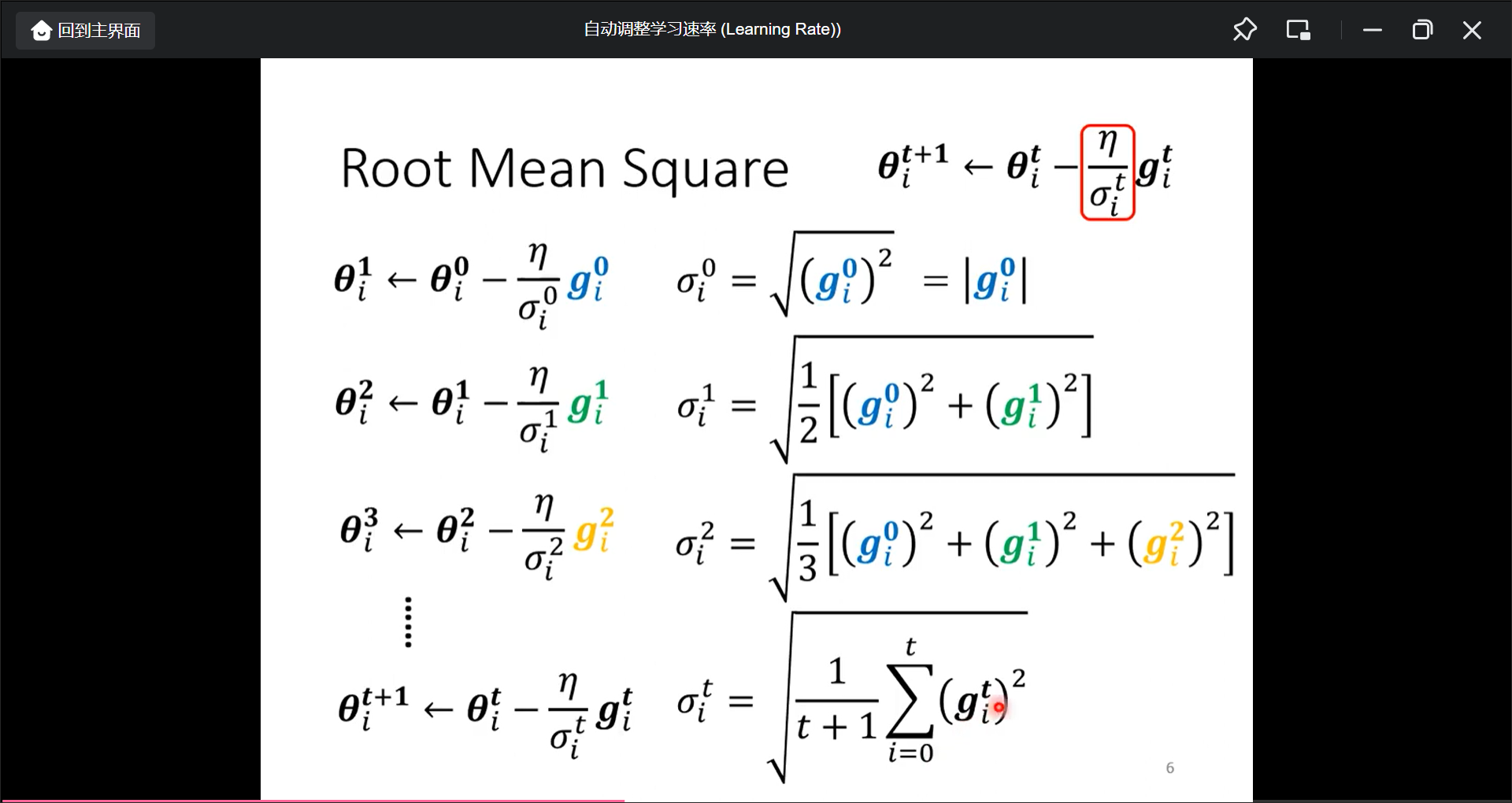

最常用的策略(optimazation)就是Adam=(RMSProp+Momentum):

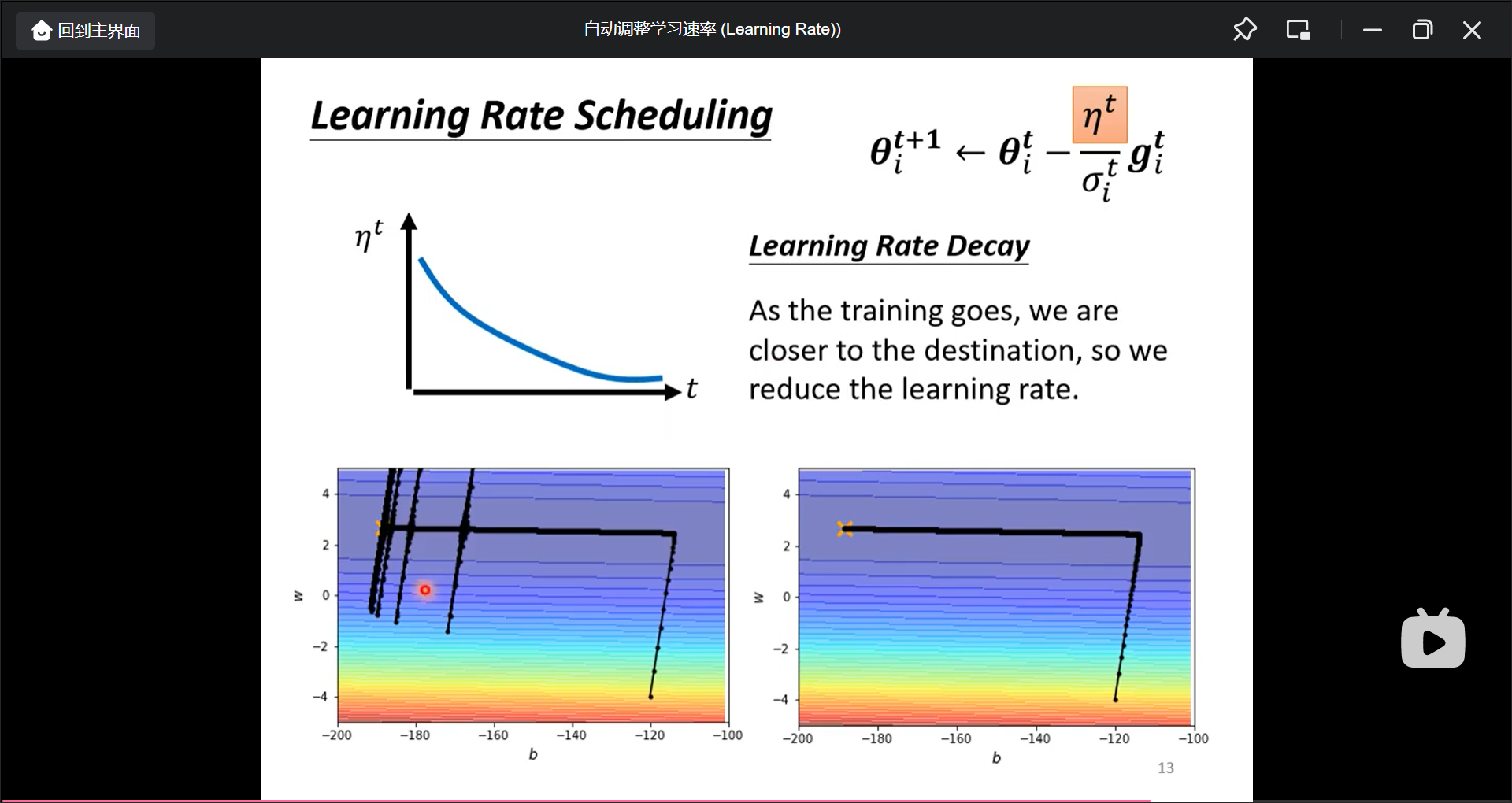
还可以对$\eta$加时间的变化(Learning Rate Decay), 越来越小:
在BERT和Transformer的时候用了这种变化(Warm up), 先变大再变小):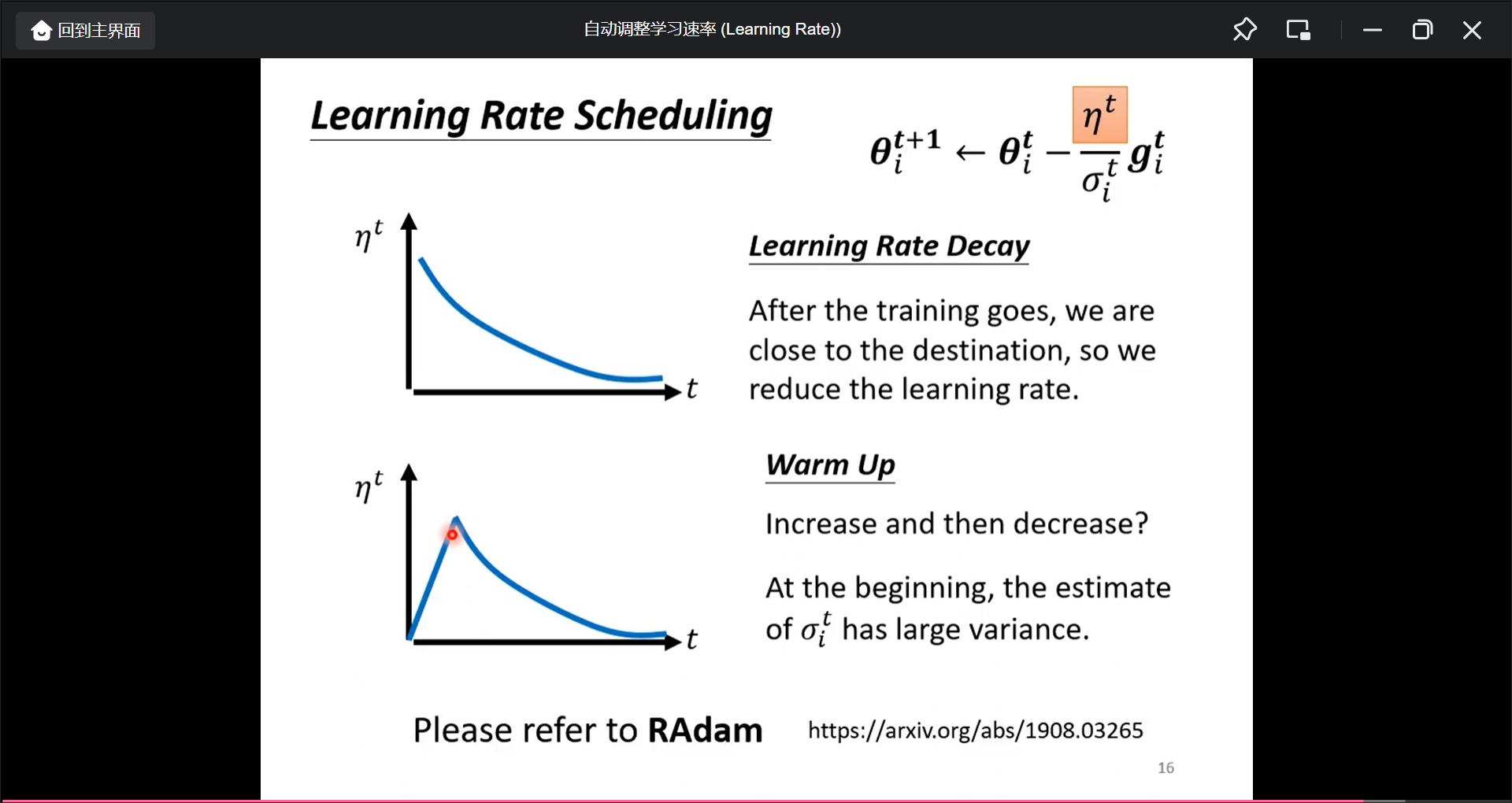
总结
损失函数可能影响网络训练失败

为什么要用softmax看之前的录影.
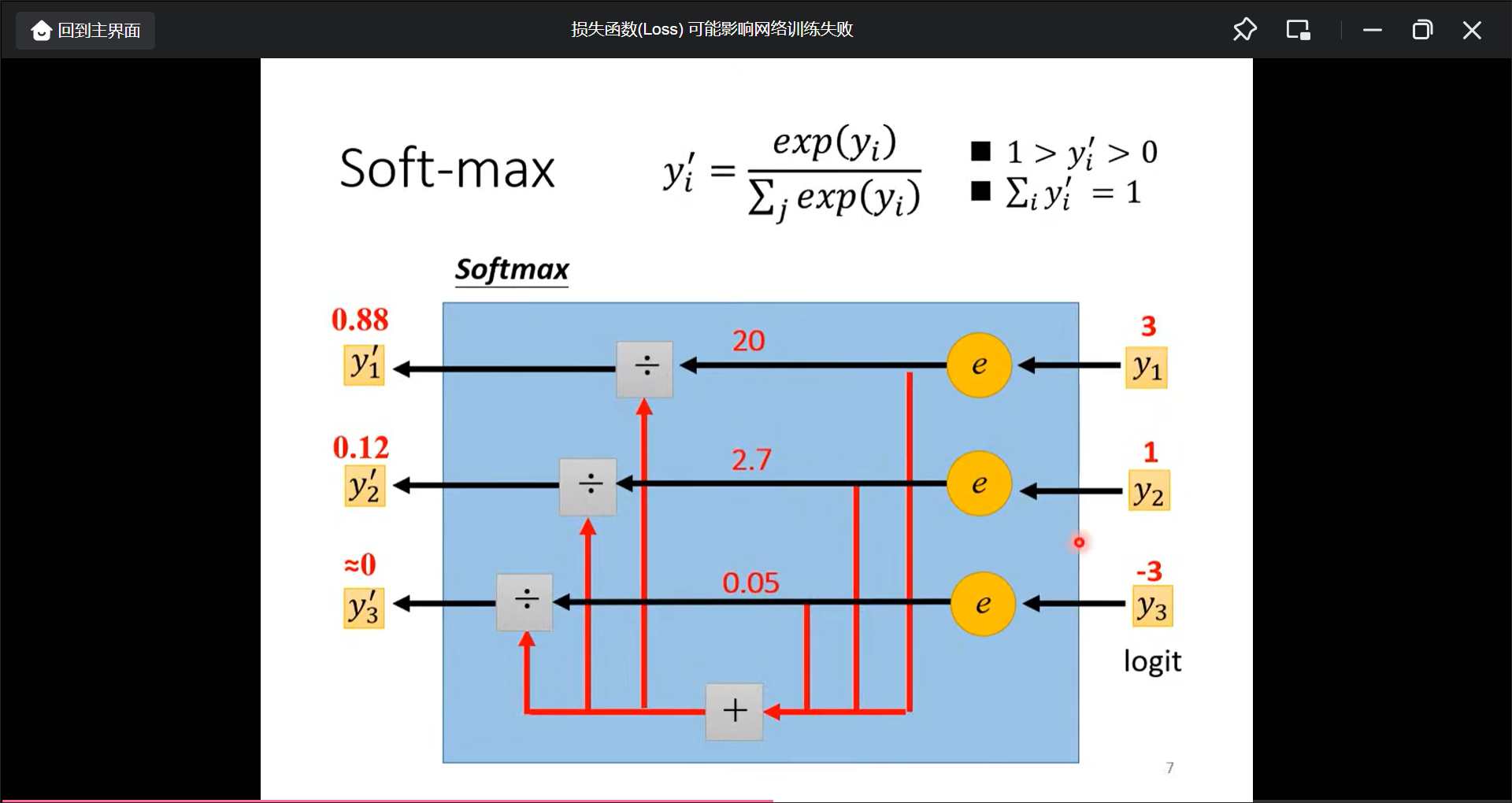
当只有两个class的时候, 用sigmoid即可.
而目标值和计算值的距离如何计算, 简单的比如(MSE), 但常用Cross-entropy(在pytorch甚至cross-entroy和softmax是绑定在一起的, 所以当用cross-enctorpy的时候就加了一个softmax):
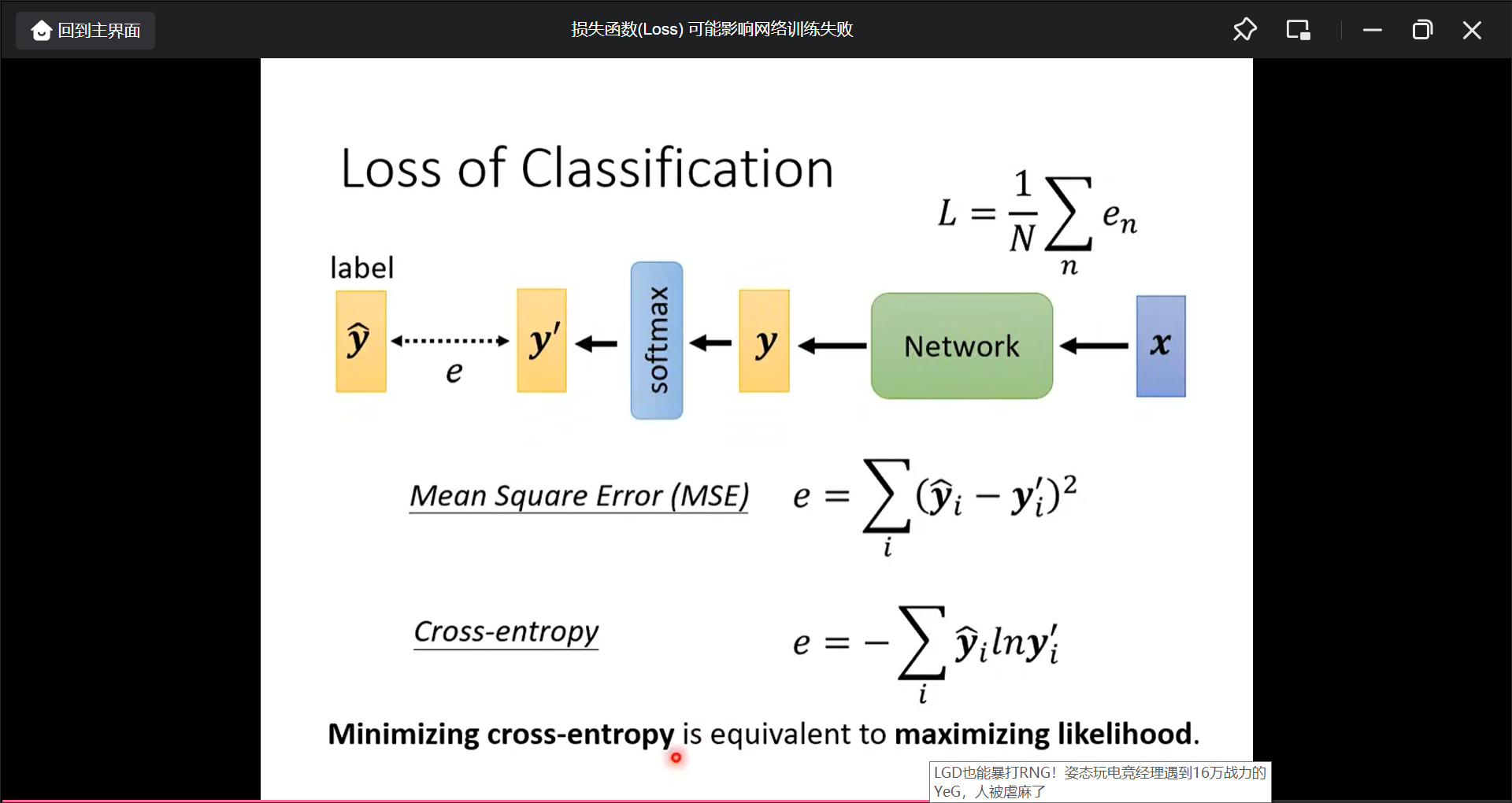
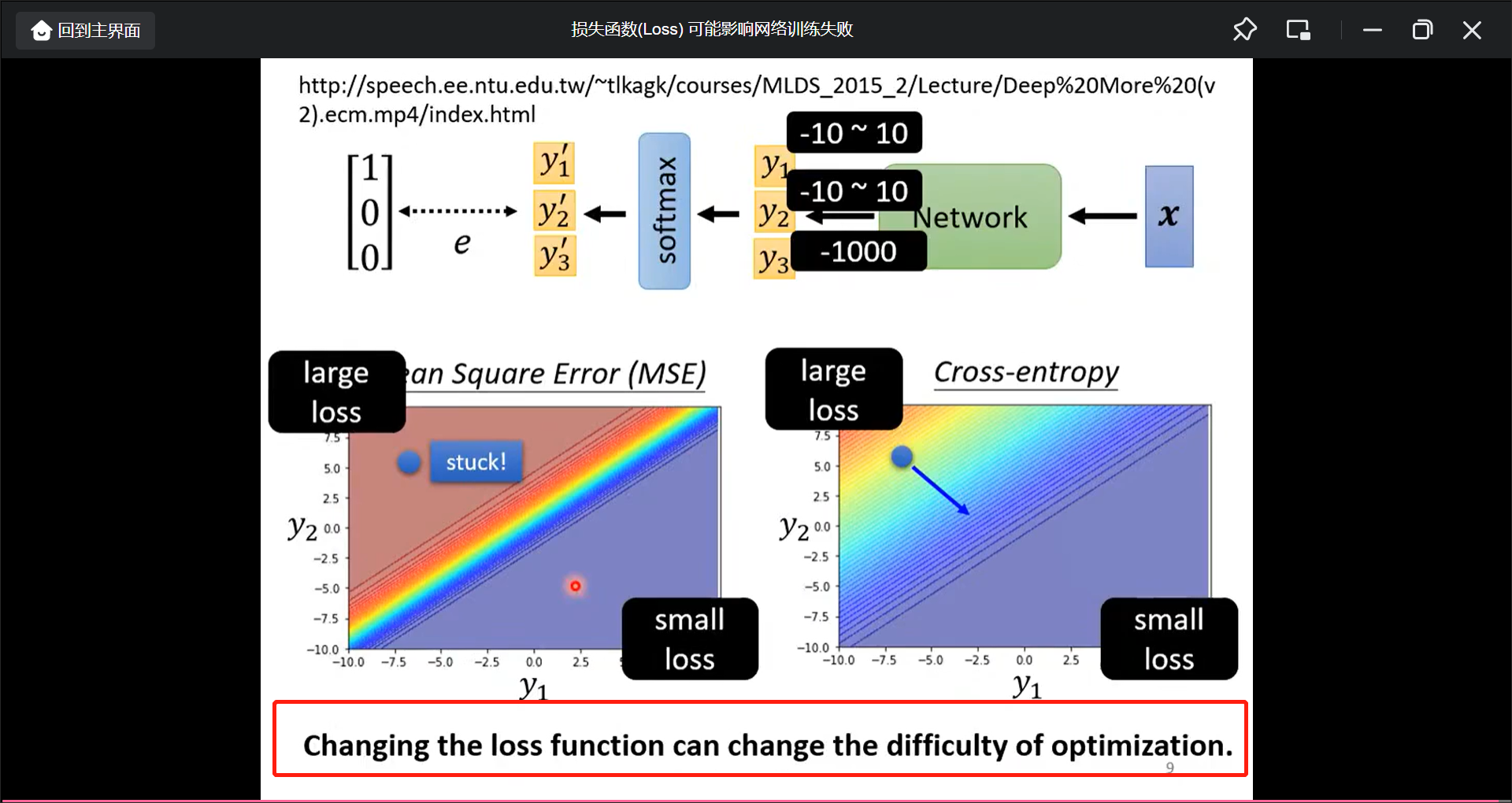
MSE和Cross-entorpy的区别(MSE在large loss的时候反而就gradient已经为0了):
重温神奇宝贝和数码宝贝分类器
这节课讲为什么参数越多越容易过拟合

所以现在的目标是找一个好的$D_{train}$, 我们不一定找到好的$D_{train}$, 所以评估找到差的$D_{train}$的概率为多少呢?

结论是:


其中$|H|$是模型的个数, $N$是训练样本的个数, N越大, $|H|$是可能模型的个数.(注意是上届)
进行变式, 得

所以为了逼近训练(理想)和全部资料(现实), 也就是Dtrain和Dall训练的loss都很接近, 要么减小H要么增大N.那么N就是训练资料, H的话,太小了则说明模型很少, 但这时候也许就很难拟合函数了.
鱼和熊掌简单的话就是要深度学习.
第3讲 CNN
卷积神经网络
输入时矩阵, 如果非正方形, 则进行变形处理成正方形.
输入是one-hat向量, 维度为种类的个数.
输入:
3*100*100., 可以将其拉成一维向量, 也可以直接将其作为多维向量输入.
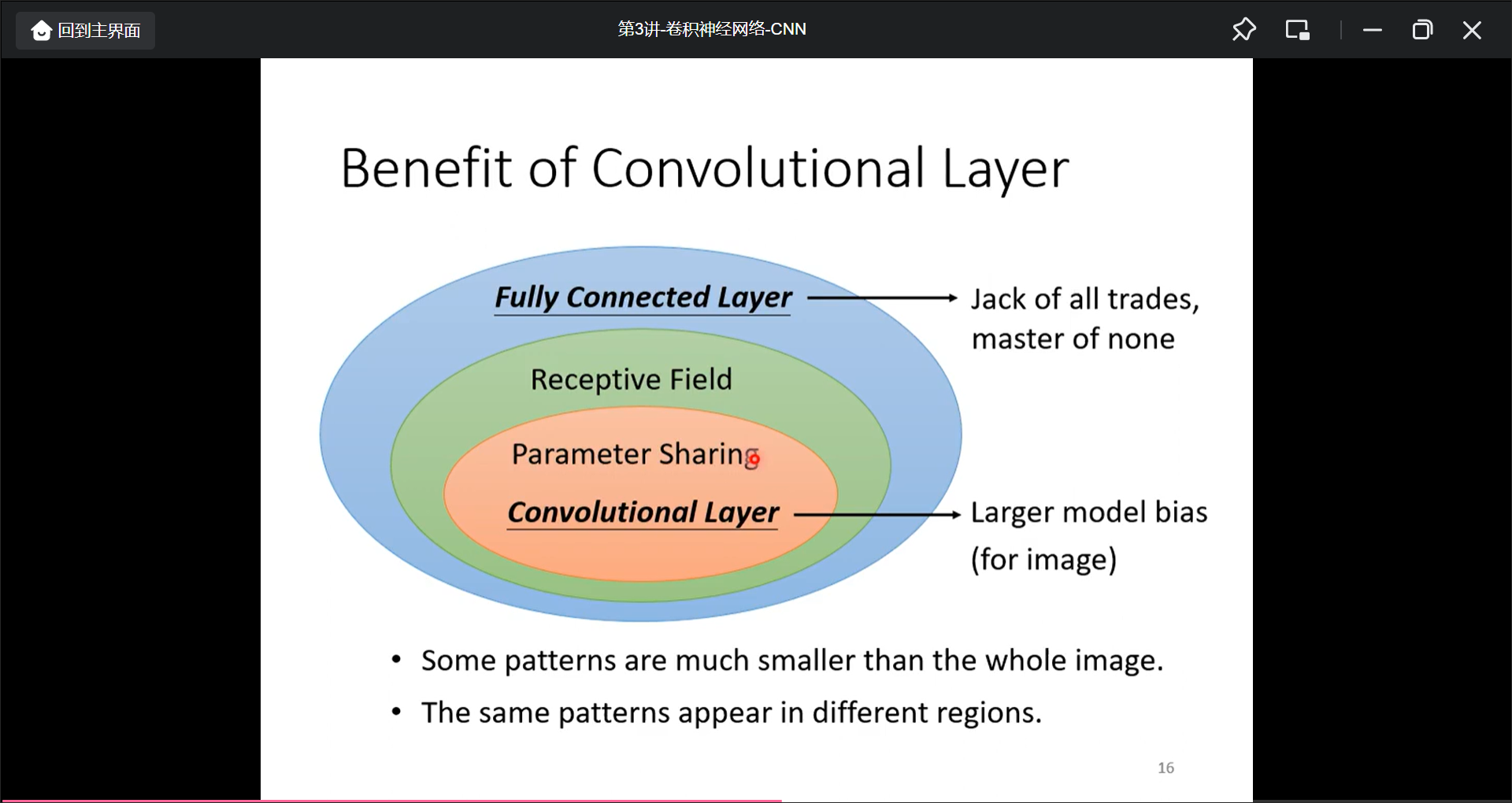
观察
不需要让neual看完整的信息=>局部作为recept field(这里可以将卷积重叠, 将卷积不重叠, 将卷积部分设置成长方形)
最常用的receptive field为3X3, receptive filed可以进行移动, 移动步数叫做stride, 而考虑边的地方而超出影像的部分叫做padding.
而图片给的不同地方有些相似, 所以可以用一个神经元来表示, 这就引申出了共享参数.
也就是说, 通过观察把模型的个数减小了
观察2
通过filtter进行获得特征提取, 通过很多个fillter进行不同特征的提取
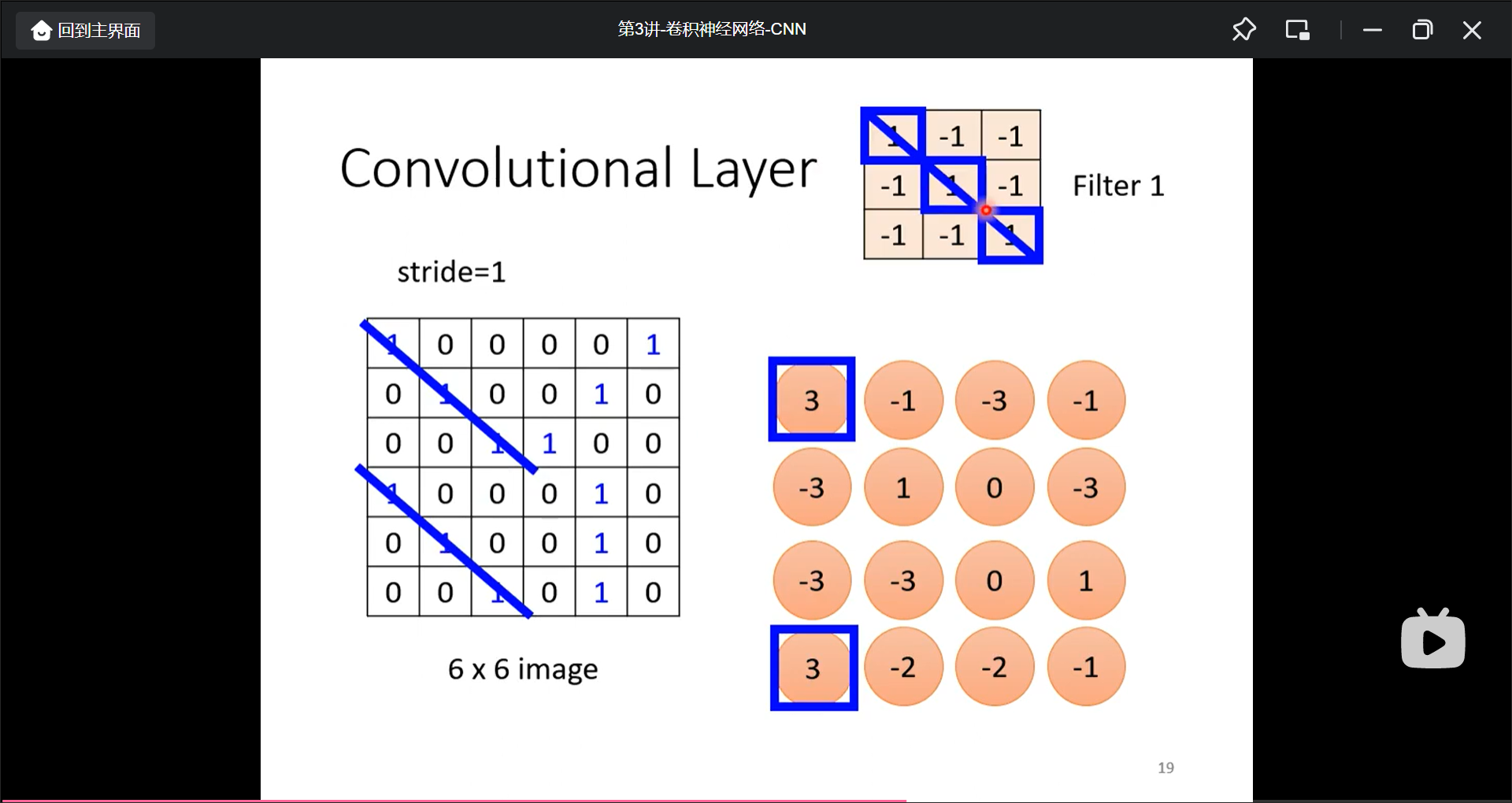
总结

pooling
把图片的像素拿掉之后不会影响画面, 所以这层没有leraning什么东西.
在实际中卷积和池化交叉使用, 做几次卷积之后做一次池化.池化的理由是减少运算量, 所以现在也逐渐不用池化, 因为计算能力增加了.
flatten
把多维矩阵拉直
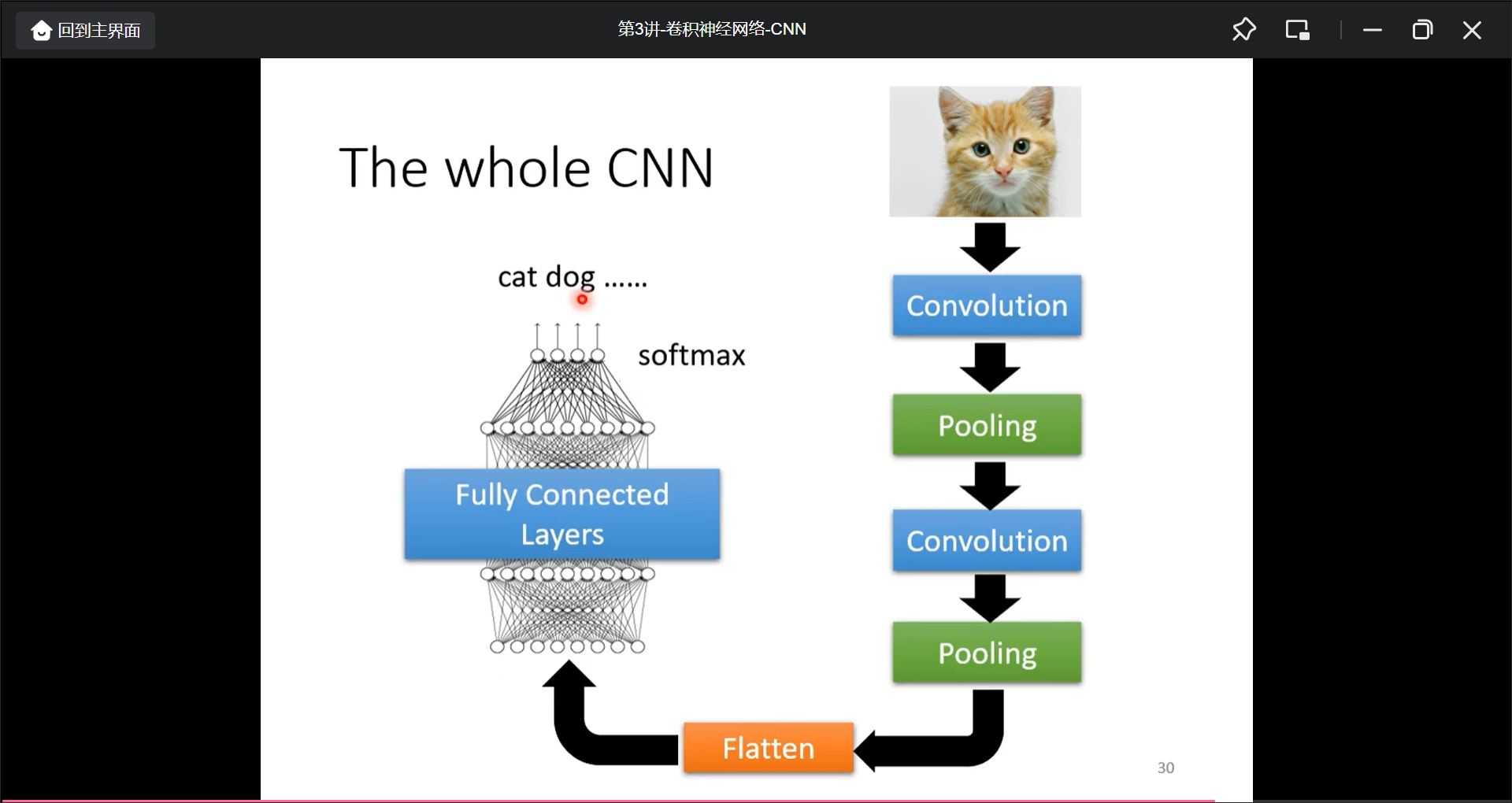
应用
alphago 就是把19*19的棋盘用矩阵来描述.alpha原始论文中以48个数据来描述一个点(没有pooling, 但是棋盘不适合用pooling).

CNN的局限
CNN不适合影响放大和旋转.
第4讲 Sequence as input(self-attention)
自注意力机制(Self-attention)上
有时候输入不一定是长度相同的向量, 比如句子, 声音讯号, 图, 这些都是一堆向量
句子: 首先将词语进行向量化, 然后句子就是一排长度不一的向量, 词语向量化的方法如下:
- one-hot encoding
没有语义信息 - word embedding
相似的词语的向量比较接近.
声音: 将同一时间间隔的声音讯号(比如25ms作为一个frame), 声音向量化的方法如下:
- 400 sample points
- 39-dim MFCC
- 80-dim filter bank output
图, 比如一个人际关系图, 把每个节点看作一个向量.
分子结构, 把一个分子作为一个图, 然后分子上面的原子就看作一个向量(One-hot vector)
那这时候的输出呢?
有三种可能性:
- each vector has a lable
比如词性标注, 比如作业2音标分类的简化版 - whole sequence has a label
比如情绪分析, 一整个句子有一个label, 比如语者辨认 - model decides the number of label itself.
比如seq2seq.
本节课讲第一种类型的输出sequence labeling.
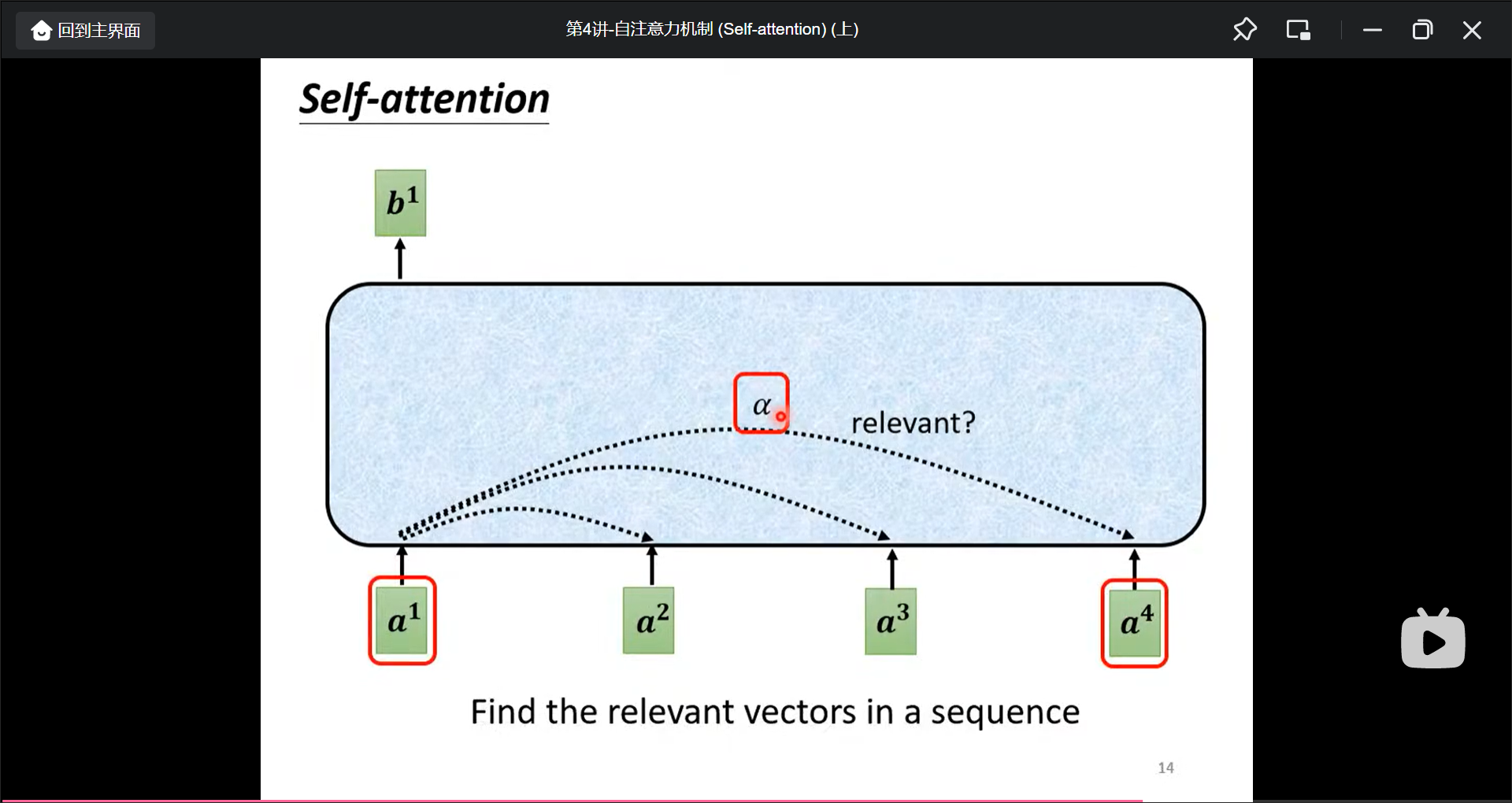
再进行sequence labeling模型输出的时候要考虑当前输入的上下文.
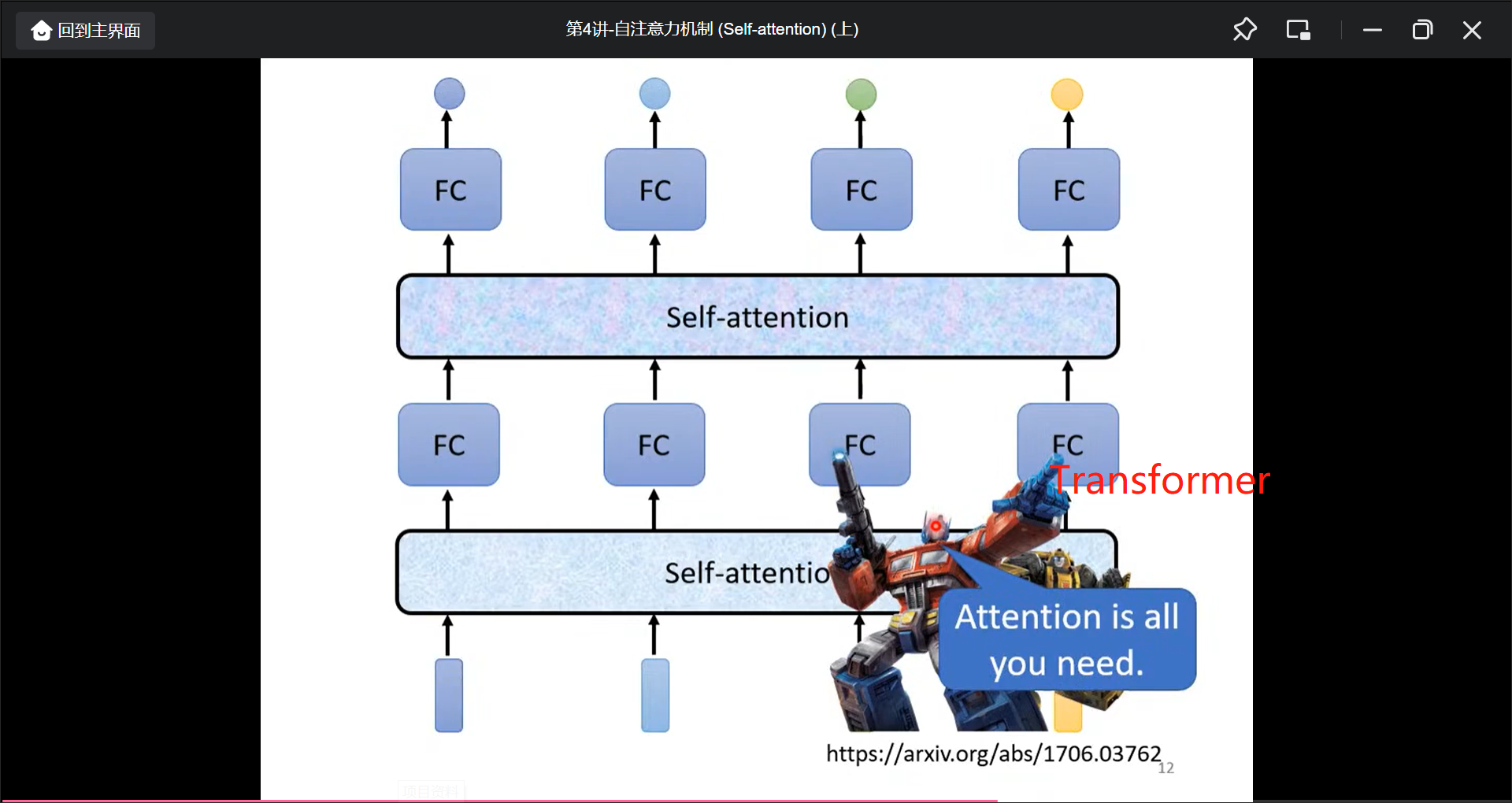
Transformer(Attention is all you need)就用了self-attention.
attention具体细节
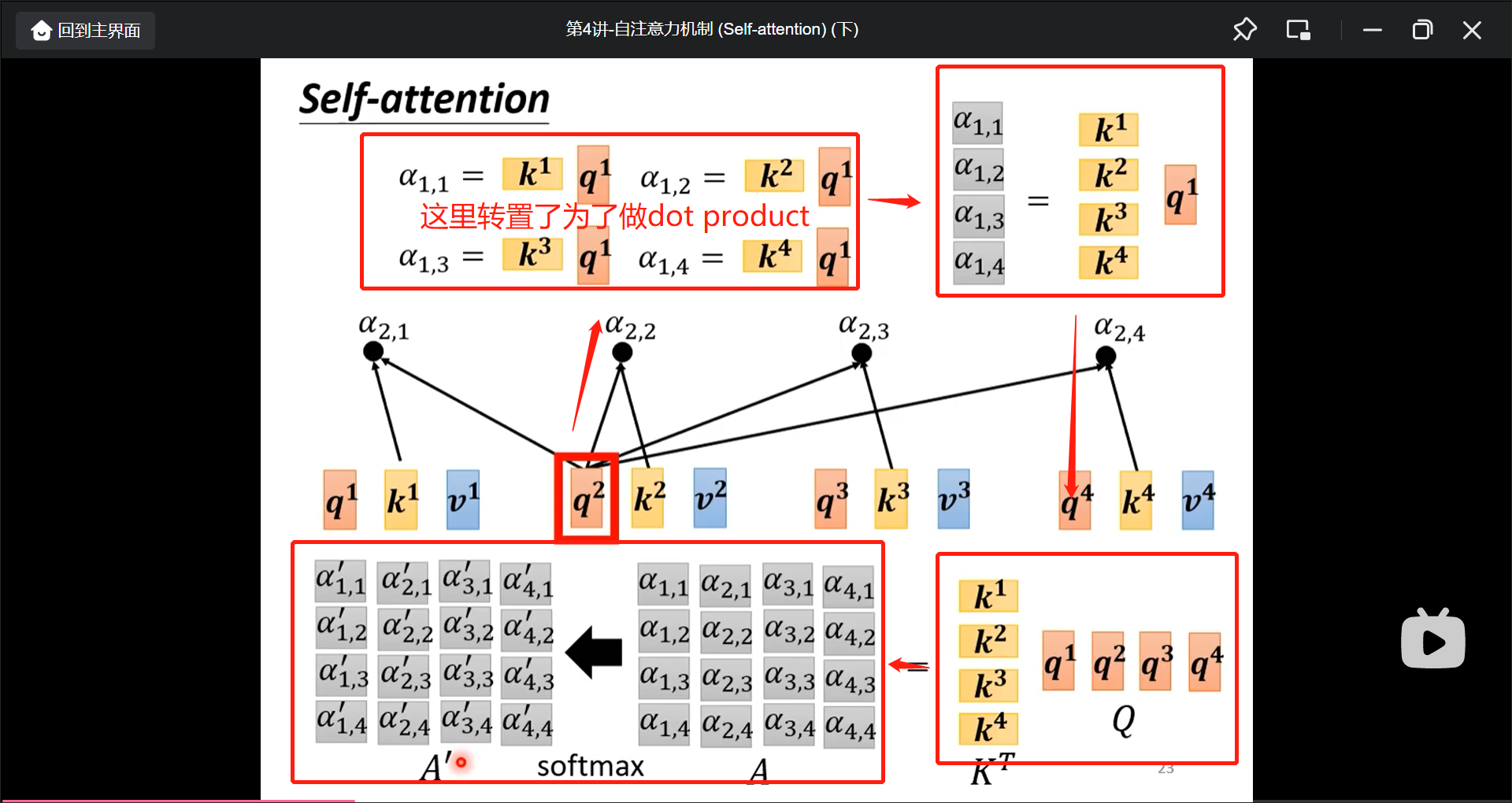
首先找出$a^1$和$a^n$有多相关, 用$\alpha$表示.
然后计算$\alpha$
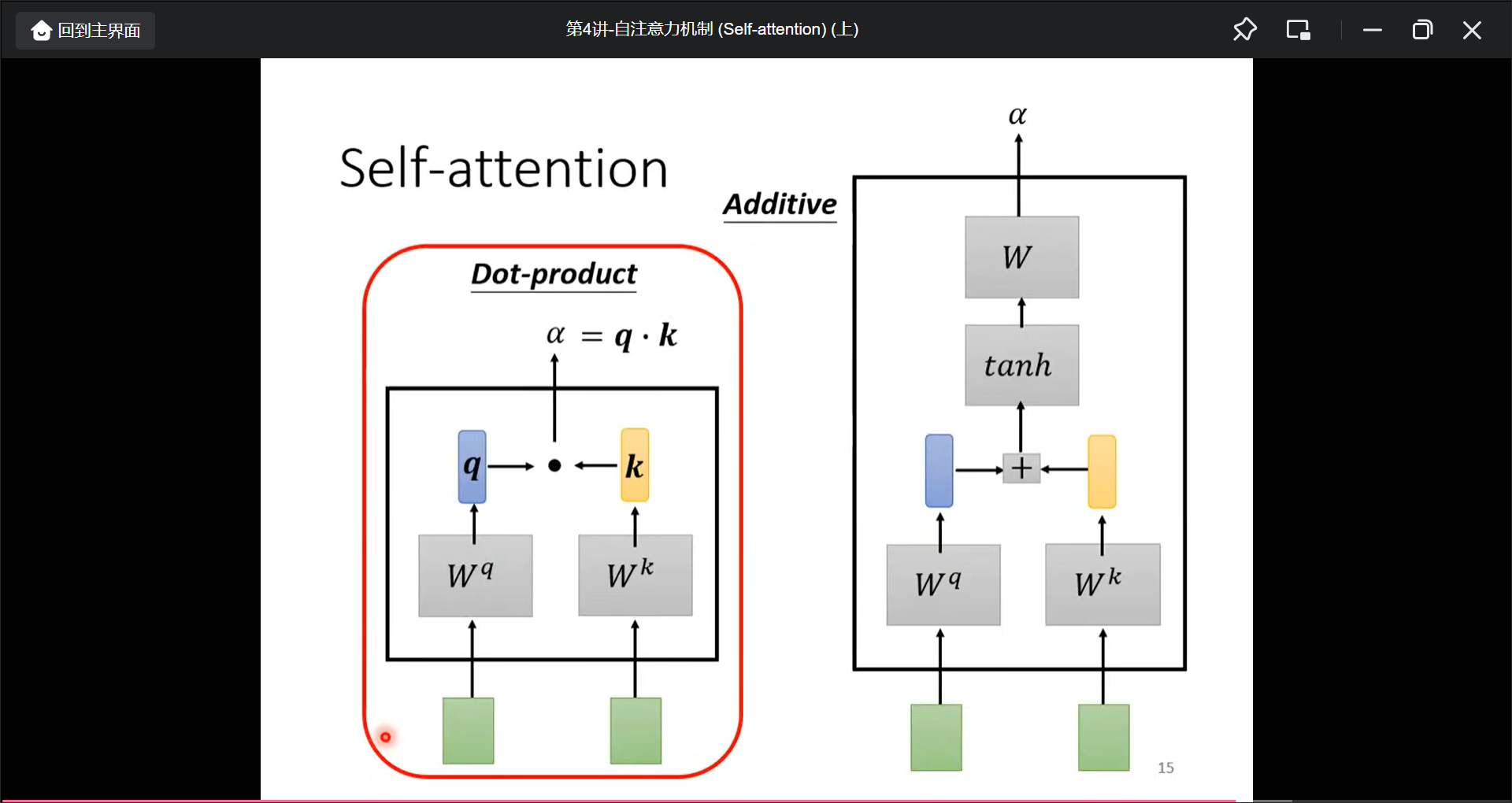
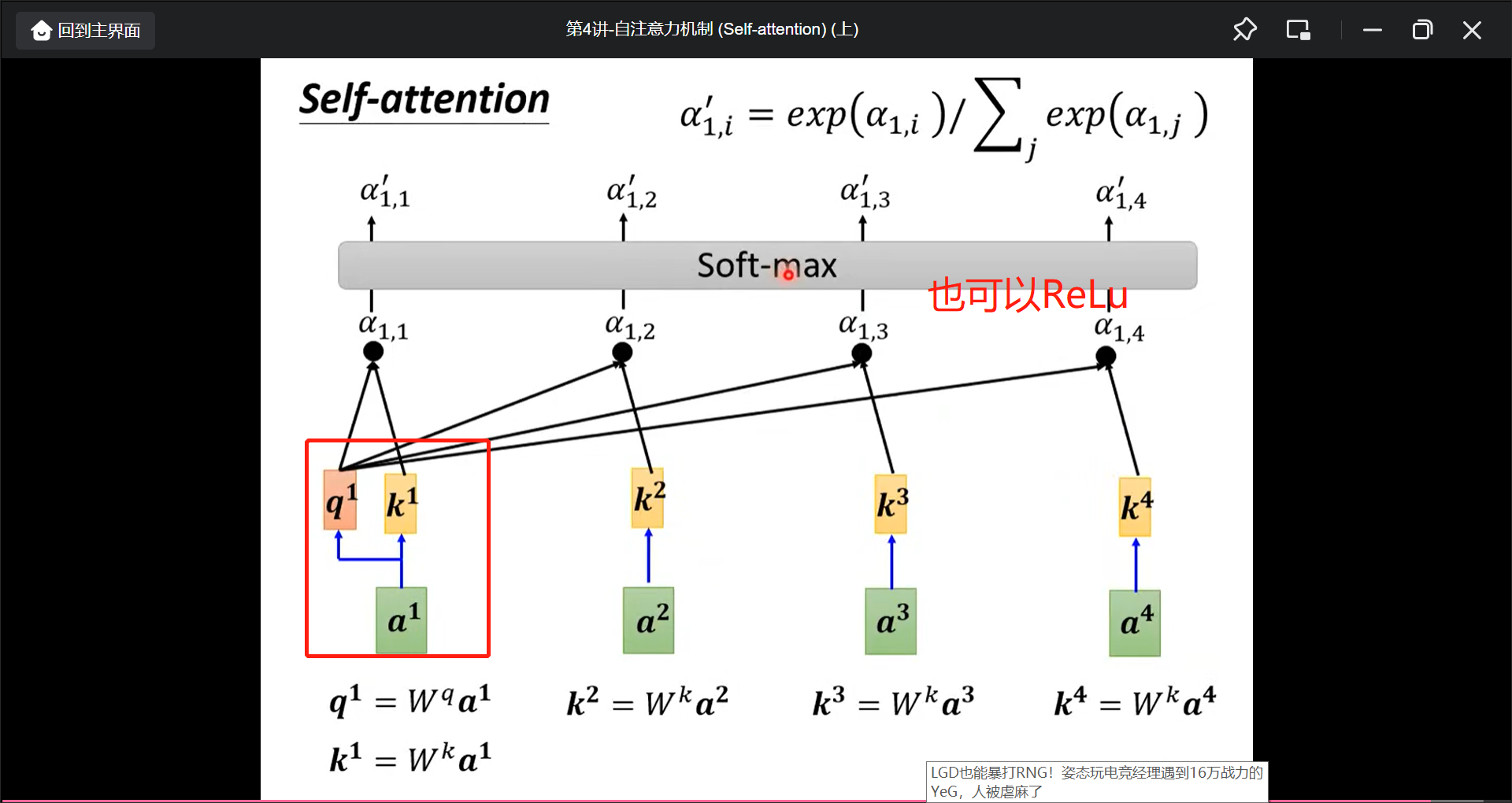
实际中还有一个$W^v$矩阵得到$V$向量.
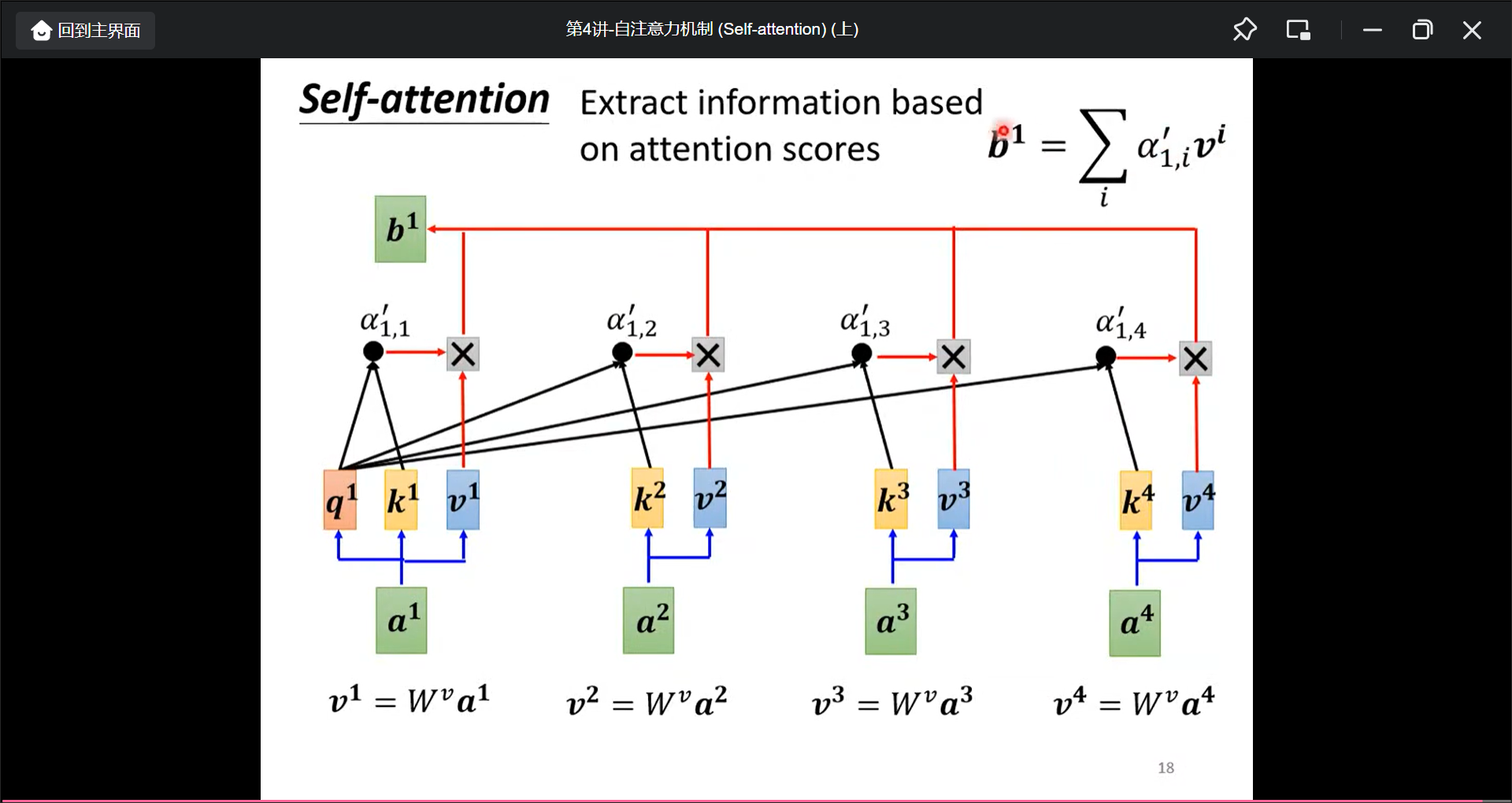
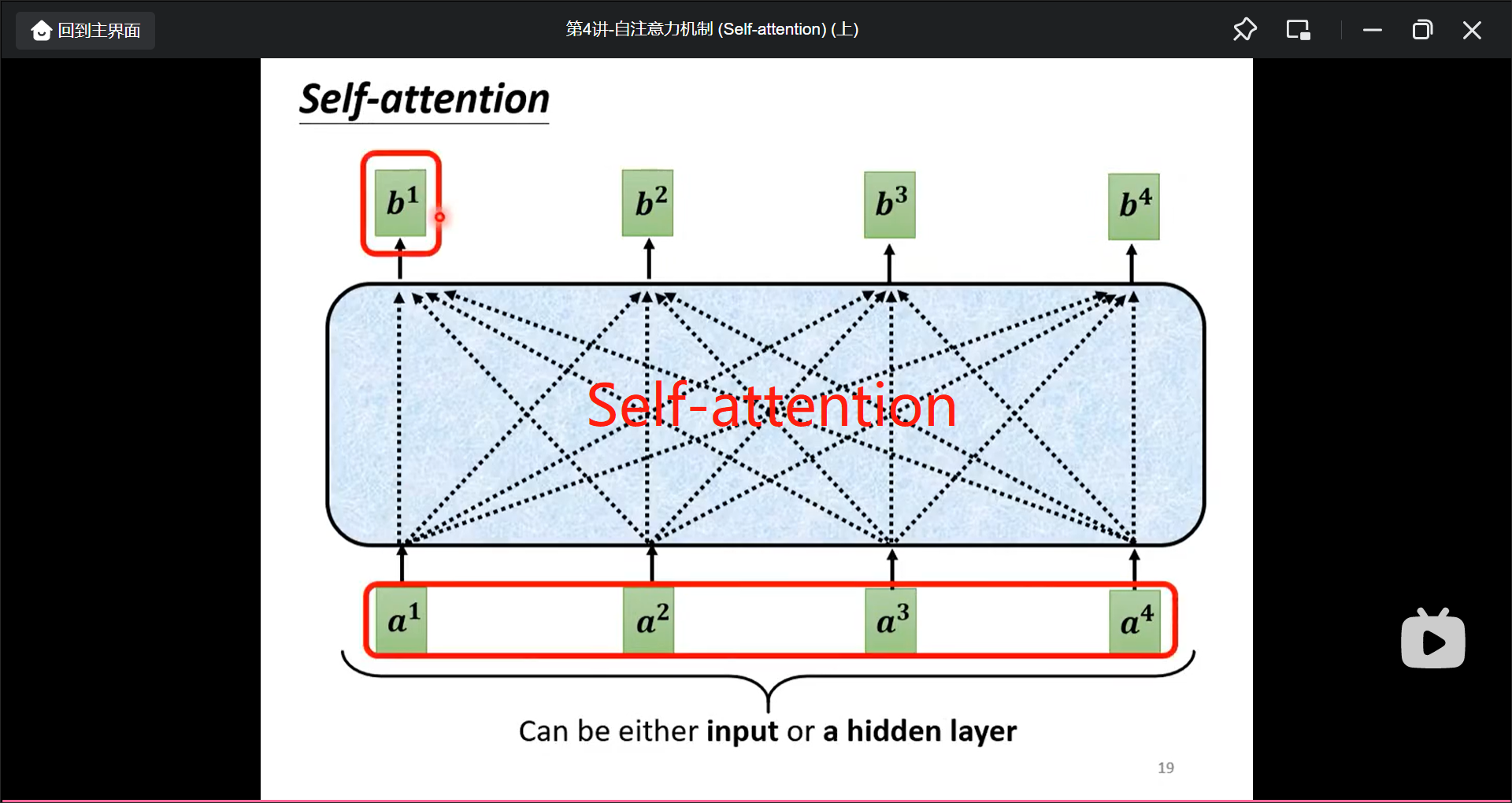
$b^n$的计算可以并行计算.
其中$W^q$是矩阵参数, 是学习出来的, 后面讲.
自注意力机制(Self-attention)下
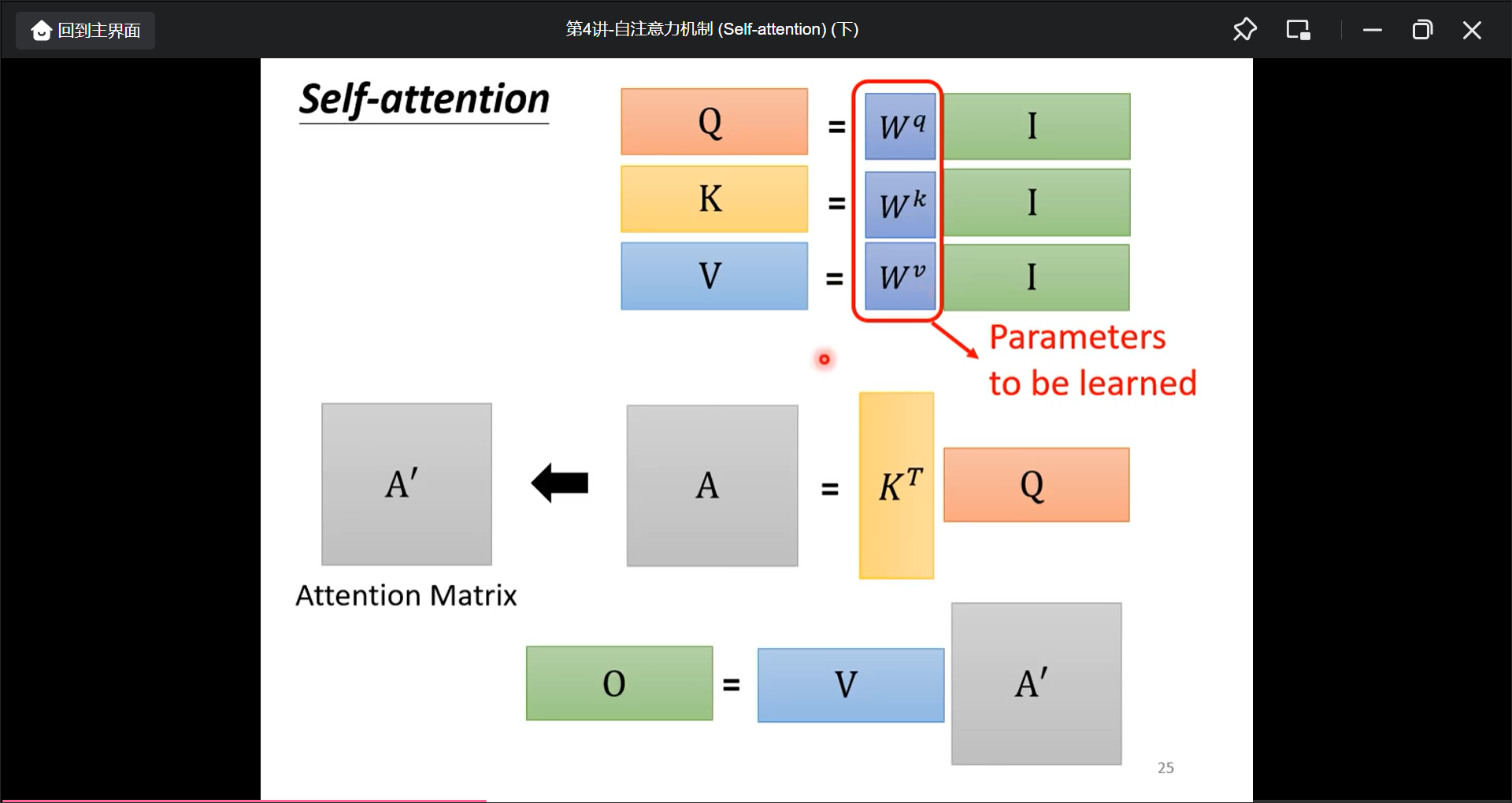
在实际过程中, 是这样计算出$Q$, $K$, $V$的.

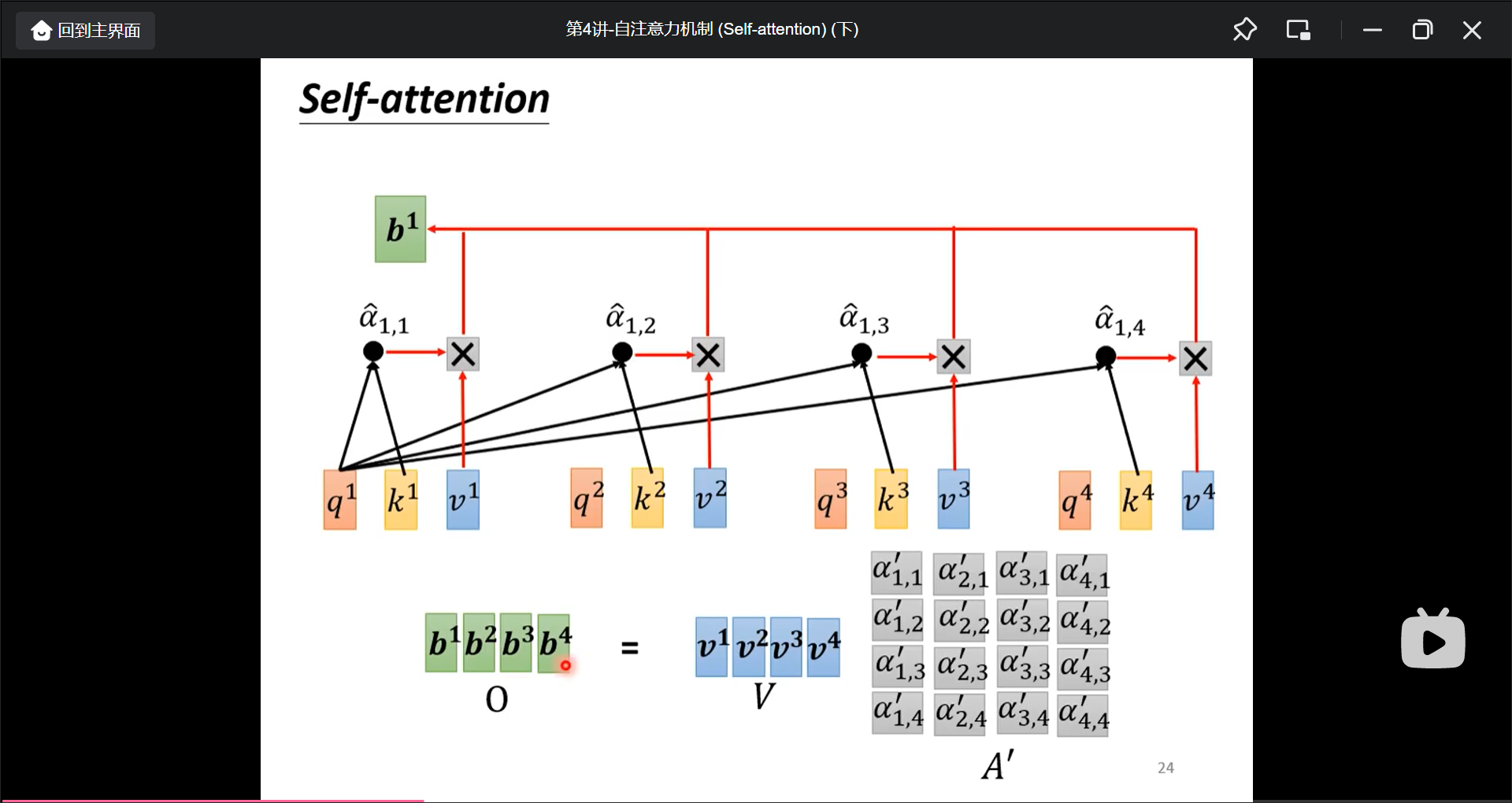
总结:
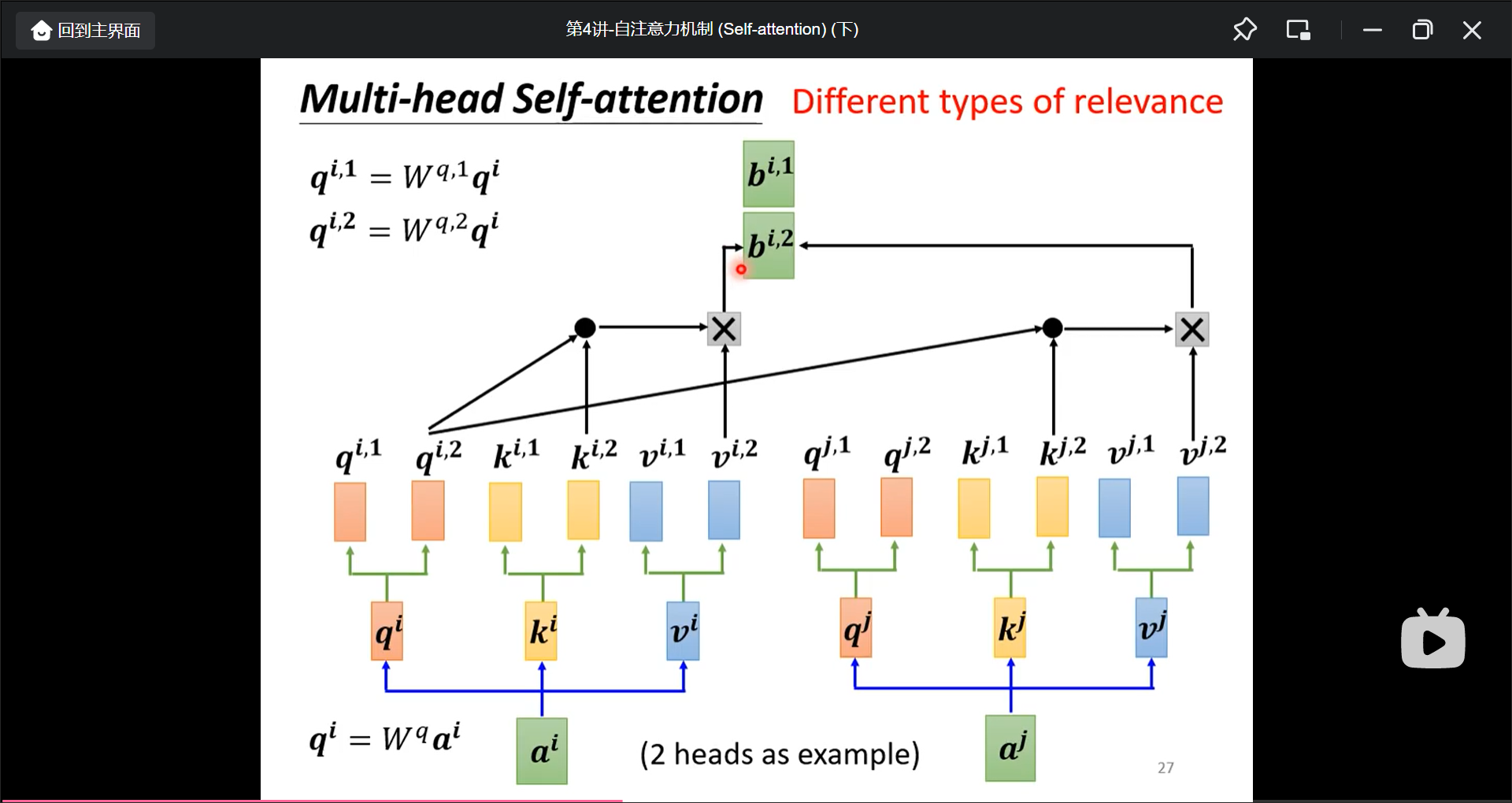
进阶版: multi-head self-attention(不同单词之间有多种关联度需要计算), 计算出来的两个b就可以接起来再送入下一次.
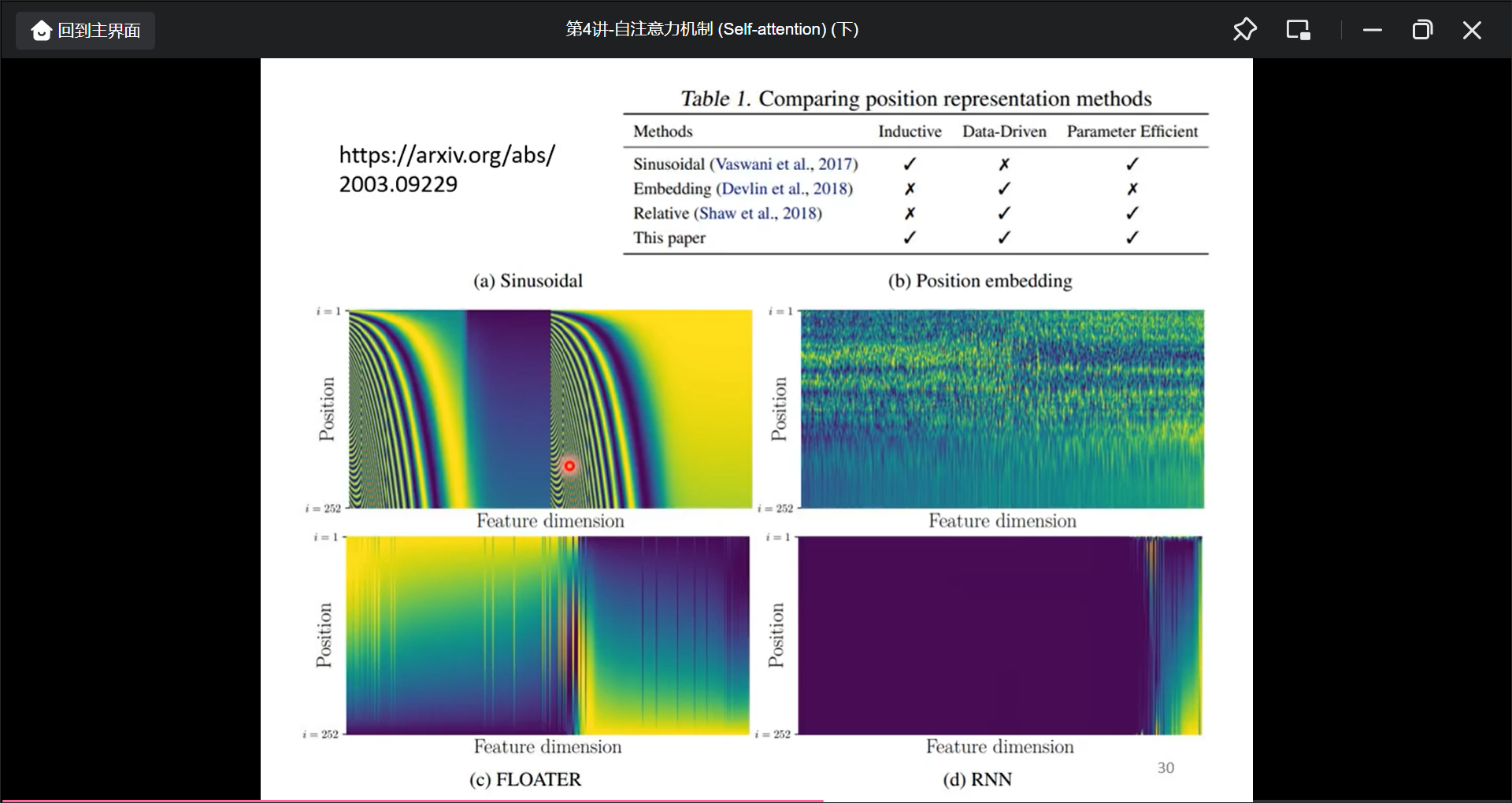
但是, 只考虑到了单词的关联度, 不同单词的位置信息没有考虑到, 解决的方法是Positional encoding:
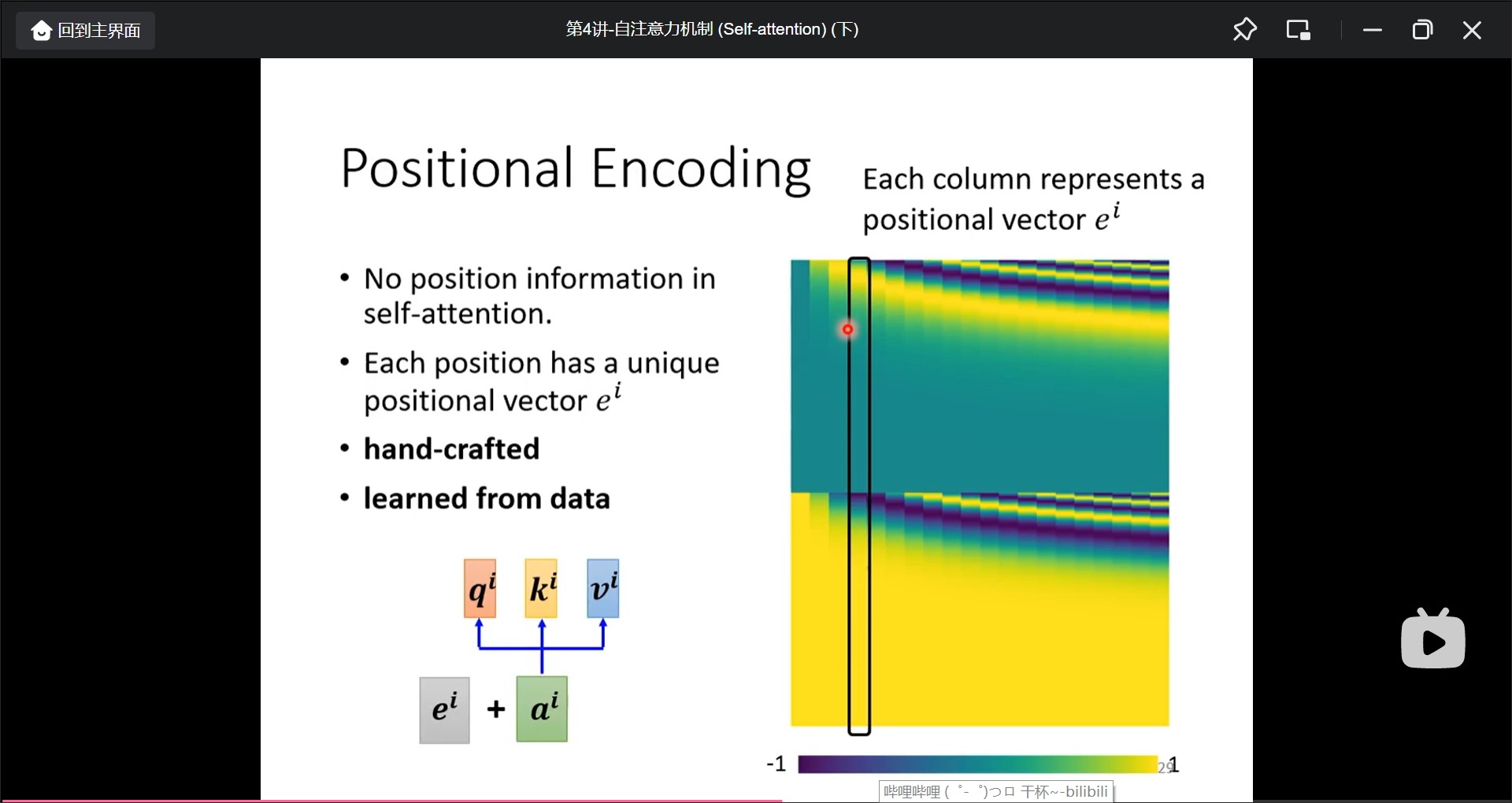
一些生成position encoding的方法:
Selfattenion的应用: NLP, Speech(Truncated Self-attention), Image,
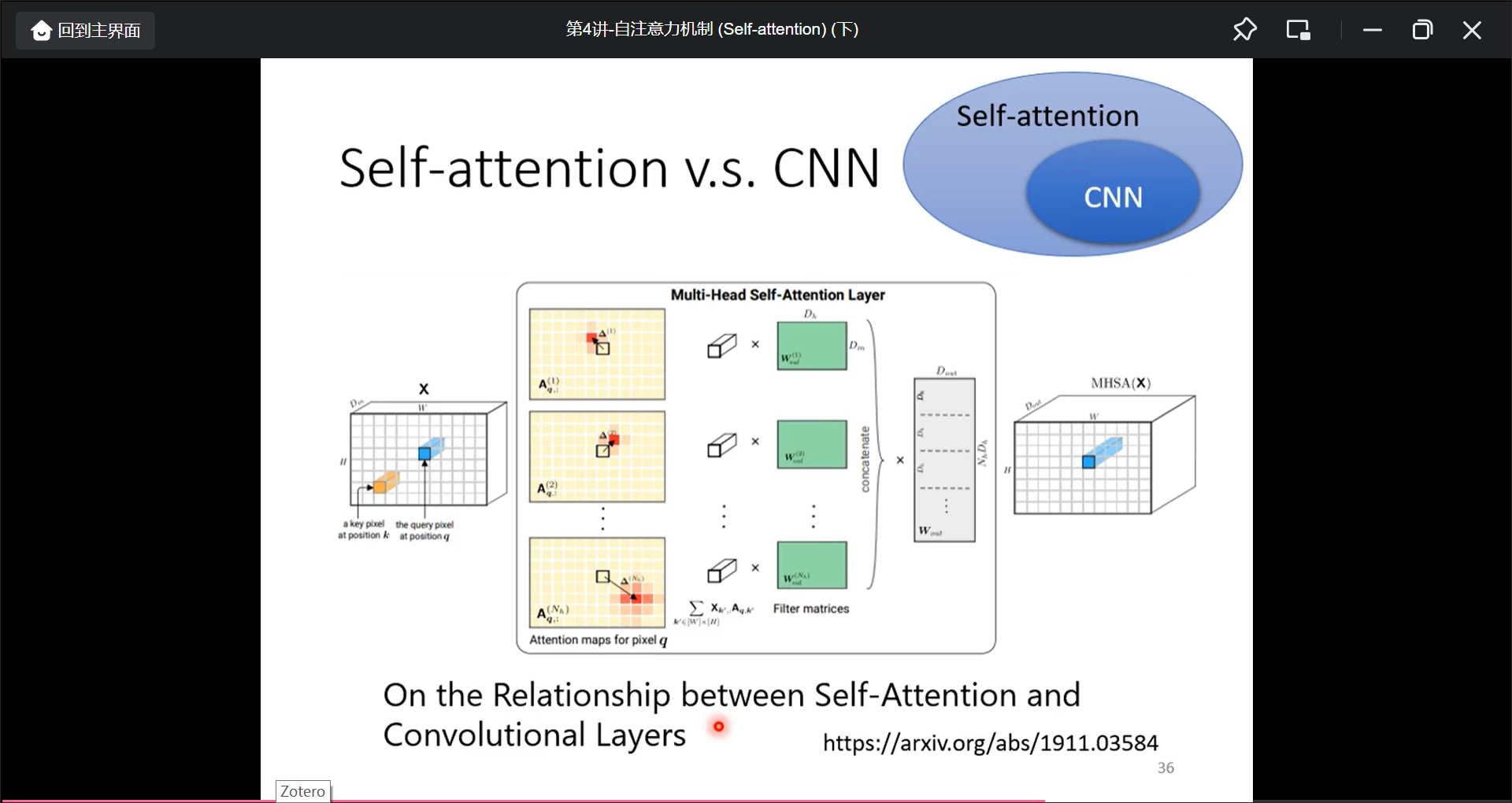
CNN可以看作简化版本的Self-attention, Self-attention是复杂版的CNN.
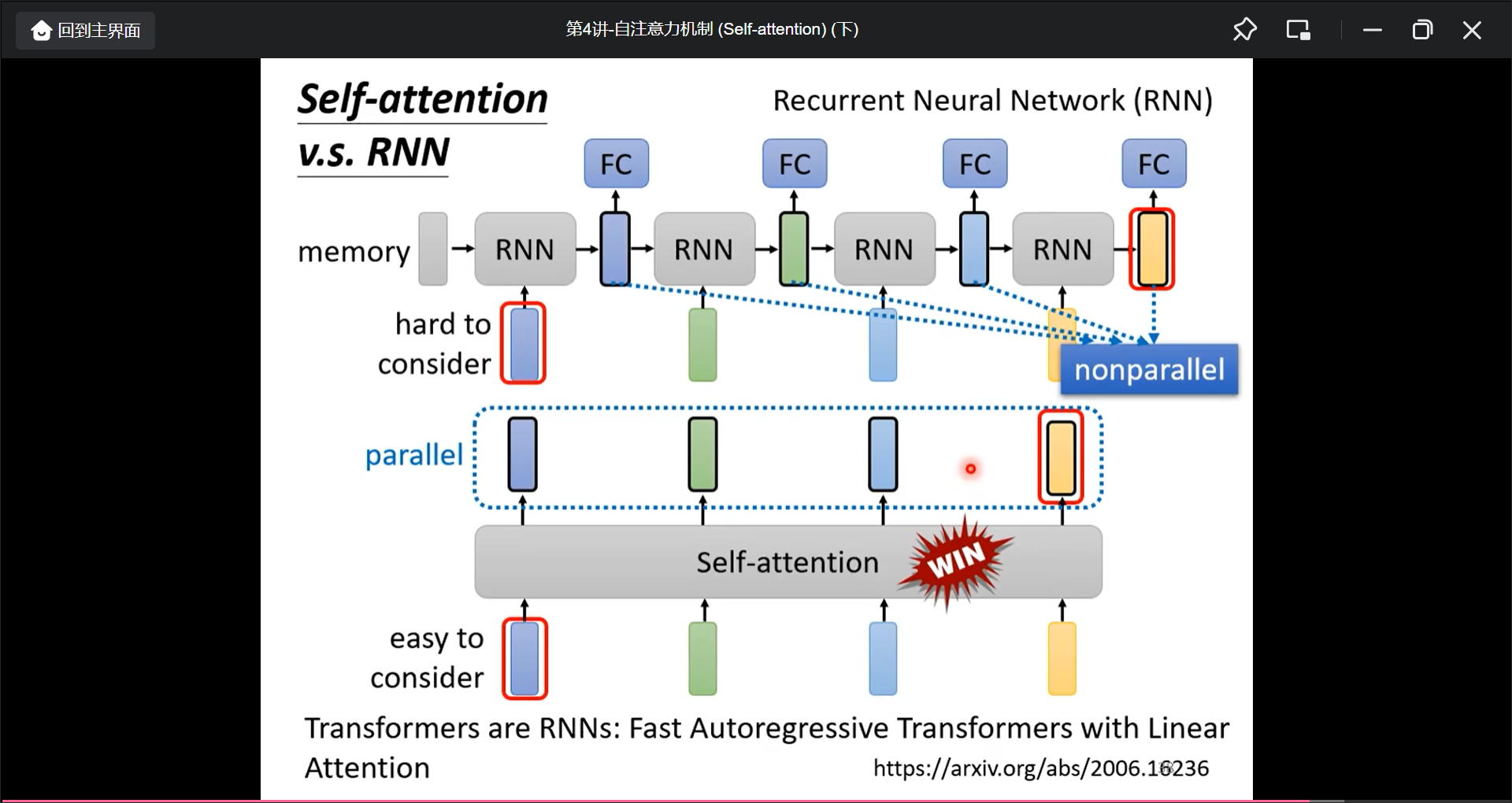
RNN和Self的区别
- RNN很难考虑很远的输入.Self-attention而可以考虑到
- RNN不能并行化.
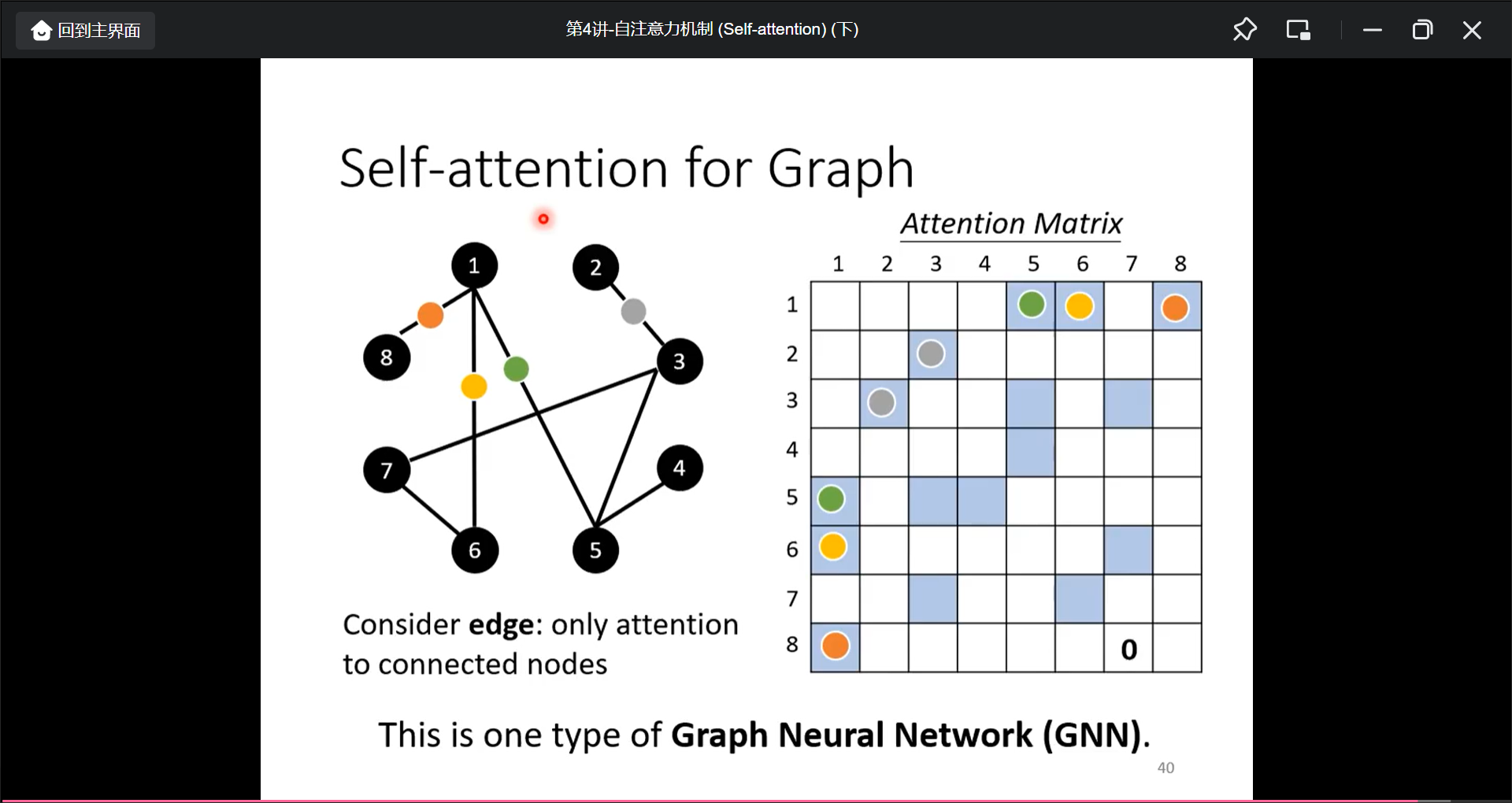
把Self-attention应用到Graph上面时, 也就是GNN:
第5讲 Sequence to Sequence Transformer
Transformer-1(Encoder)
Transformer 是一个Seq2Seq的模型, 输入和输出都是序列, 并且输出的长度是由模型决定, 比如常见的问题为
- Speech Recognition
- Machine Translation
- Speech Translation(不先speech recognition再translation是因为很多语言没有文字)

并且多数的NLP任务都可以被视为Question Answering, QA就可以用seq2seq来解决: 输入为question, context, 输出为answer, 所以多数任务都可以用seq2seq来解决.
NLP: https://speech.ee.ntu.edu.tw/~hylee/dlhlp/2020-spring.html
另外还有很多任务都可以用seq2seq来硬train:
- syntactic parsing(输出的树状结构可以看作一个sequence)
- multi-label classification(与Multi-class作比较的话也就是同一个东西可能有很多个label而不只一个class)
- object detection
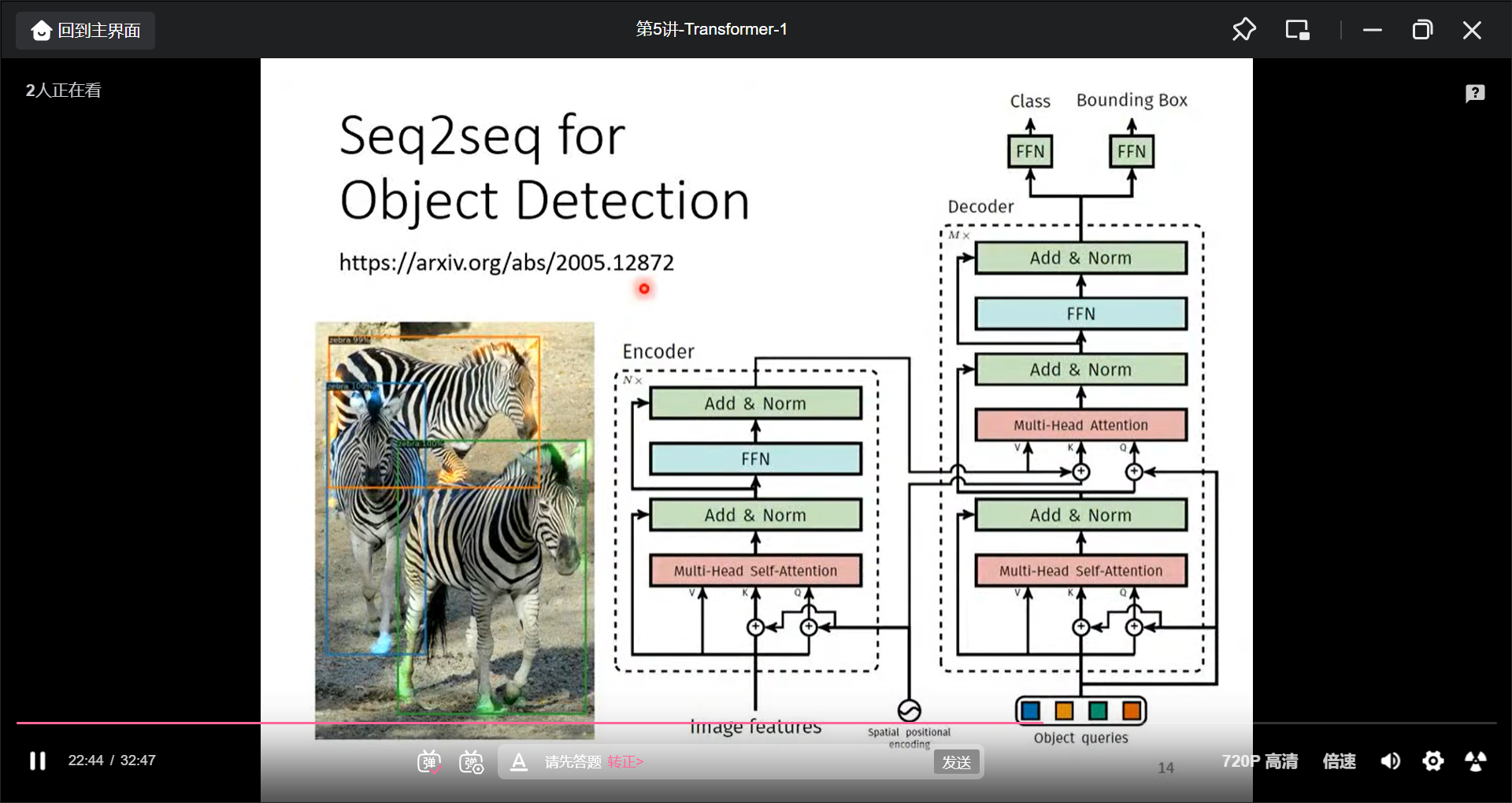
seq2seq的具体的操作为:
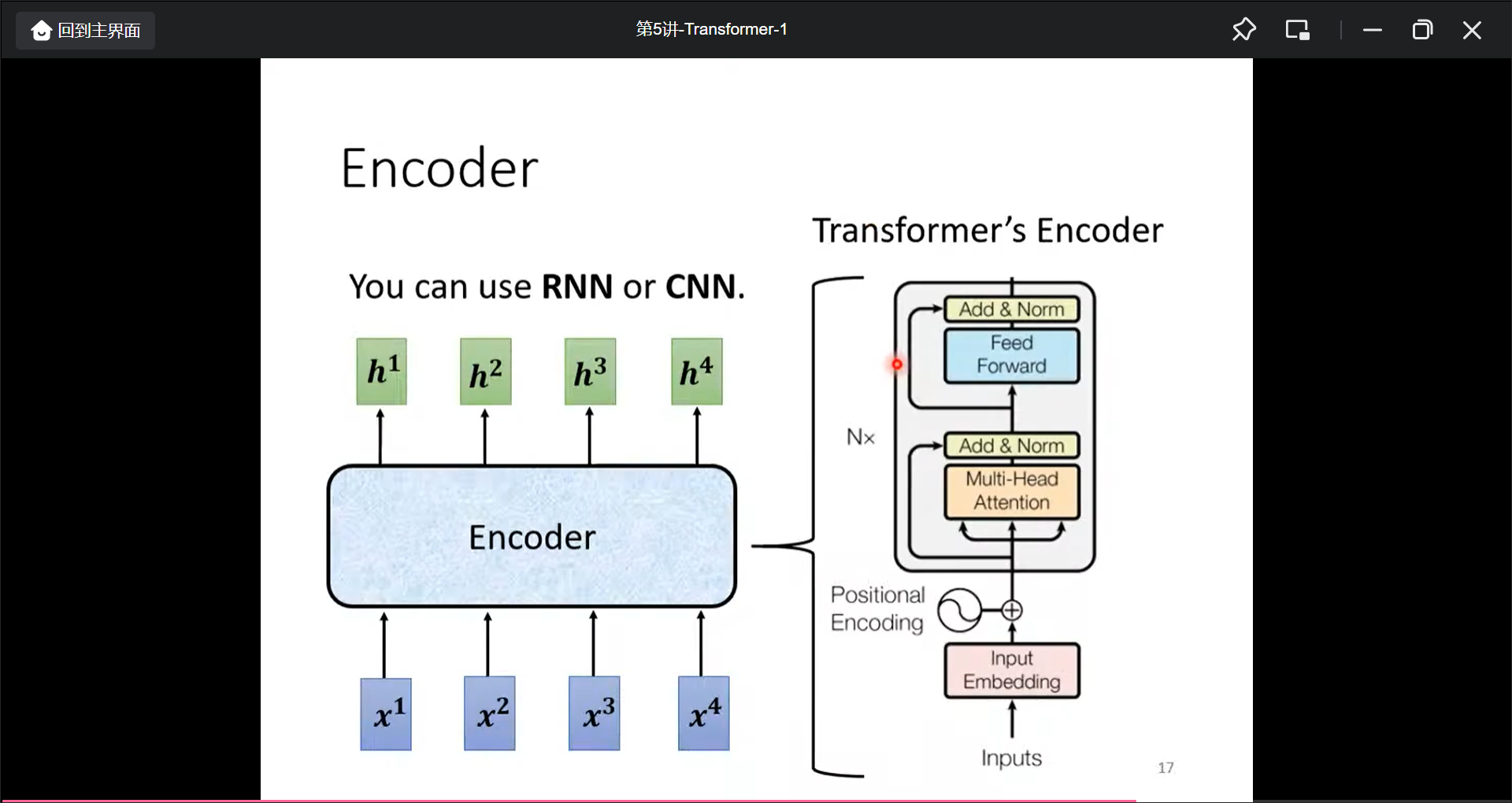
一般的encoder的block为:输入一组向量, 输出一组向量, encoder是这样的
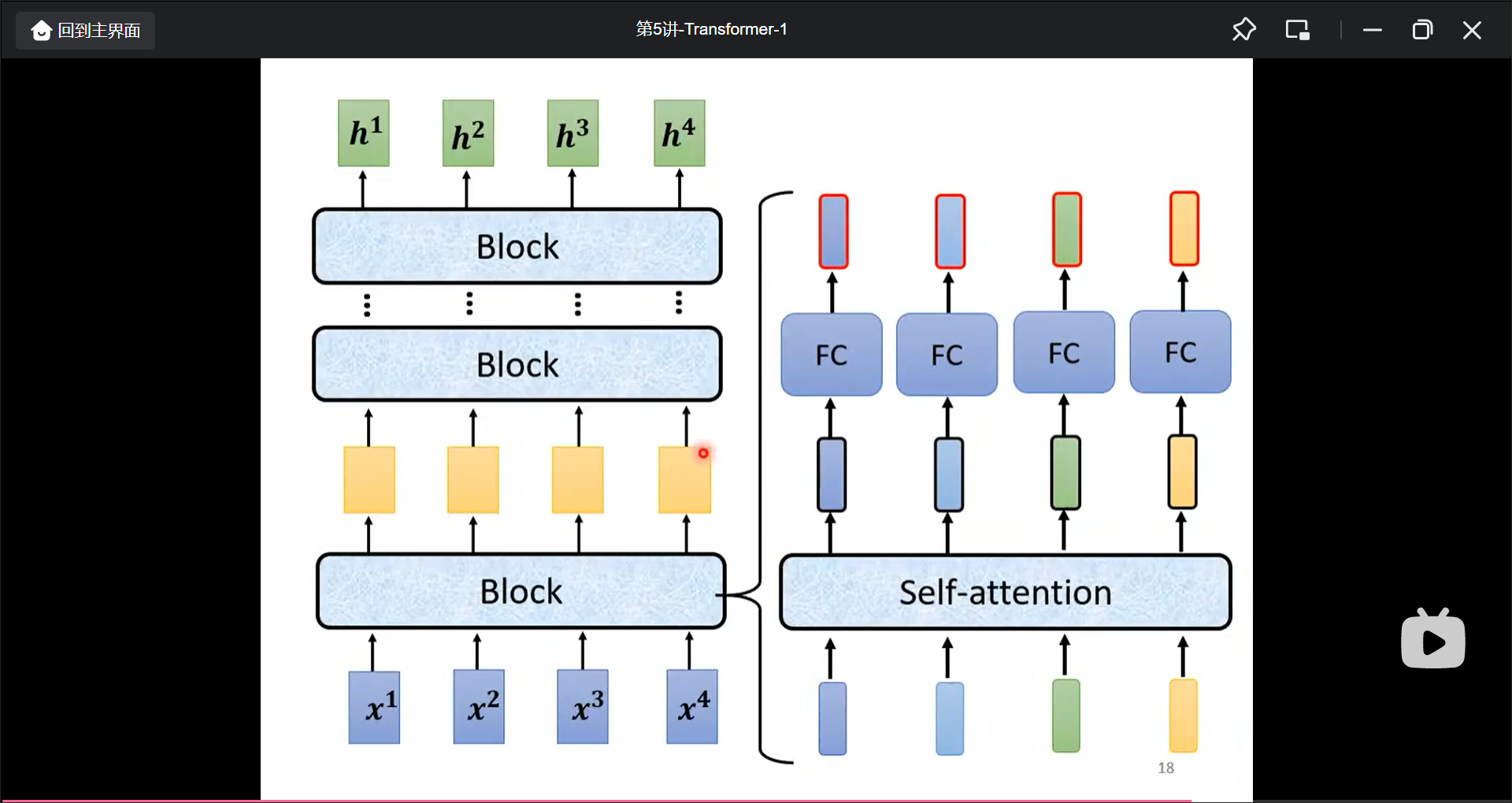
而encoder是由好几组block组成的, 每个block是这样的:
在实际中的transform是这样的(加了reditual和norm):
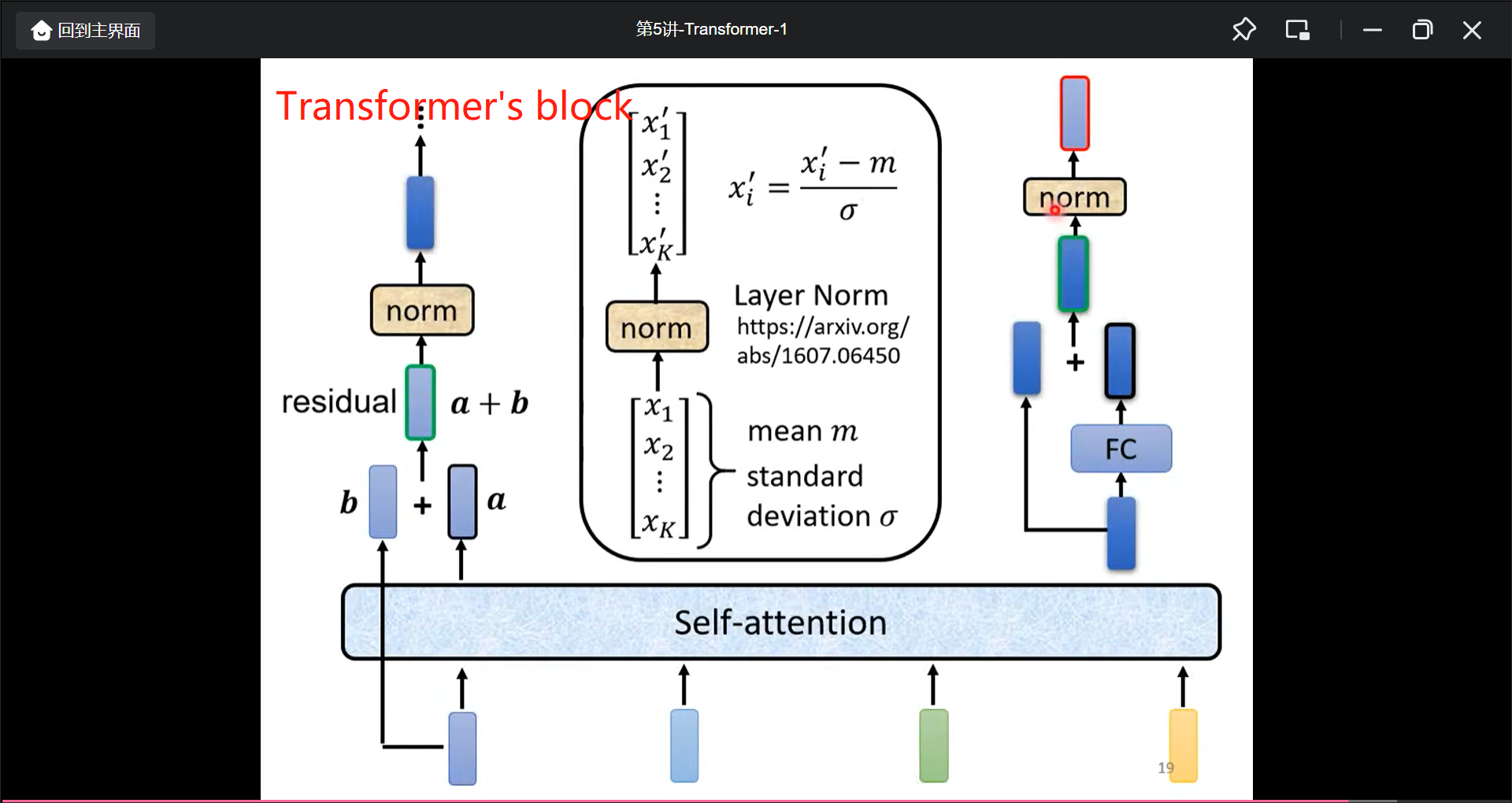
当然这样安排不一定是最好的, 只不过transformer这样安排了
Transformer-2(Decoder)
Decoder有两种, 最常见的是Autoregressive.
注意这里要先准备一个
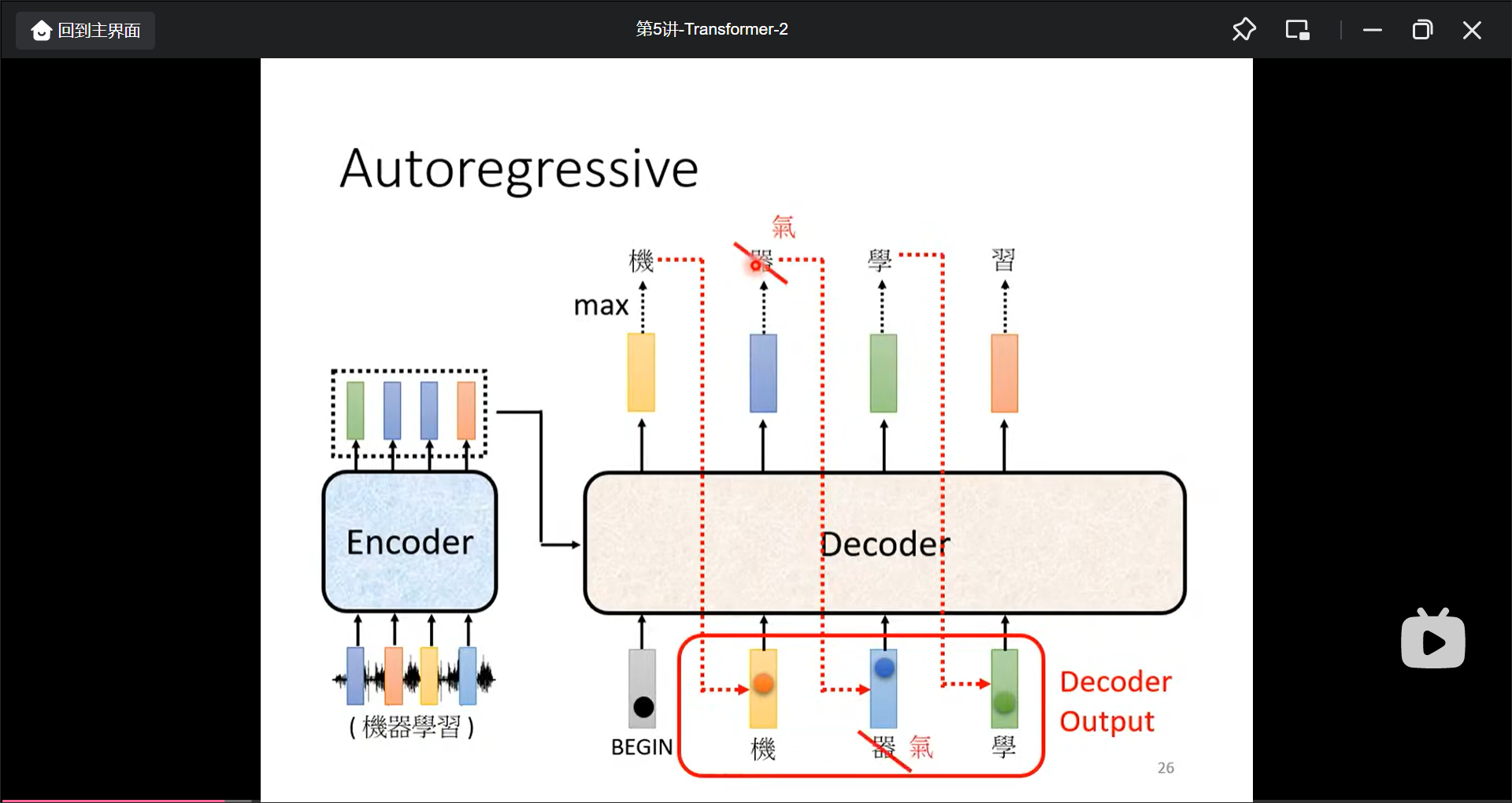
注意这里和ibizsim结合, 另外这里有一个bug就是”一步错步步错”的问题, 在ibizsim中也要考虑到.
Encoder和Decoder的差别
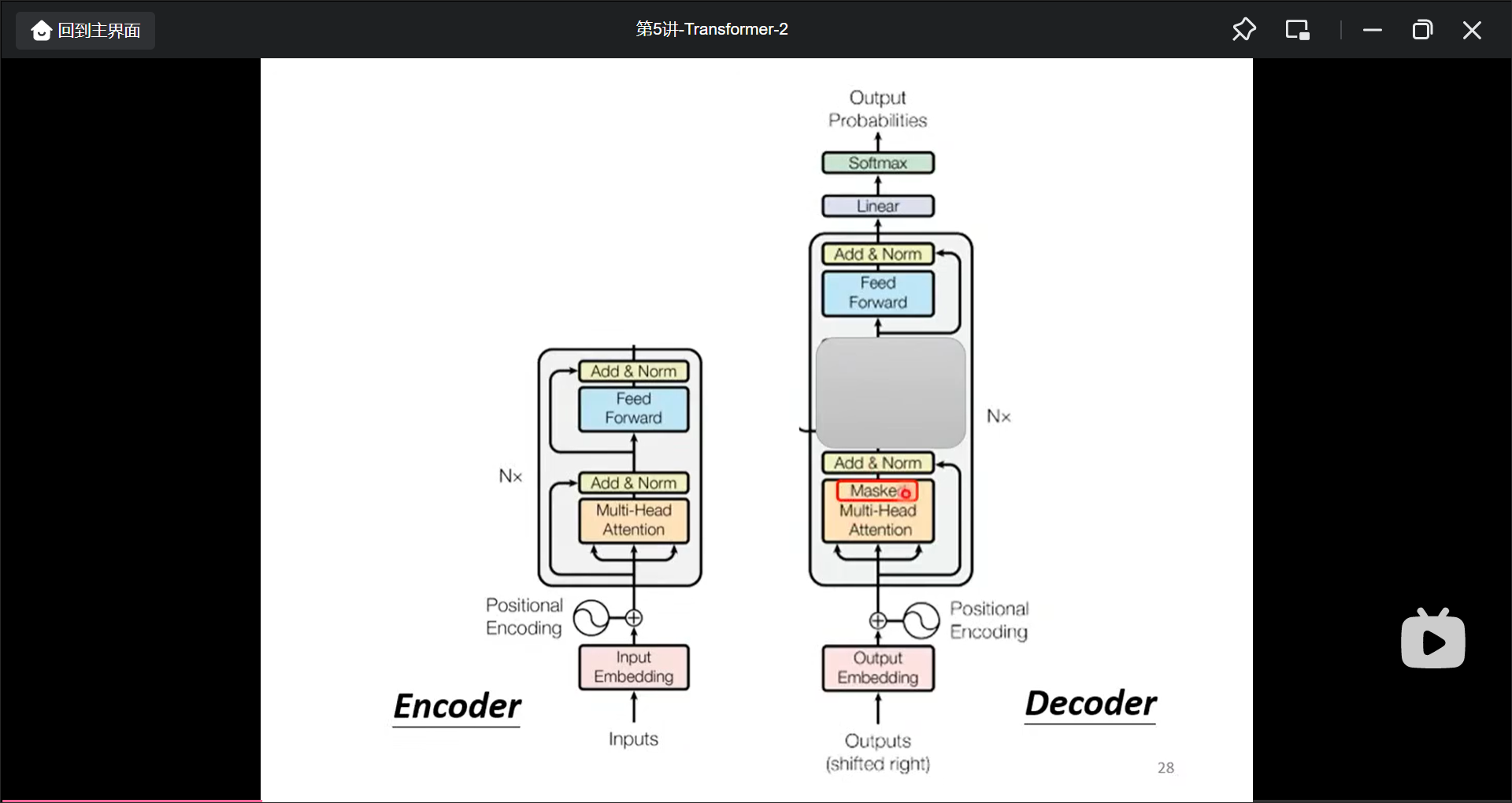
- 遮住了灰色部分几乎一样
- Decoder多了一个Masked self-attention部分
Self-attention和Masked Self-attention的区别是, 在考虑当前输出的时候, 只考虑当前输出时间上之前的输入来形成当前的输出, 而不是像Self-attention一样全都考虑(因为在计算b2的时候只产生了a1和a2):
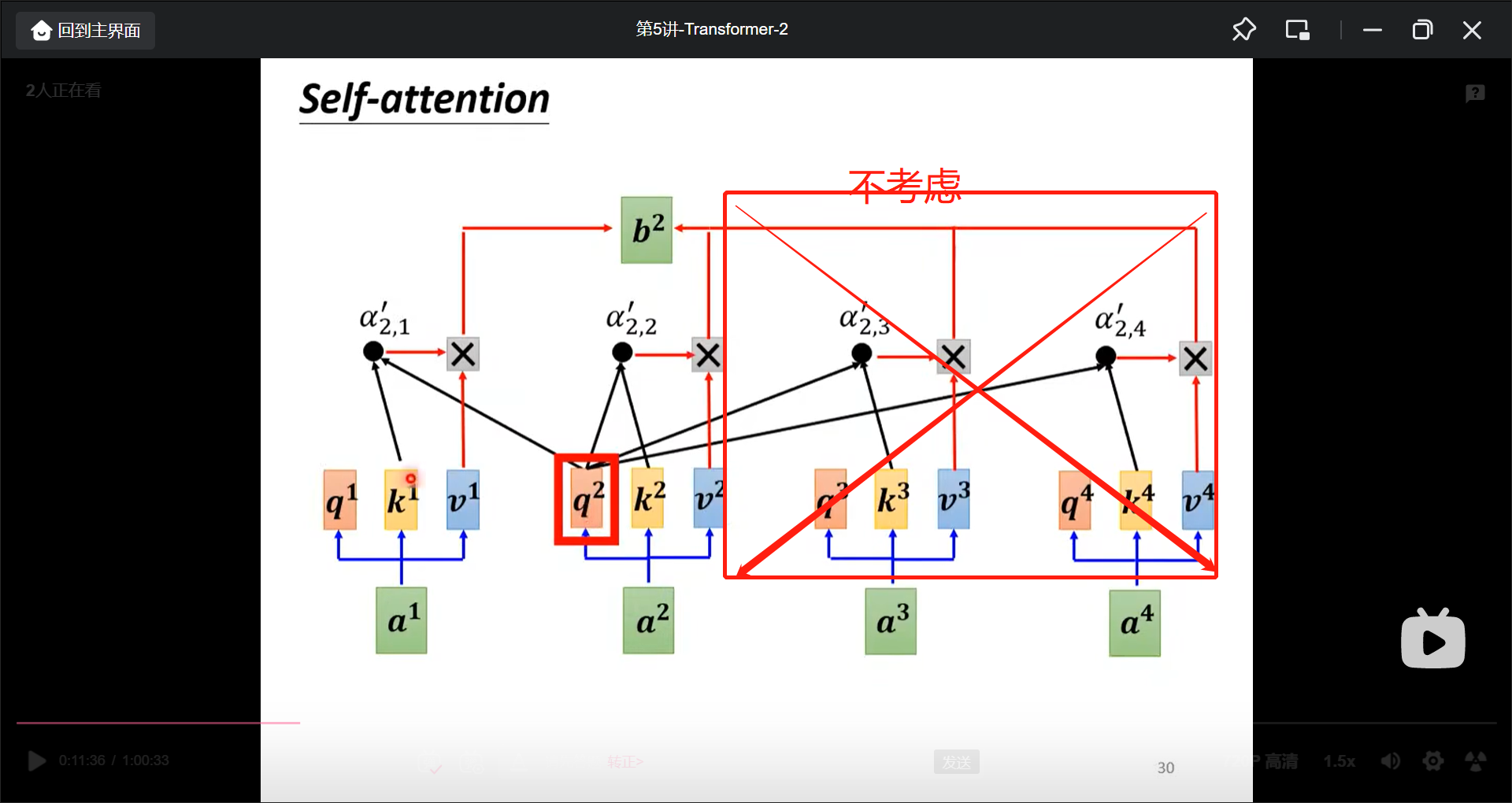
在准备了
Non-autoregressive(NAT)
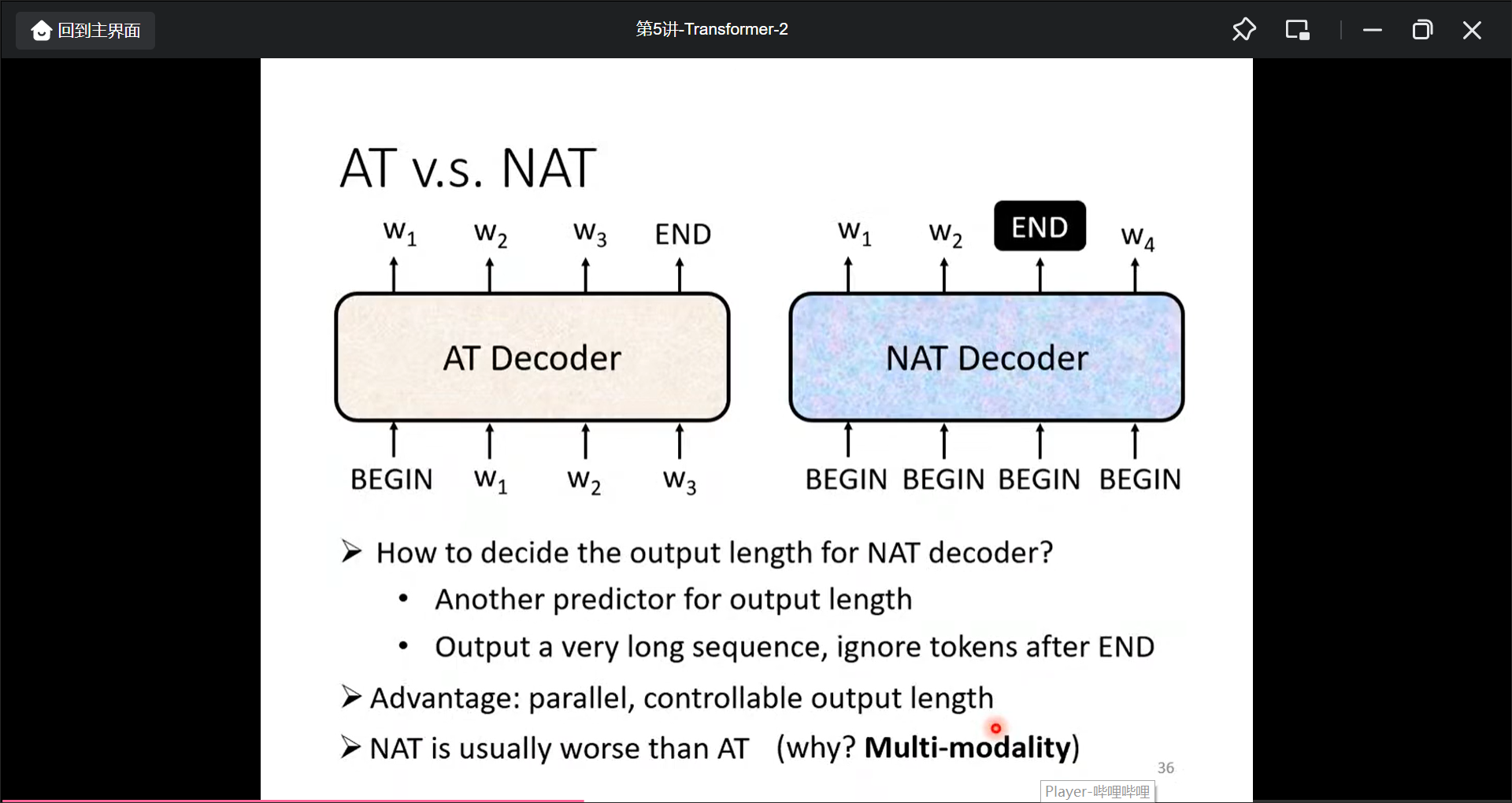
Encoder和Decoder的联系
decoder接受Encoder输入的部分(Cross attention)就是那样:
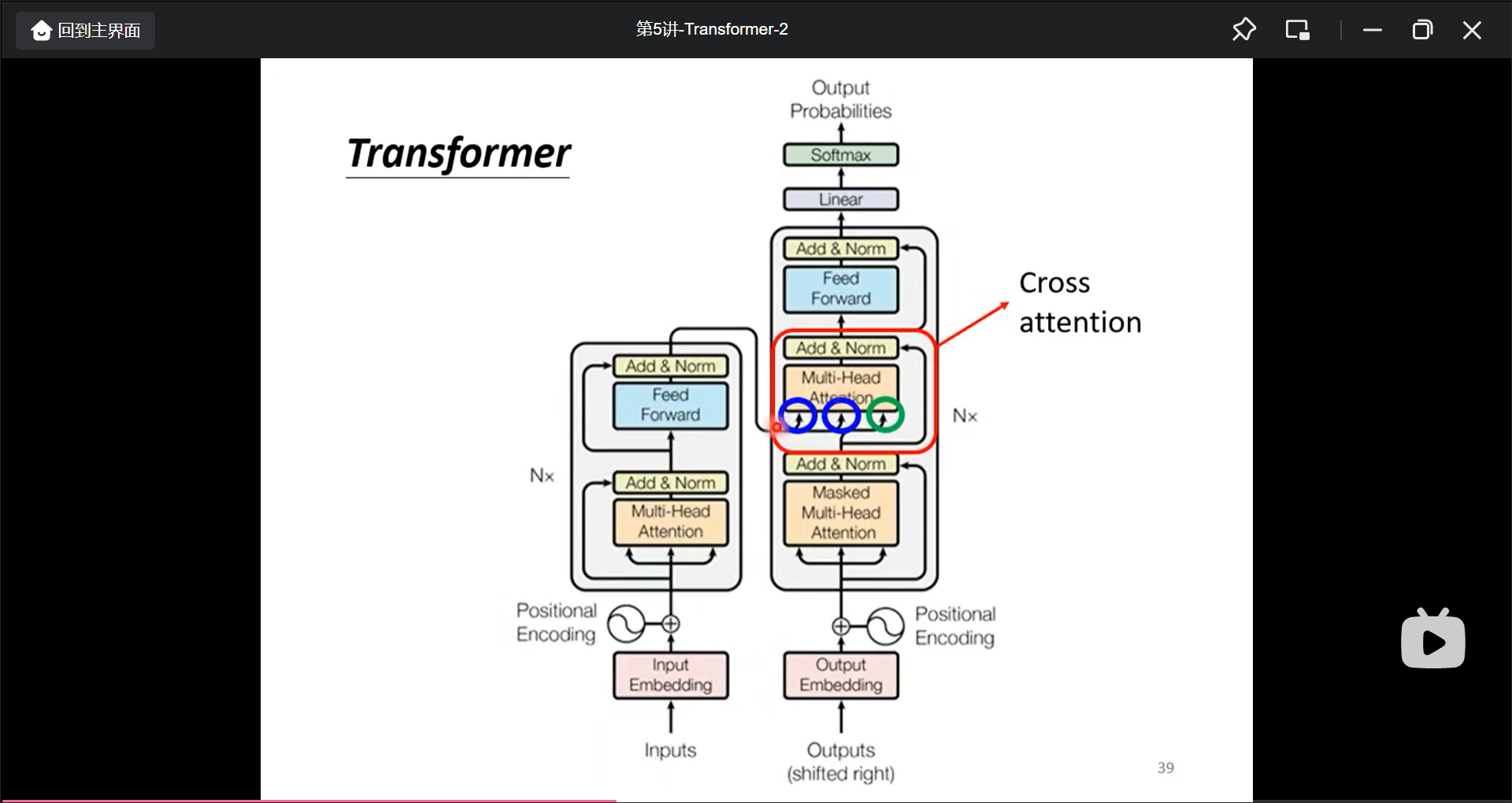
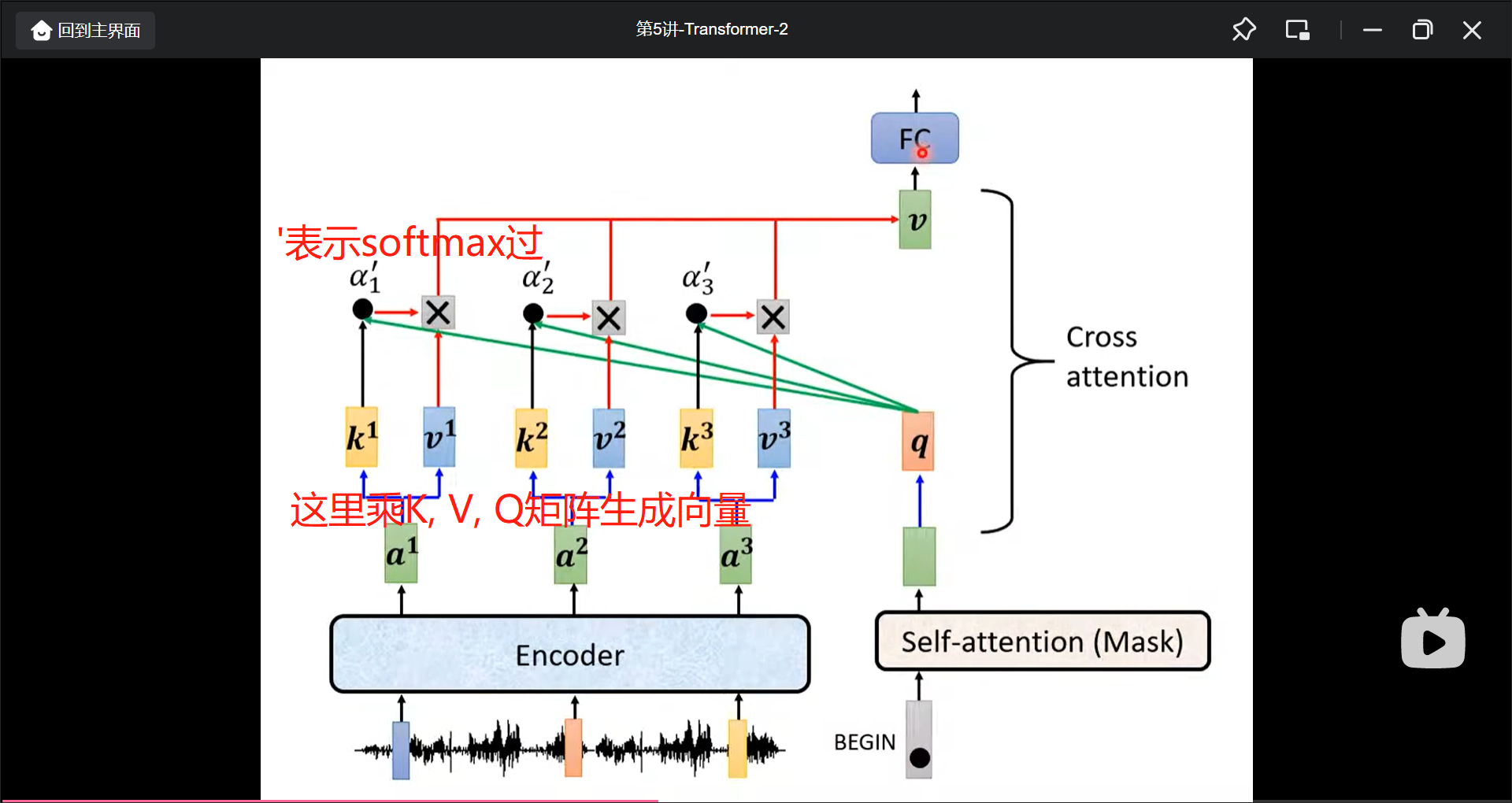
不过先有Cross Attention再有的Self-attention.
但是一定用encoder的最后一层输出做decoder一层的输入吗, 不一定. 还有各种各样的模型组合.
训练(这里一定要再多看):
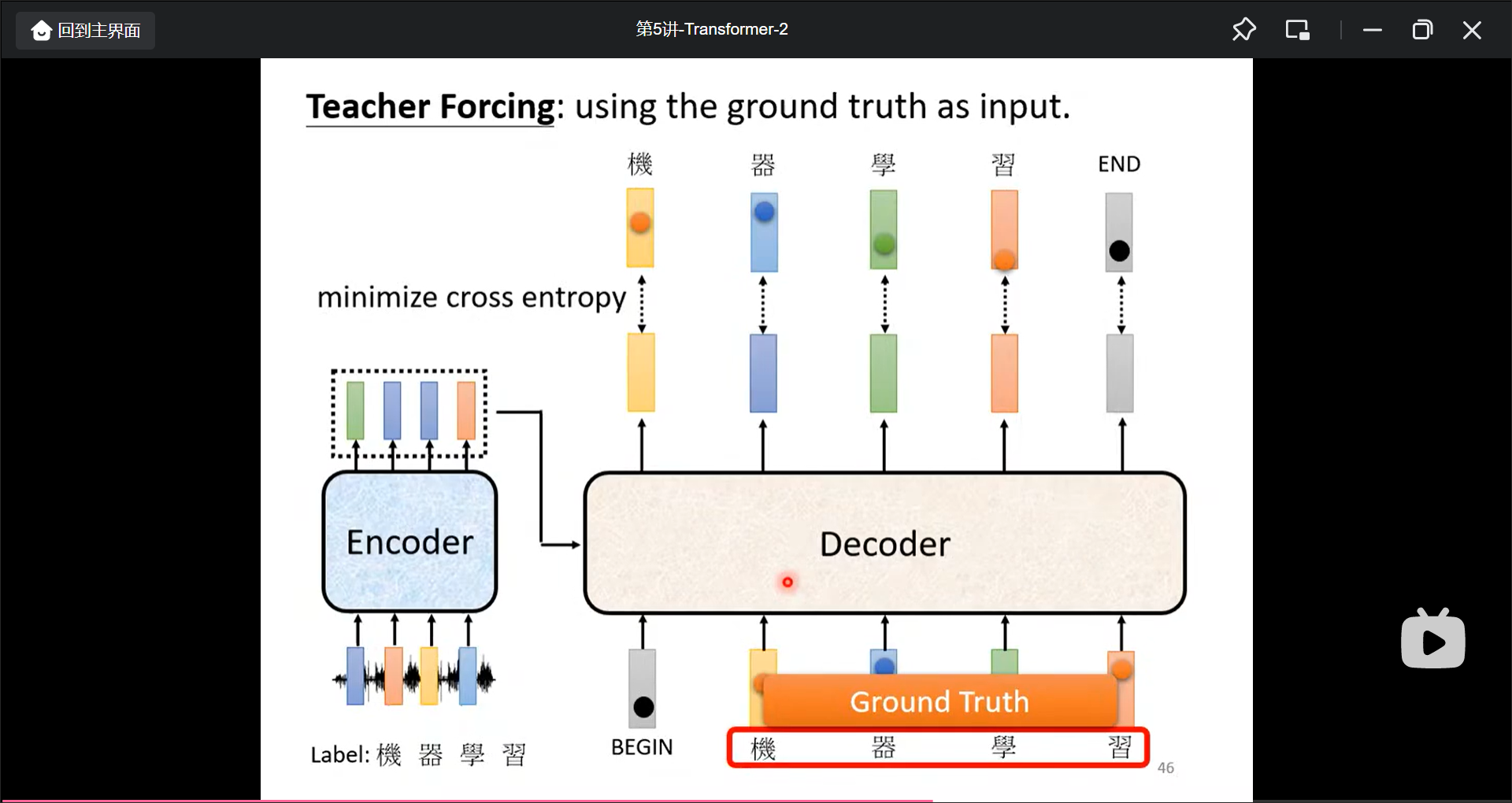
一些训练的Tips:
机器对话从输入里面copy一些数据作为输出

还比如摘要, 也可以从输入做一些copy, 最早的模型是叫做Pointer network.
Guided Attention, 在一些任务, 比如语音识别, TTS时输入和输出需要人为的进行一些aligned, 对attention的结构进行一些固定, 关键词为Monotonic Attention, Location-aware attention.
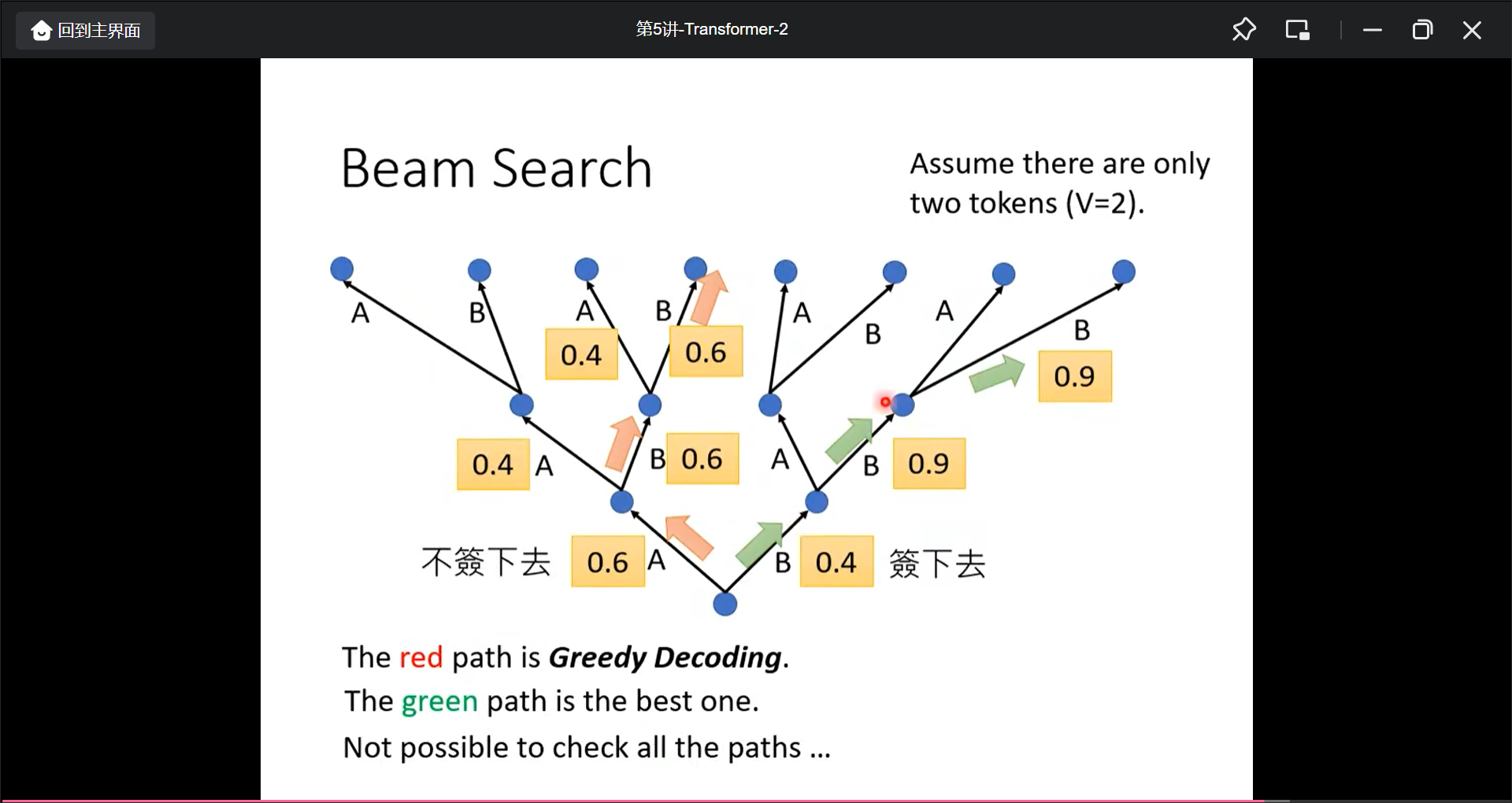
Beam Search
也许第一步选择小的概率后面反而更好一点.
Optimizing Evaluation Metrics
评估方法用BLEU score, 但是没法微分只能用Cross entopy, 但是可以用RL来硬用BLEU score来traing:

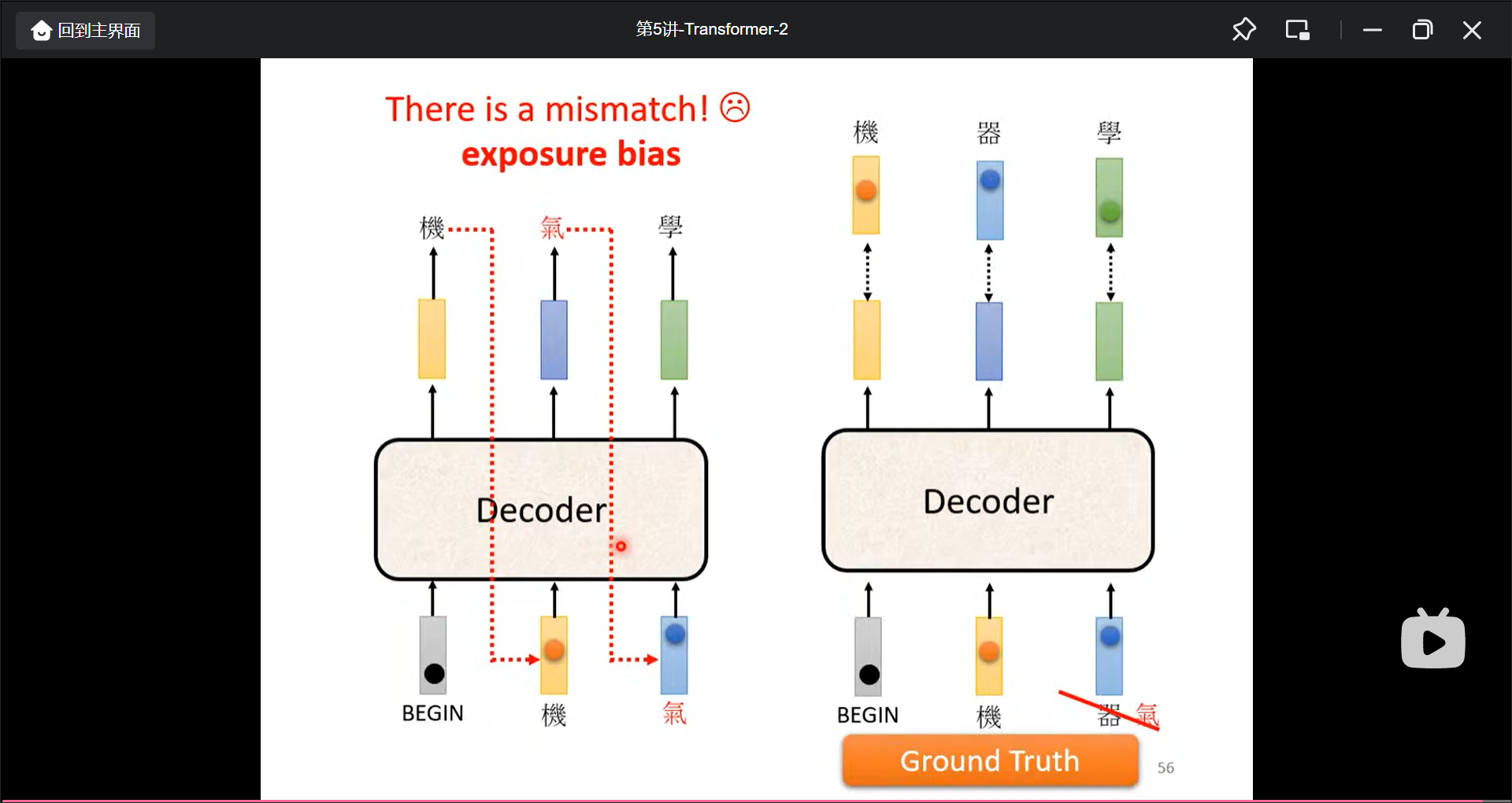
exposure bias
训练的时候是用对的答案来矫正, 但是在真正预测的时候预测的结果可能不是正确的, 所以会一步错, 步步错, 优化方法就是在traing的时候投入一些不好的数据, 训练出来在测试数据中反而更好:
自注意力机制类别总结
第6讲 GAN
生成式对抗网络(GAN)-1
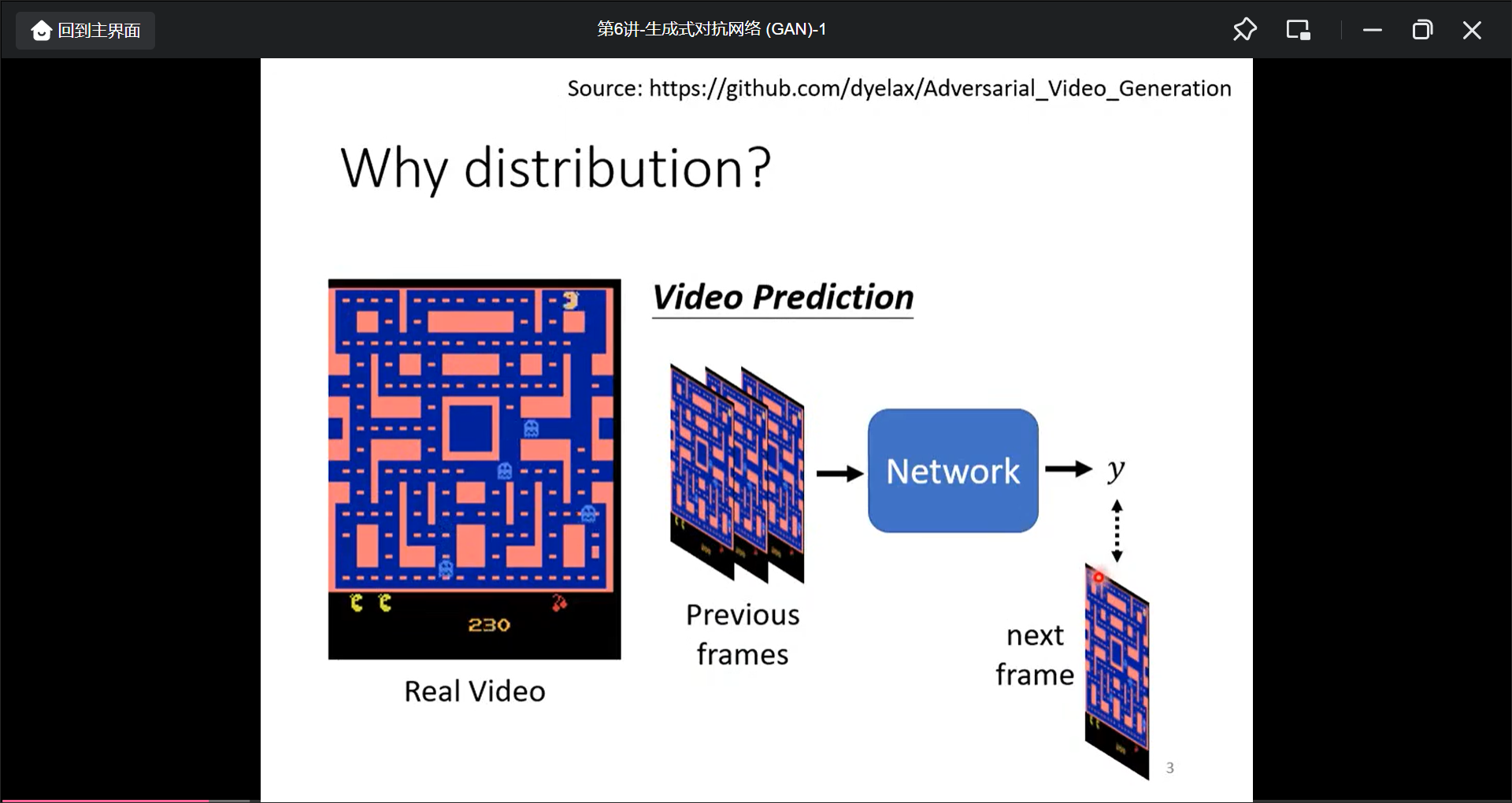
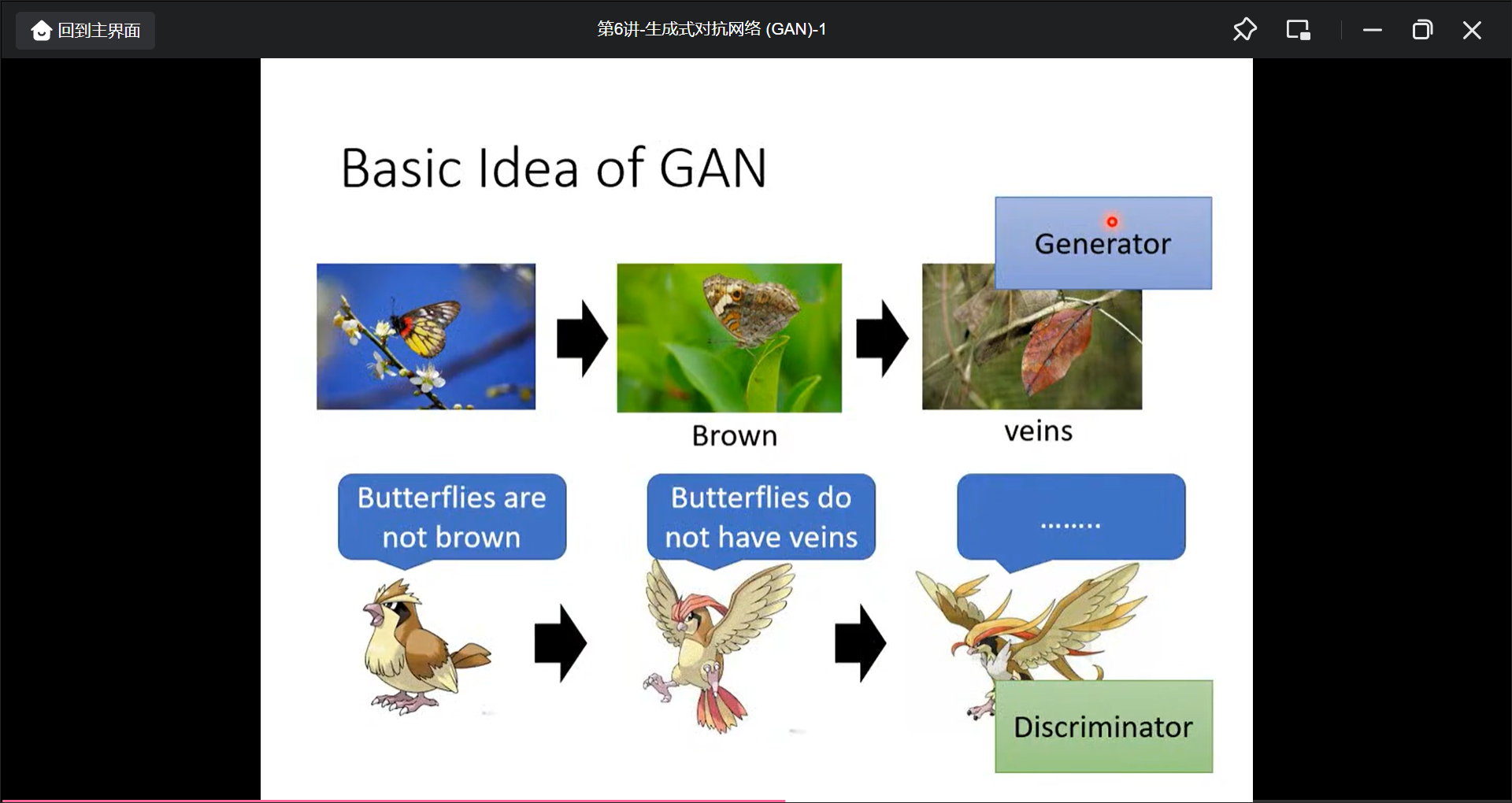
当任务的具有创造性的时候,就需要用生成模型, 具体的说, 就是同一个模型输出是不固定的, 常见的任务有:
- Drawing
- Chatbot
生成模型最常见的模型是: Generative Adversarial Network(GAN).有很多GAN(the-gan-zoo)
Distribution选个简单的就好, 模型会自动把分部对应成不同的输出.
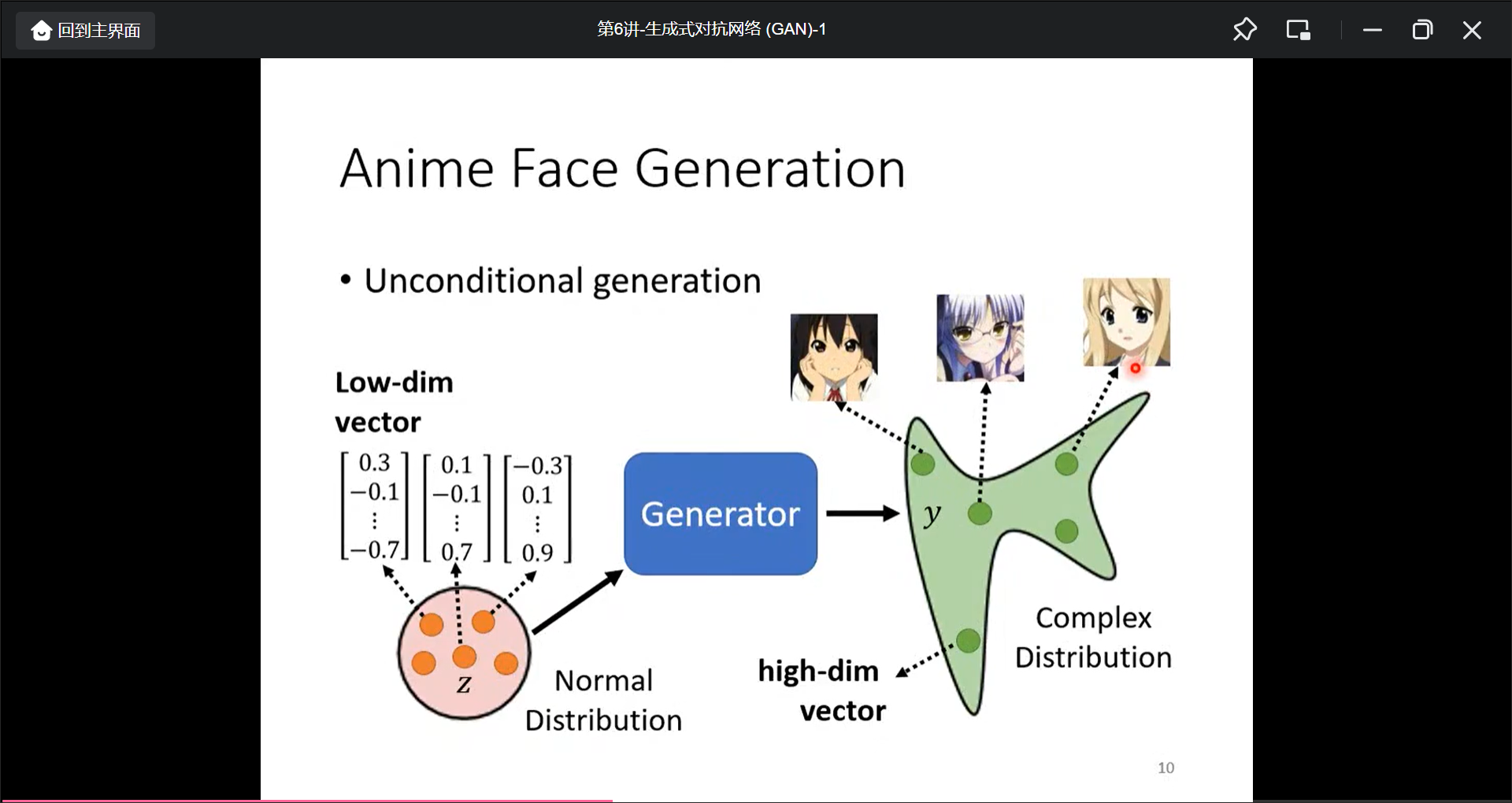
除了Genrator之外, 还需要训练一个Discriminator(输入图片,输出一个数字, 意义是评价二次元图片真实程度):
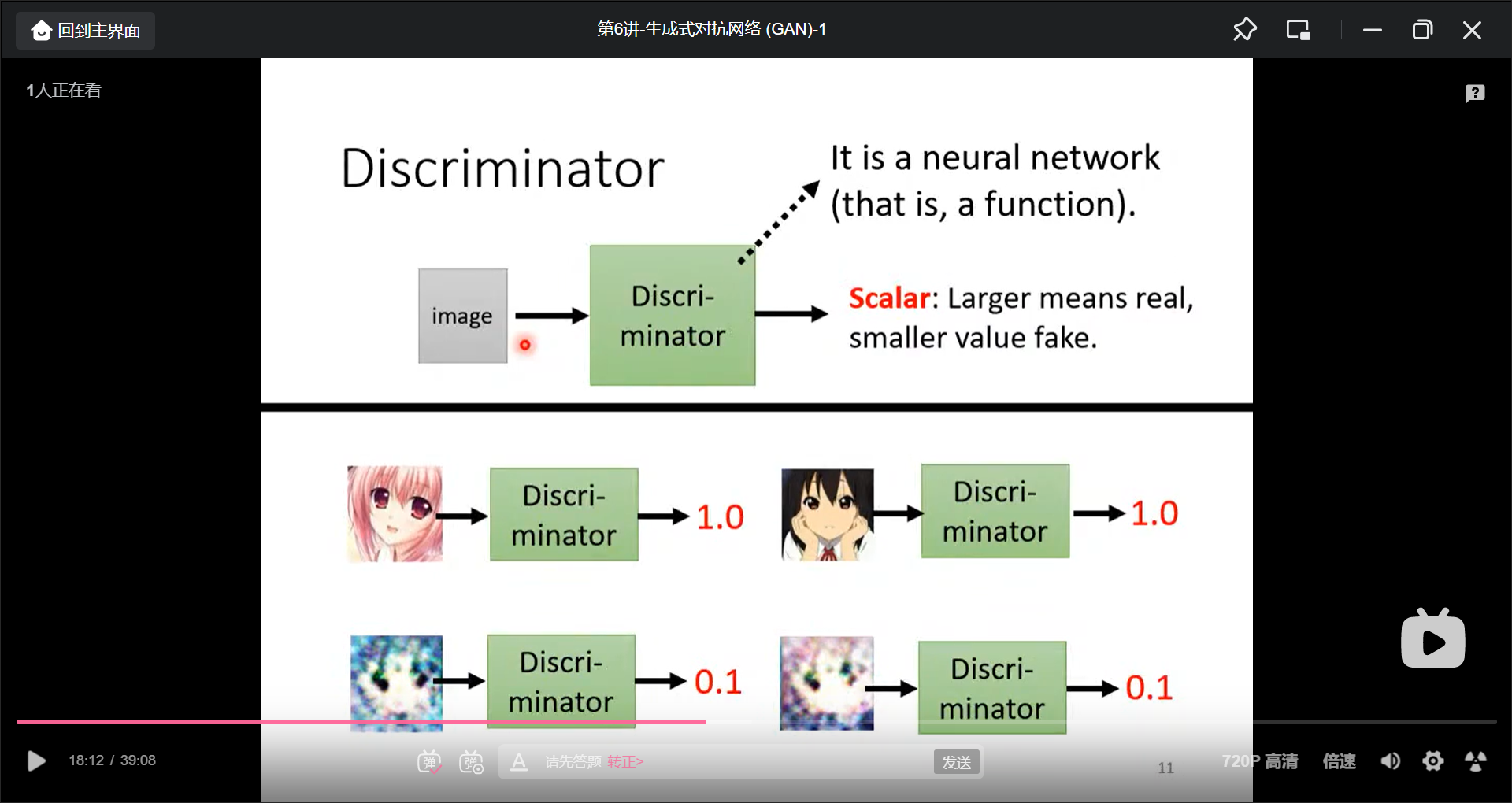
Discriminator就像是Generator的天敌:
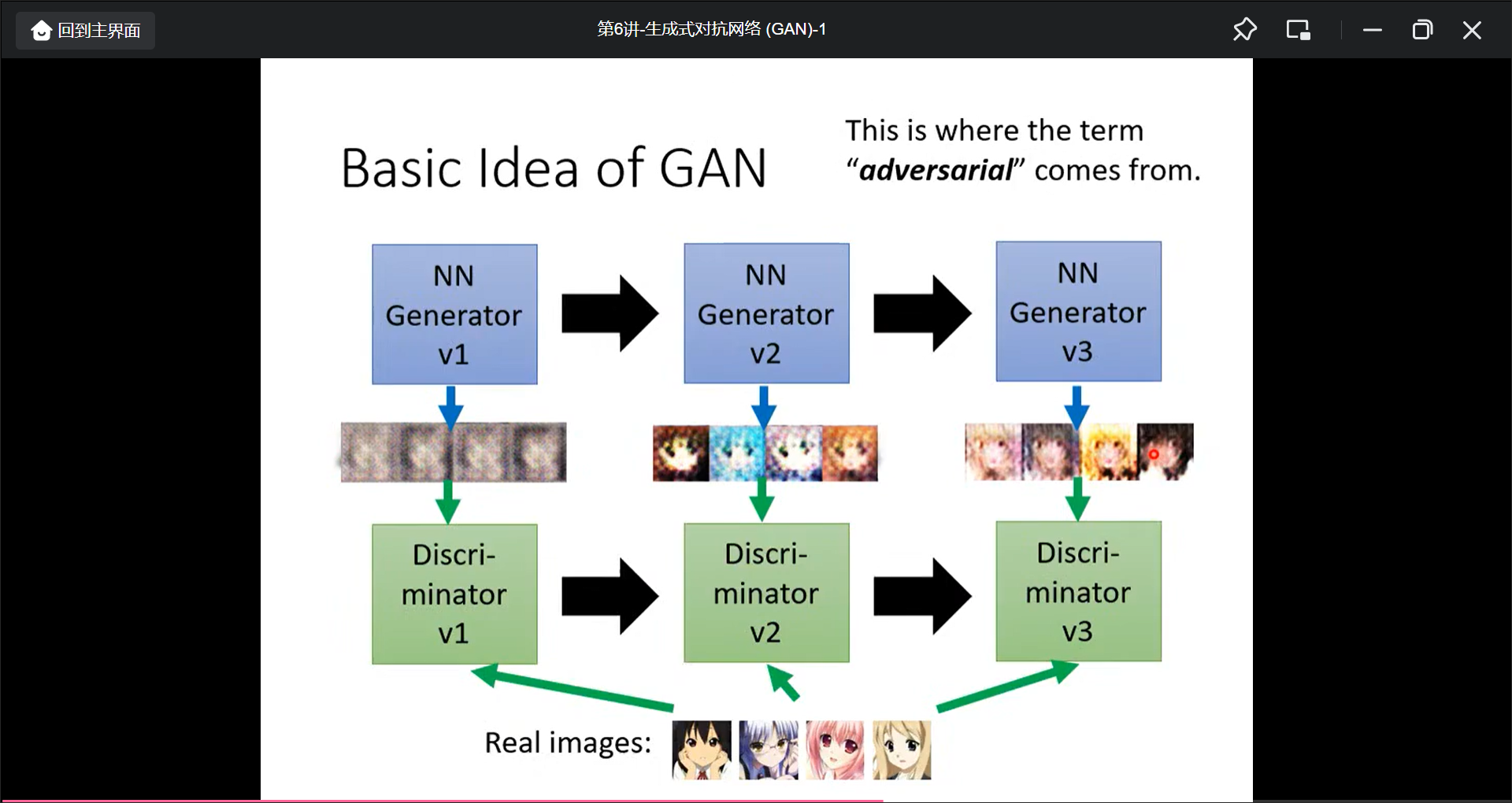
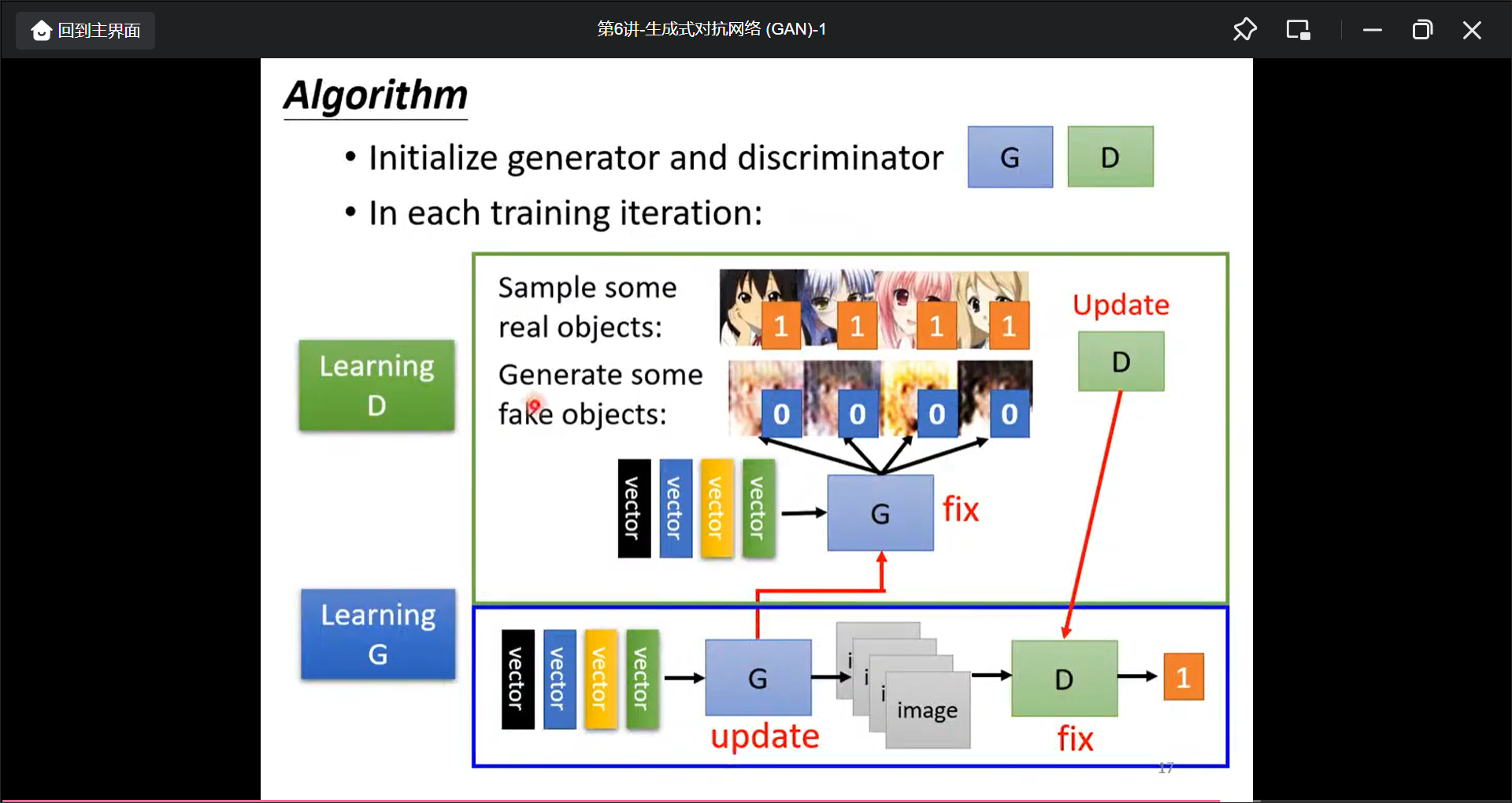
训练过程:
- 固定G, 然后输入vector让G产生假图片, 然后喂给真图和假图训练D可以识别出真假图
- 固定D, 然后输入vector让G生成图片, 然后目标让D的分数变大(也就是让D识别不出假).
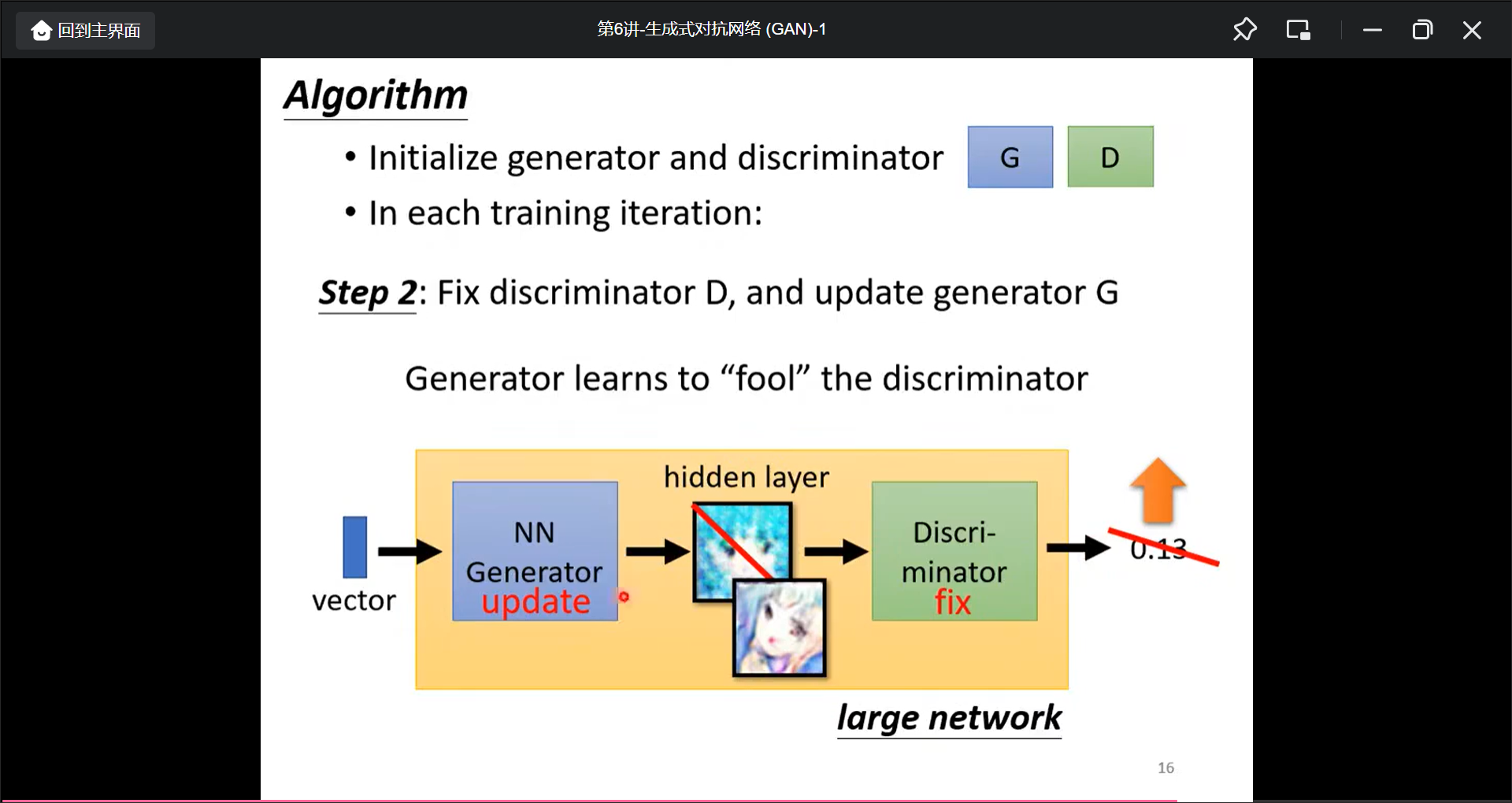
- 循环
李宏毅训练了100次, 还没效果, 1000次开始有眼睛, 2000次开始有嘴巴, 5000次开始逐渐轮廓, 20000次基本就有了, 50000次基本能看了.
如果对输入的向量做一些内叉, 输出也会有对应:

生成式对抗网络(GNN)-2
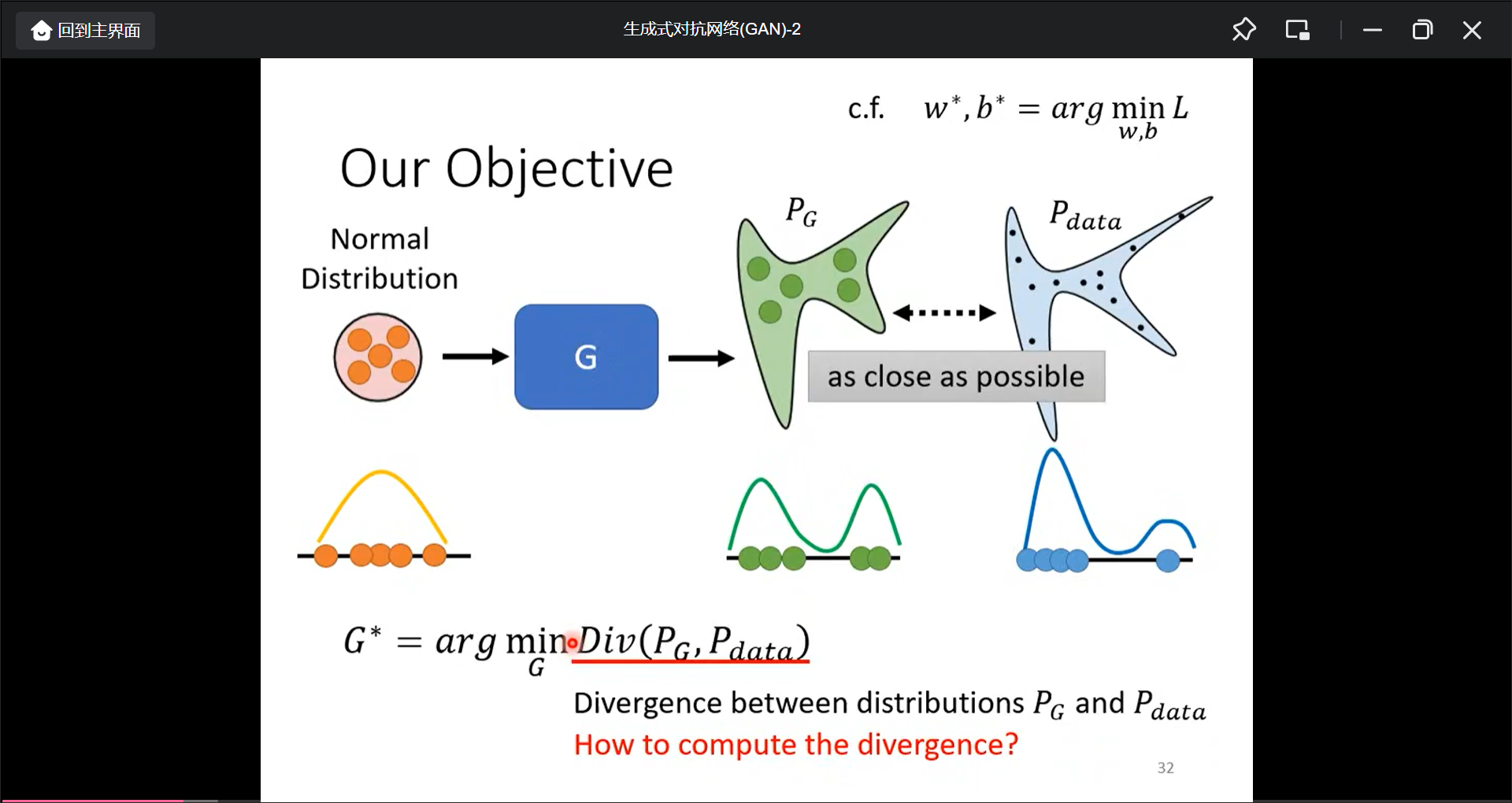
问题是如何计算这种divergence?GAN就是可以解决, 最大化Obejecttive Function(和divergence是有关的), 我感觉就是把分类问题的交叉熵转换成了一个分数, 而最大化这个分数.

所以, 真假divergenceUI越小, 则方框函数越小, 也就是越难分辨, 同理越大.

最终的数学形式如图:

也可以用其他的divergence对应的Obeject function:
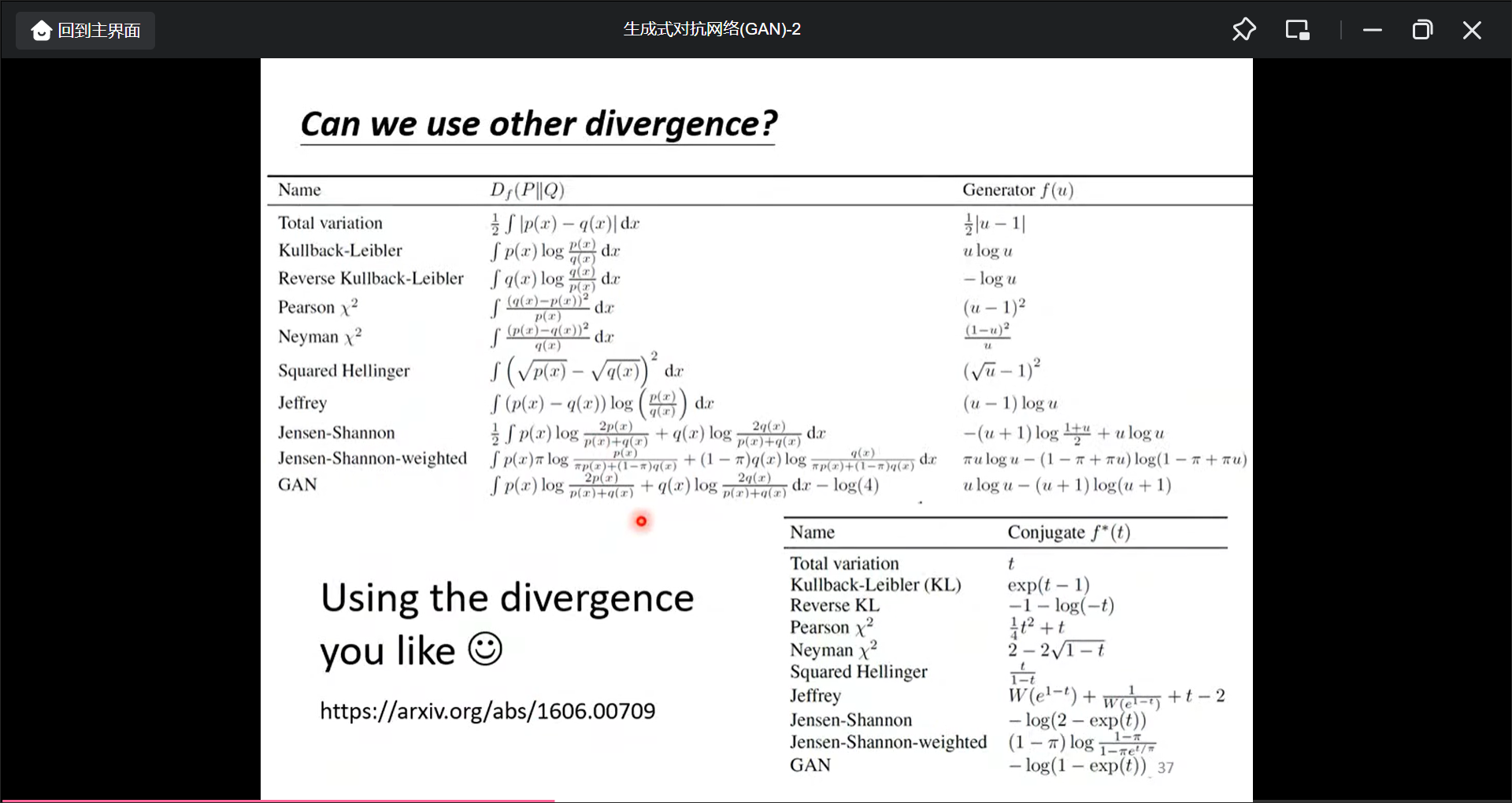
GAN训练的Tips(挑一个最著名的W Gan):
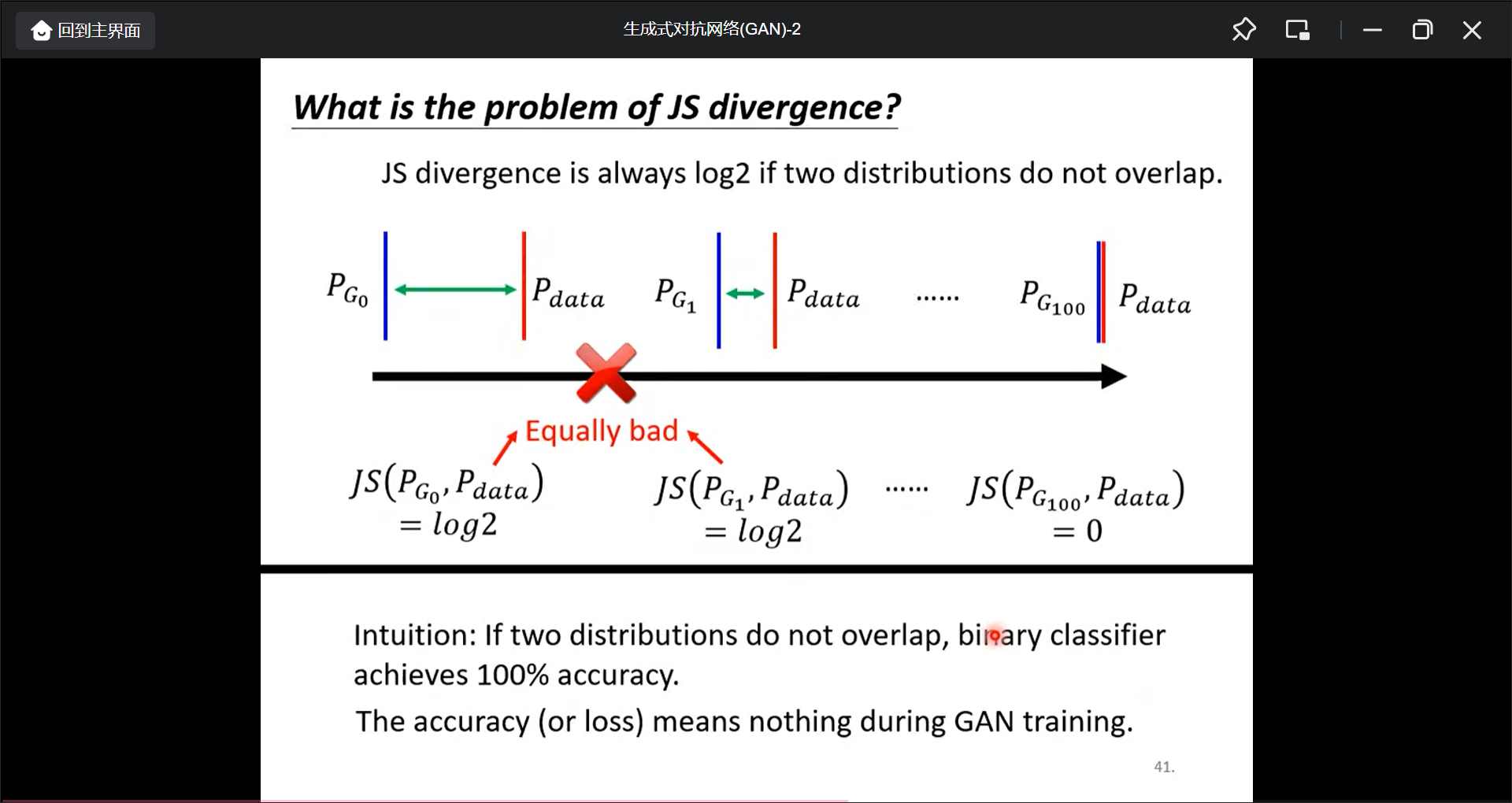
首先, 讲一下JS divergence:
JS divergence在$P_G$和$P_{data}$的分布不想交时计算值永远为$log2$.
所以如果两个分布不相交时,永远可以分类出来:
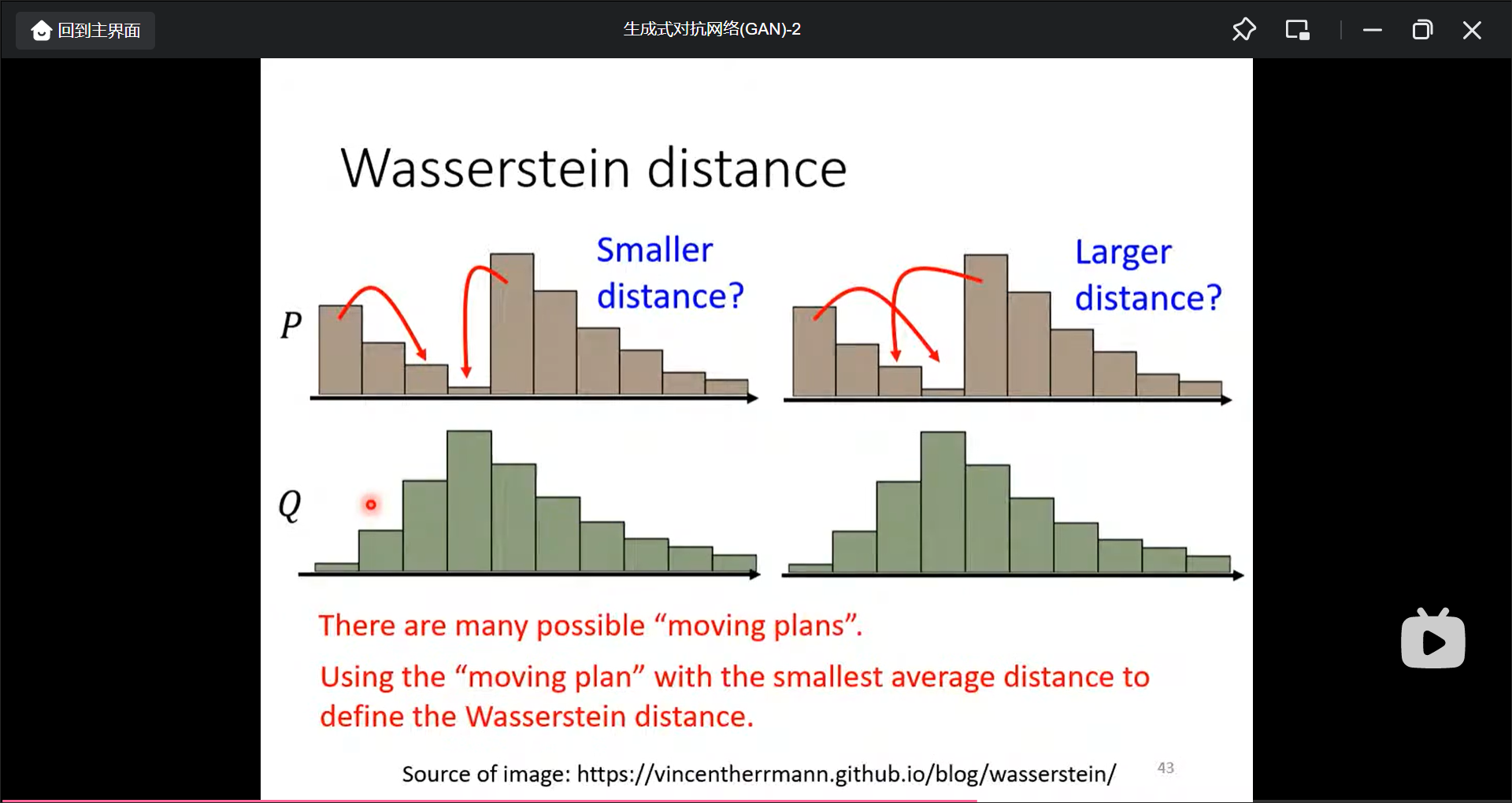
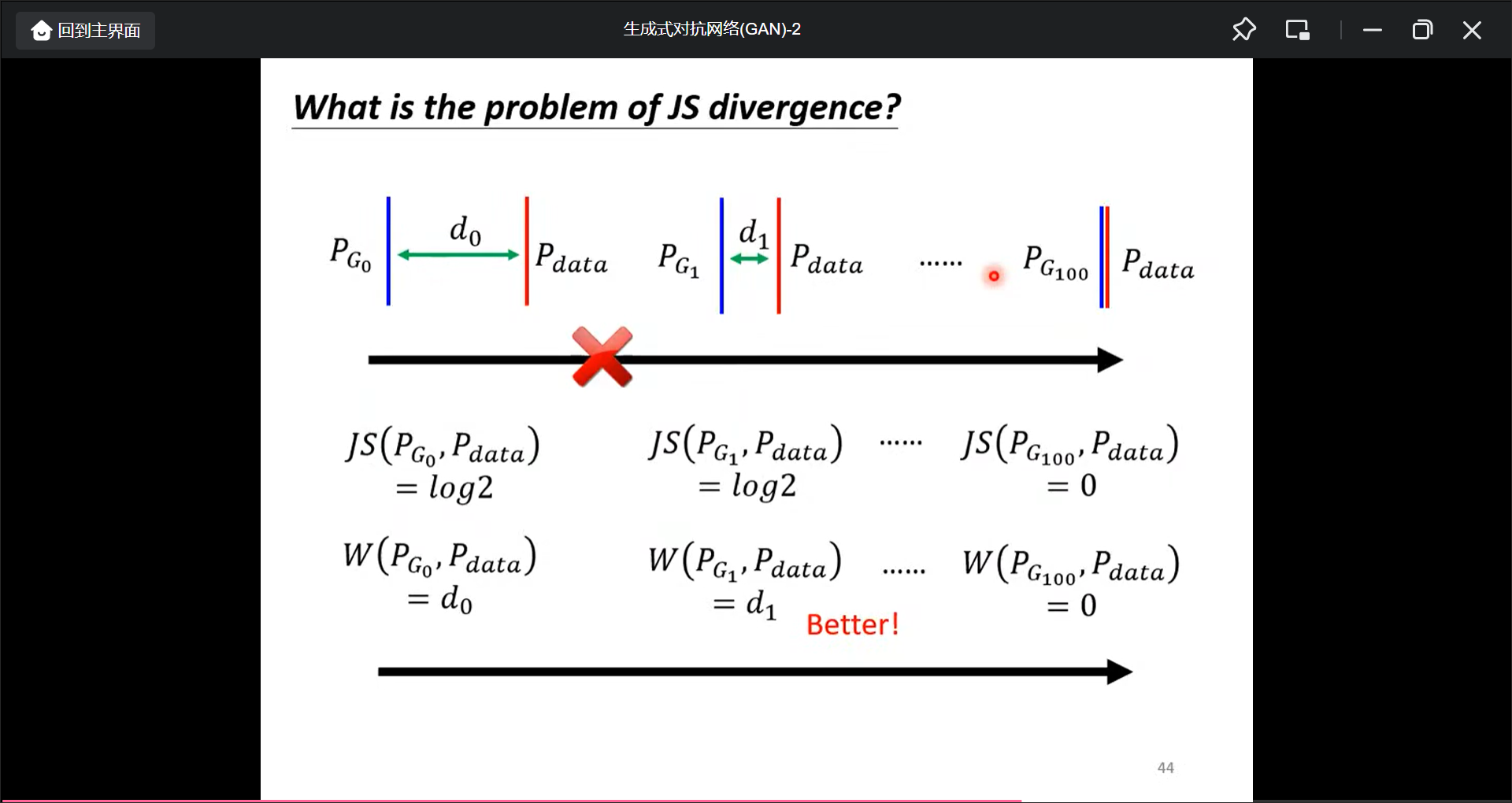
所以改进是用Wasserstein distance.


生成式对抗网络(GNN)-3

GAN for Sequence Generation(Scratch GNN):
其他的生成模型:

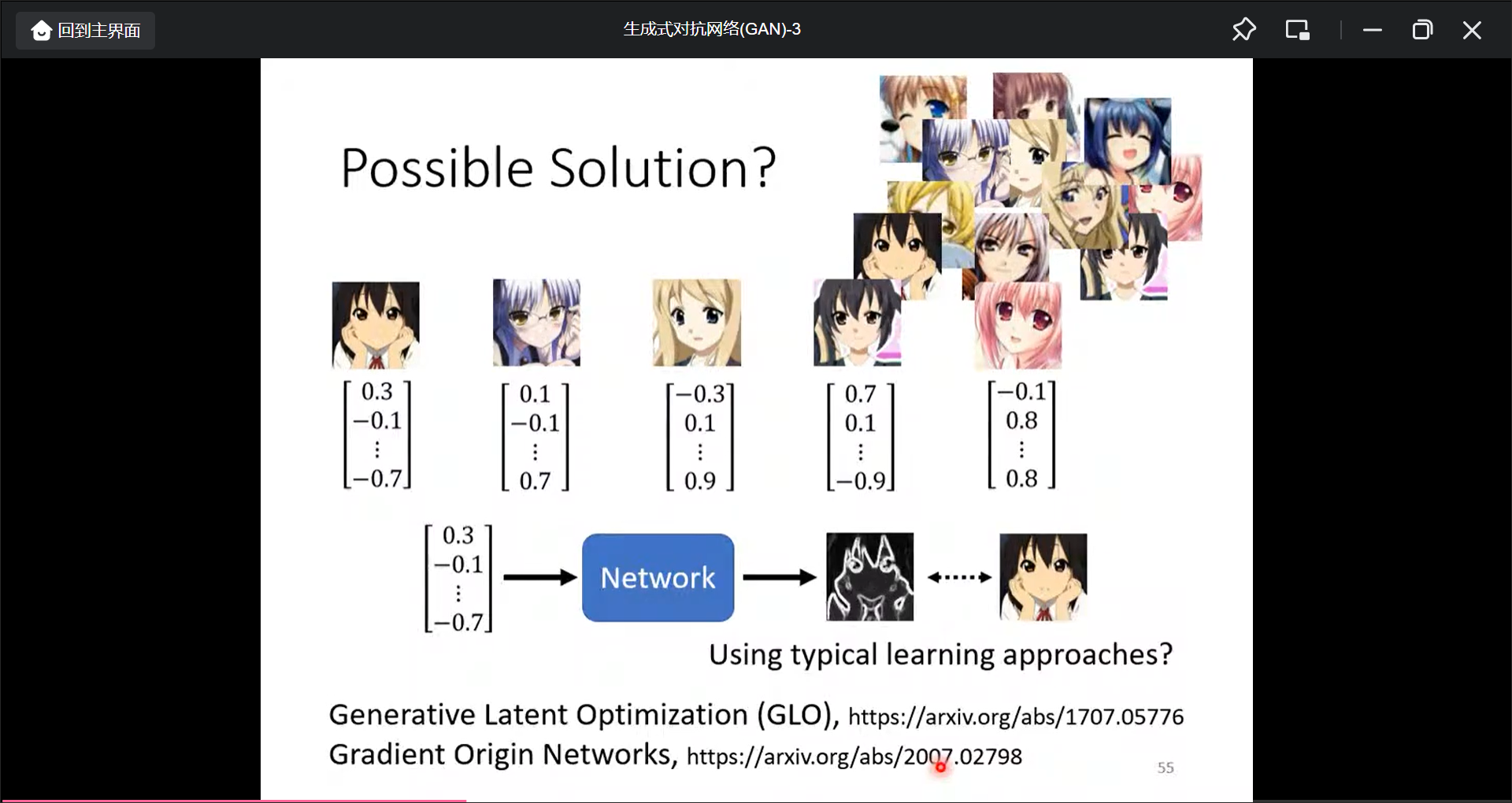
用监督学习的方法生成生成模型:
生成模型的评估:
- 人看
- 跑图片分类, 如果分类越集中, 则更好一点(但是有个问题, 在GNN训练的时候, 只能出现一张很像的图片们, 这时候这个评估不太好了,
mode collapse), 这个问题目前还没解决. More Dropping- 可以
Diversity看一张图片用多个分类器输出的平均, 越平均越好, 具体叫做Inception Score. - 也可以用
FID来评估, 也就是分类前进入softmax前的那个向量, 算各个图片对应的这个向量的距离.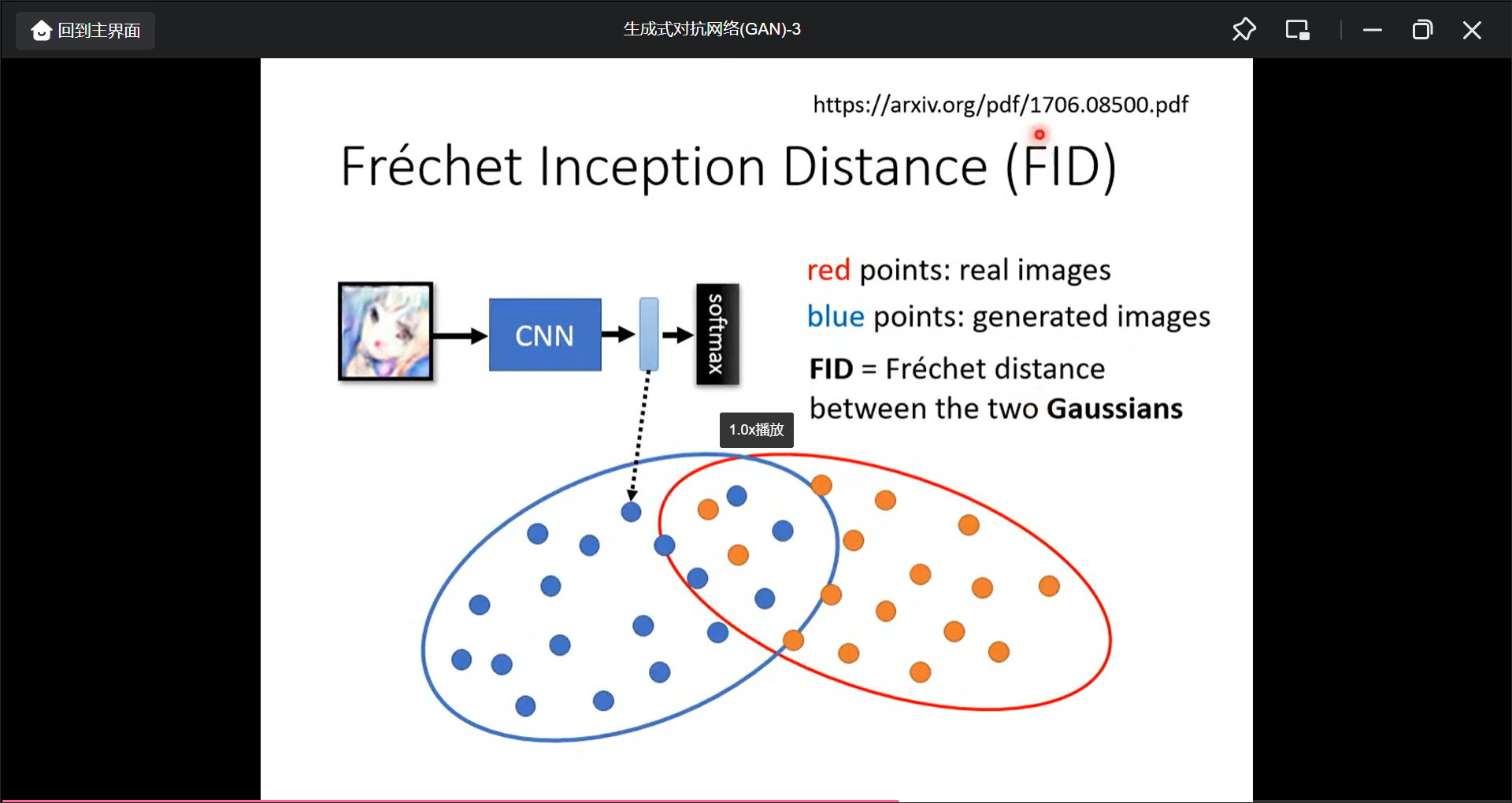
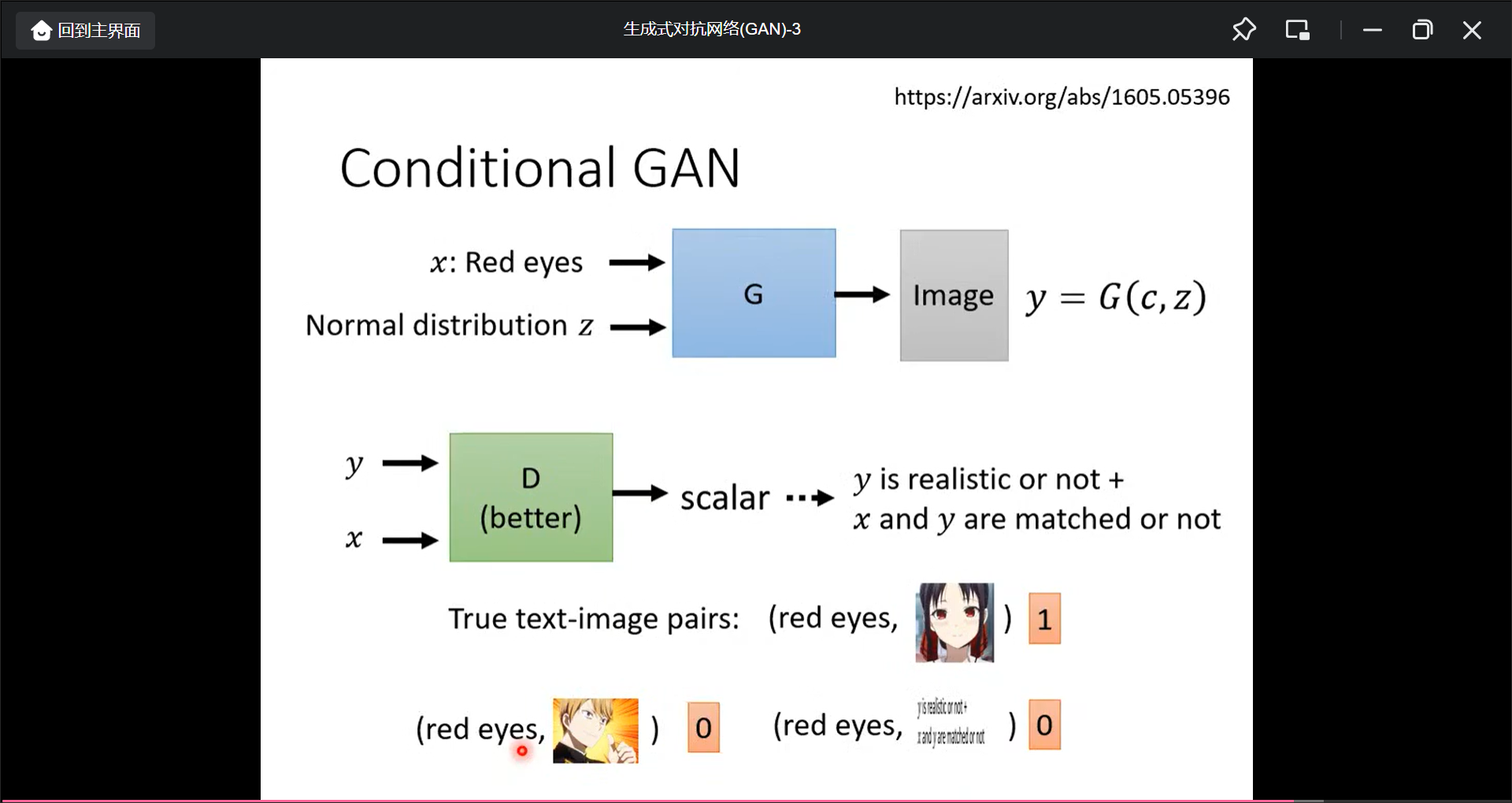
Conditional Generator:
可以操纵Generator的结果,(监督学习), 也就是Text-to-Image:
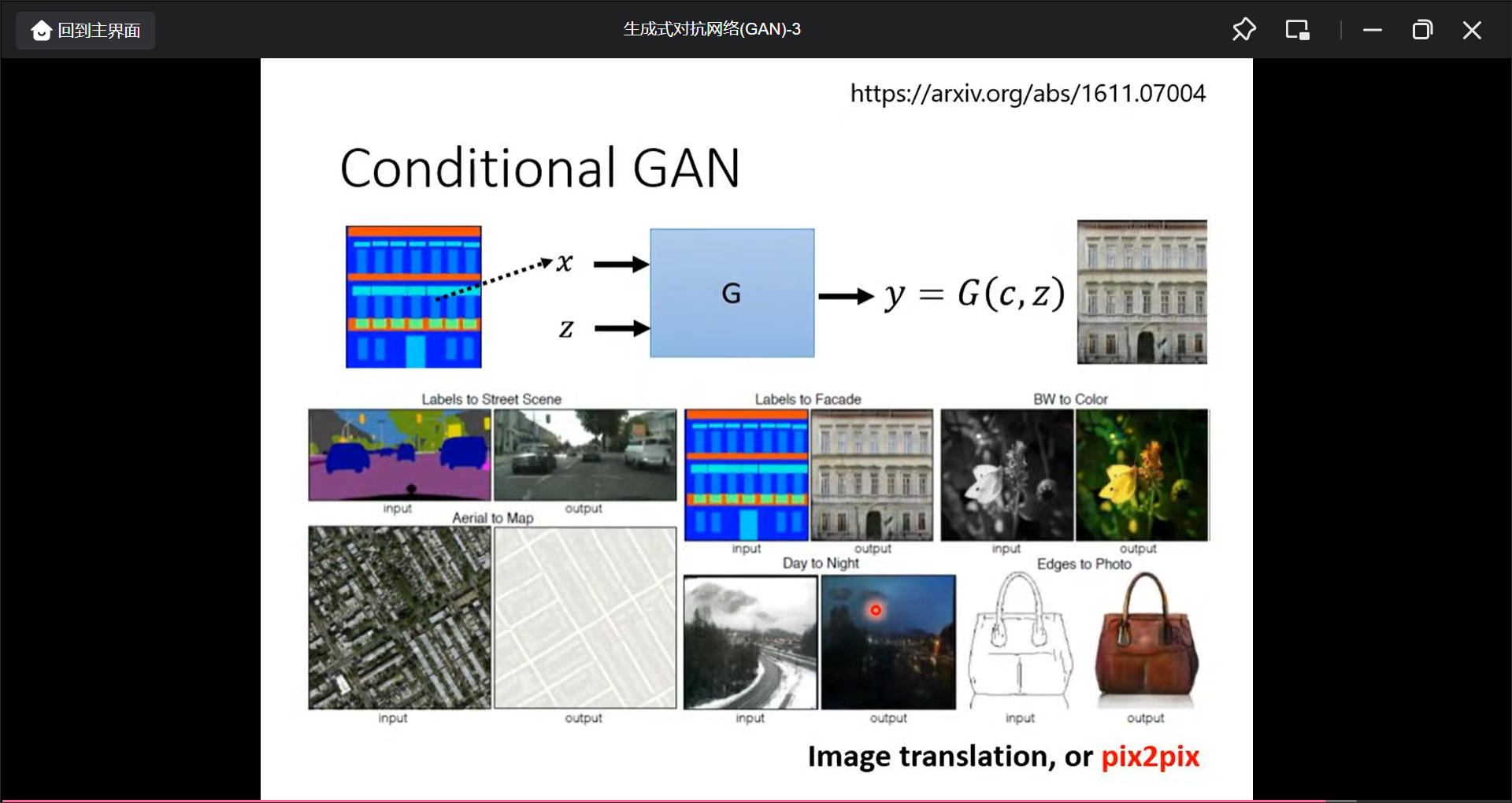
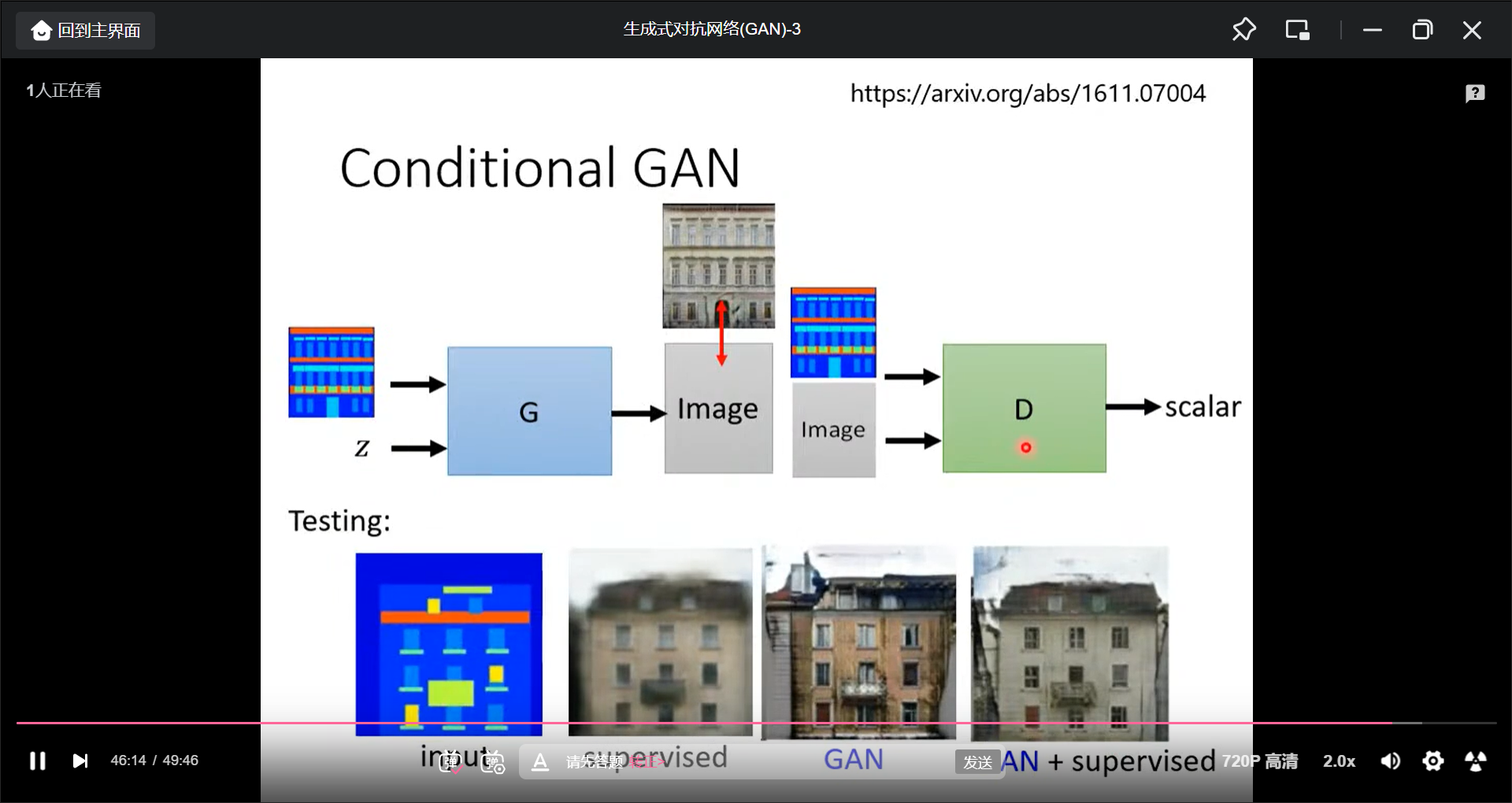
也可以看一张图片, 产生一张图片:
也可以输入声音, 产生图片, 也可以输入一张图片, 产生它的动态图
生成式对抗网络(GNN)-4
用Unspaired Data来训练GNN(比如影像风格转换):
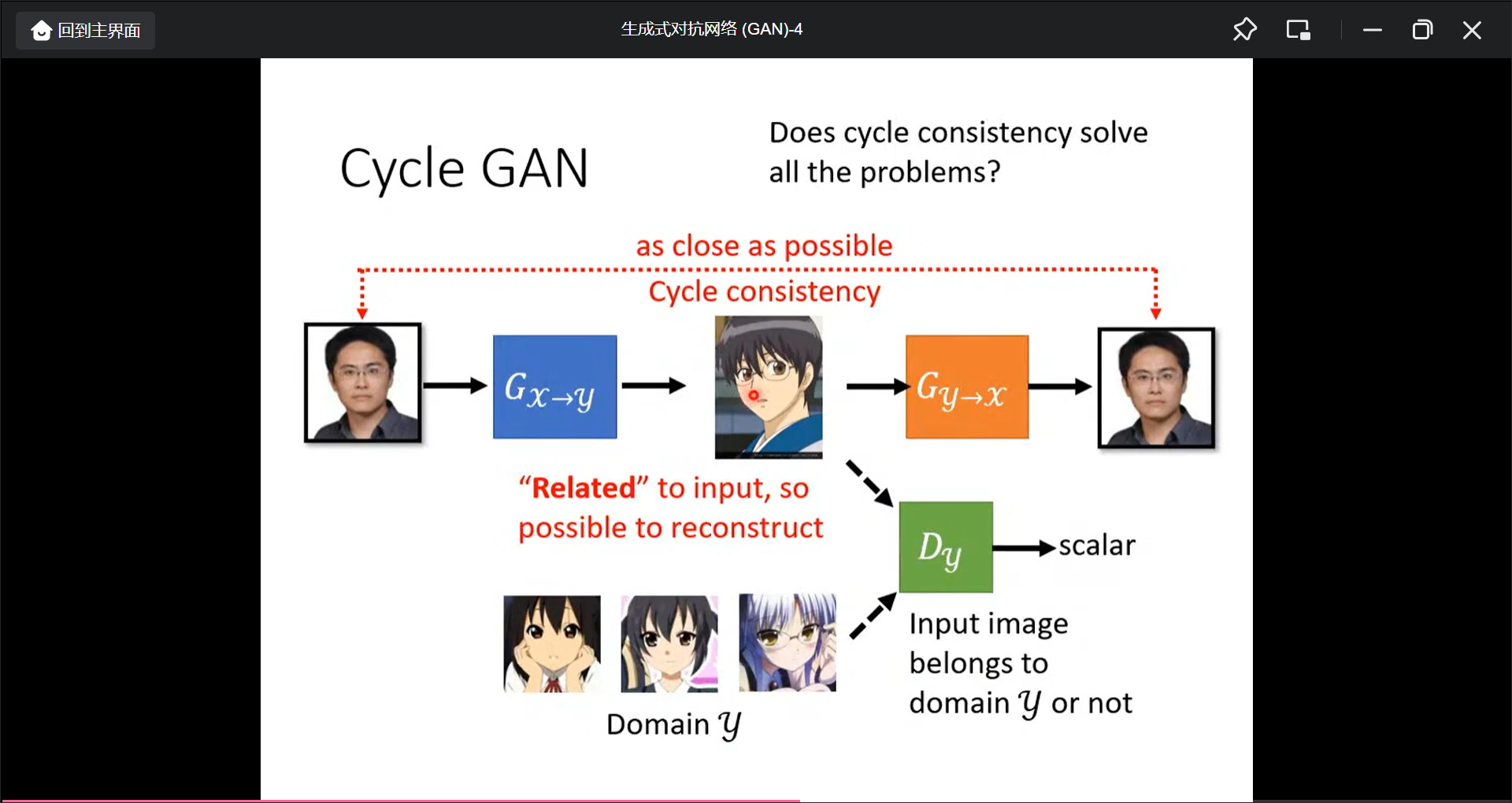
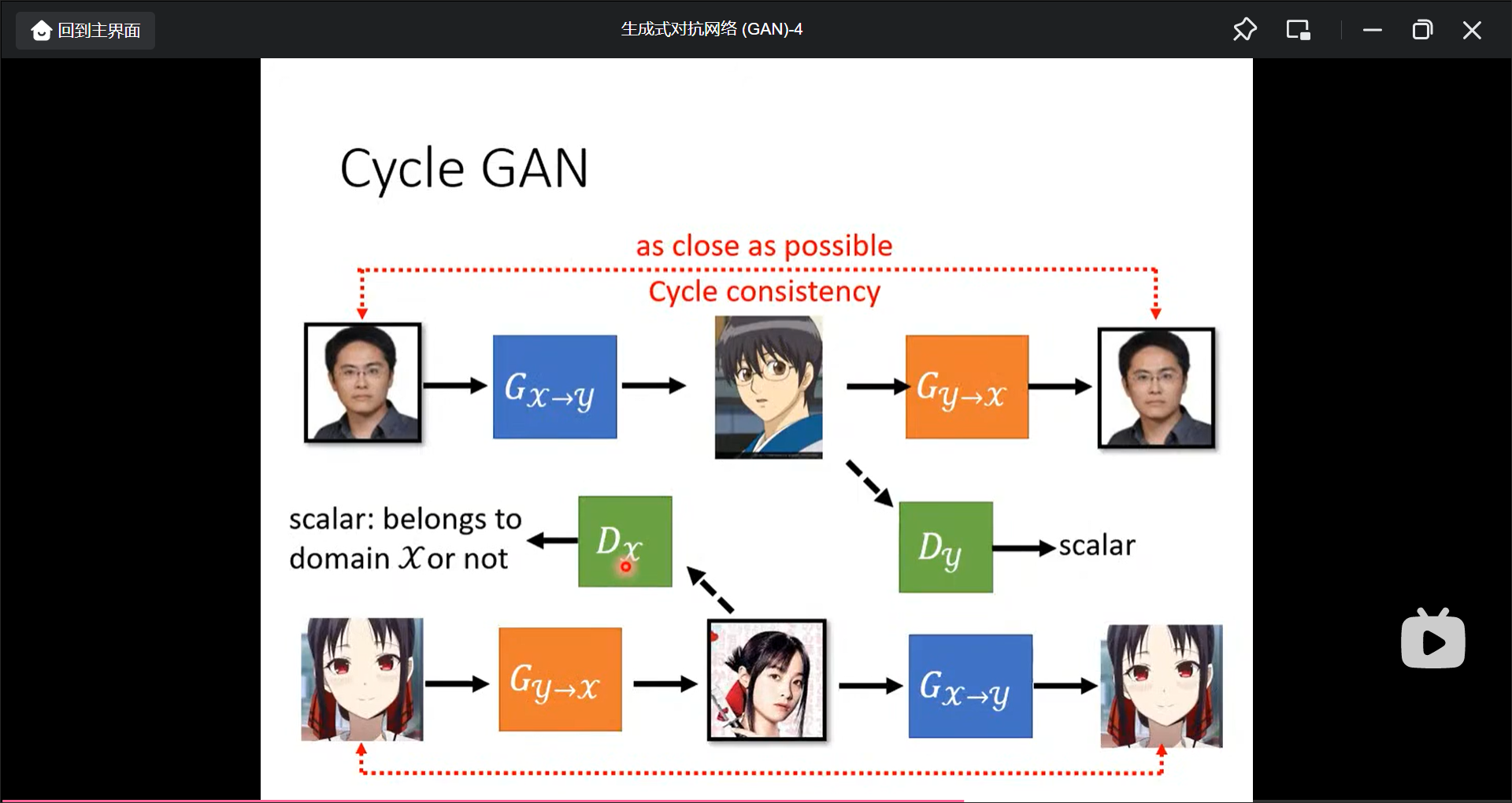
可以在多种风格间做转换:
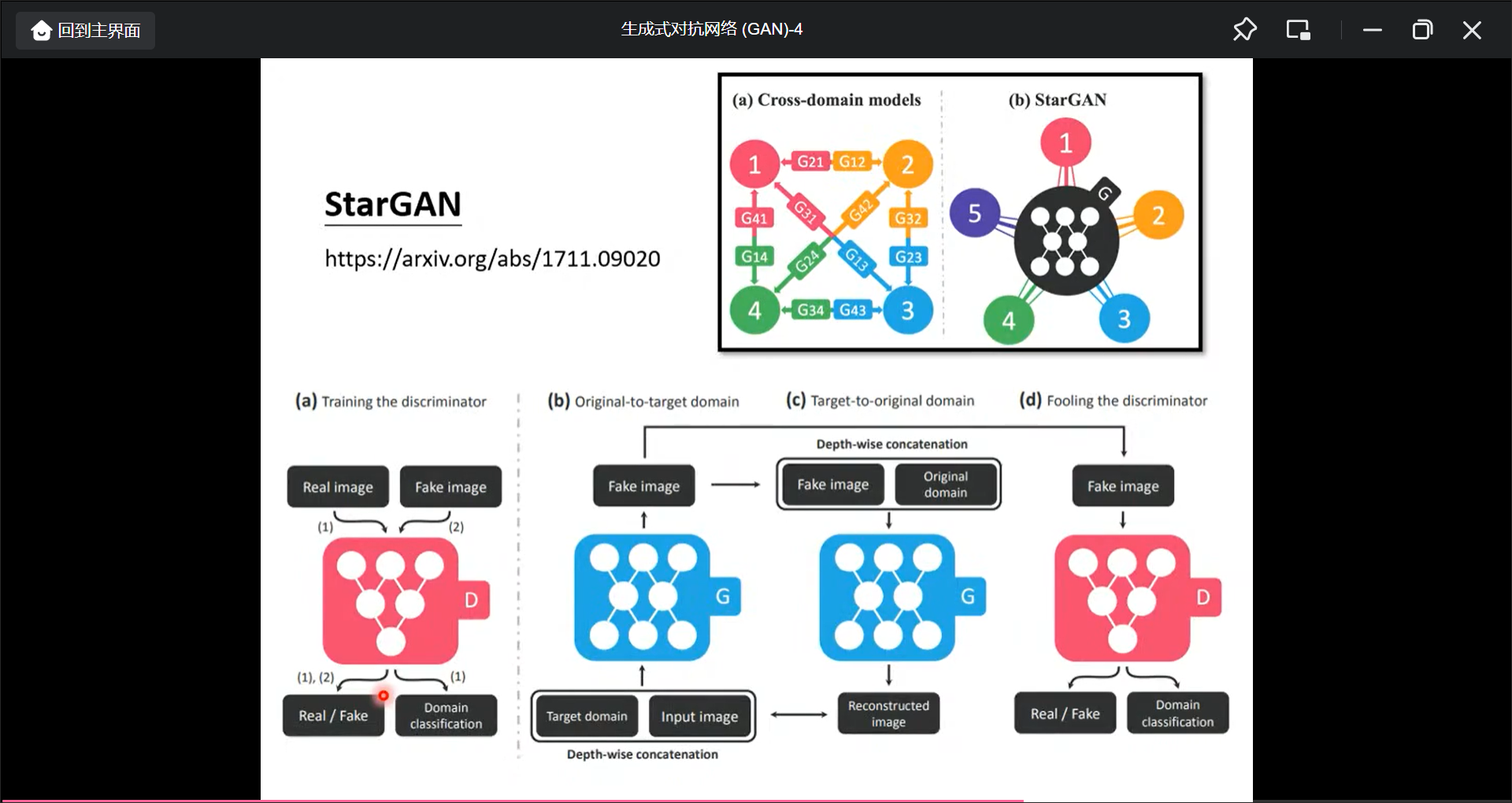
也可以Text-Style-Transfer, 还有其他:
第7讲 自监督学习-BERT
自监督学习(self-surpervised learning)
ELMO:94M
BERT: 340M
GPT-2: 1542M
Megatron: 8B
T5: 11B
Turing NLG: 17B
GPT-3: 10倍 NLG
自监督学习2-BERT介绍
BERT的作用:
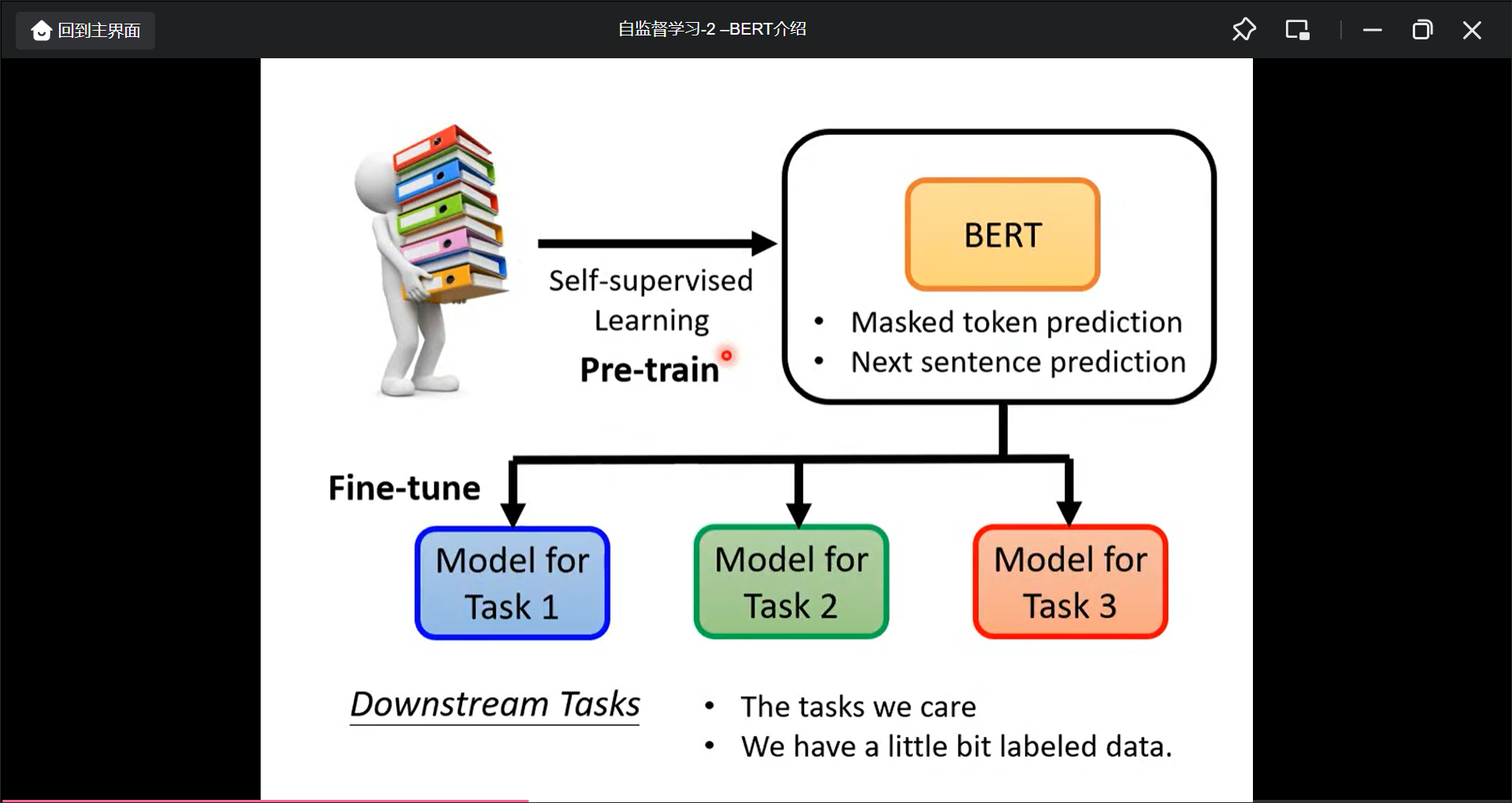

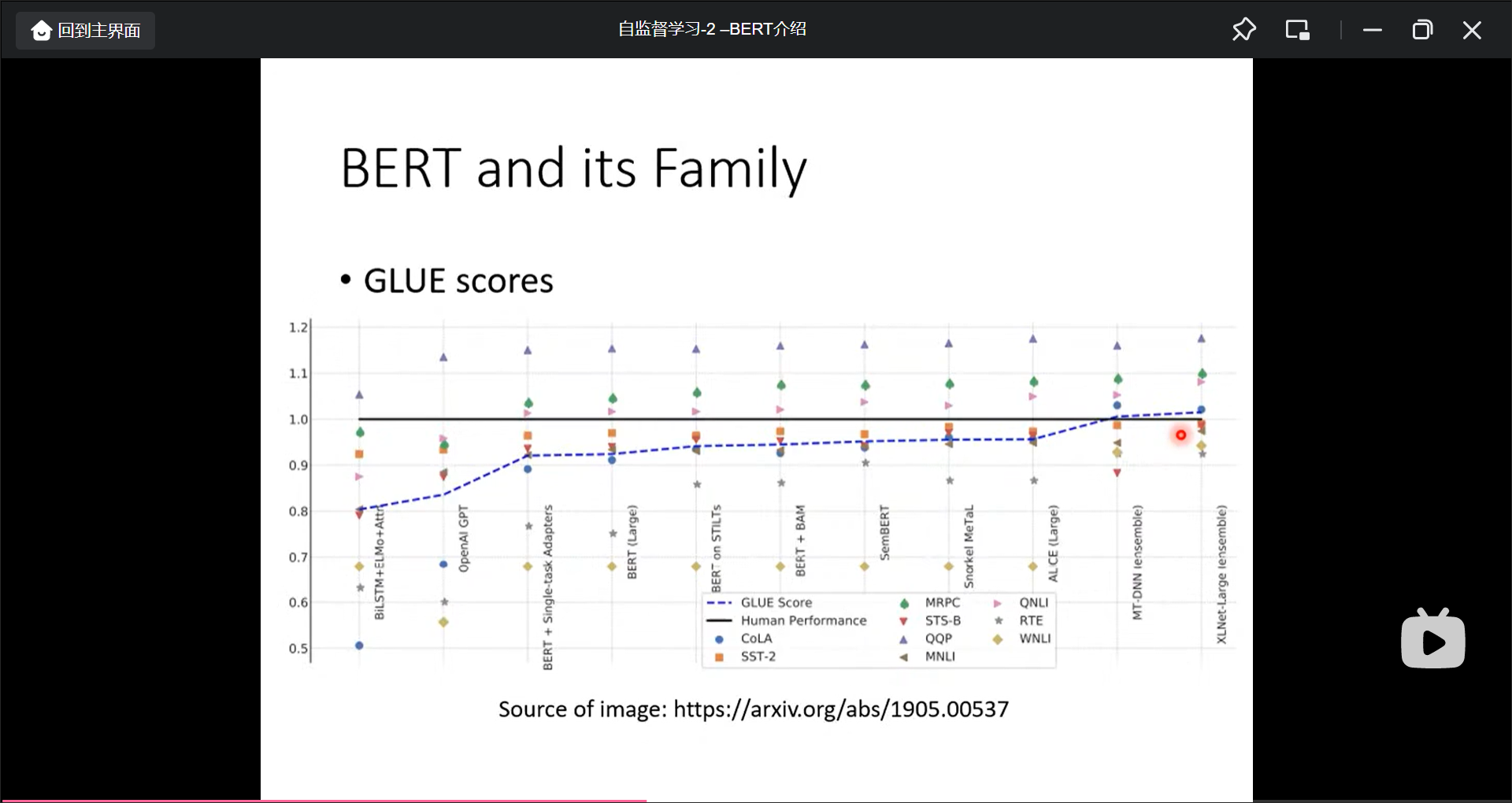
BEAT的好处:
- loss下降的更快
- loss最终降低的更低
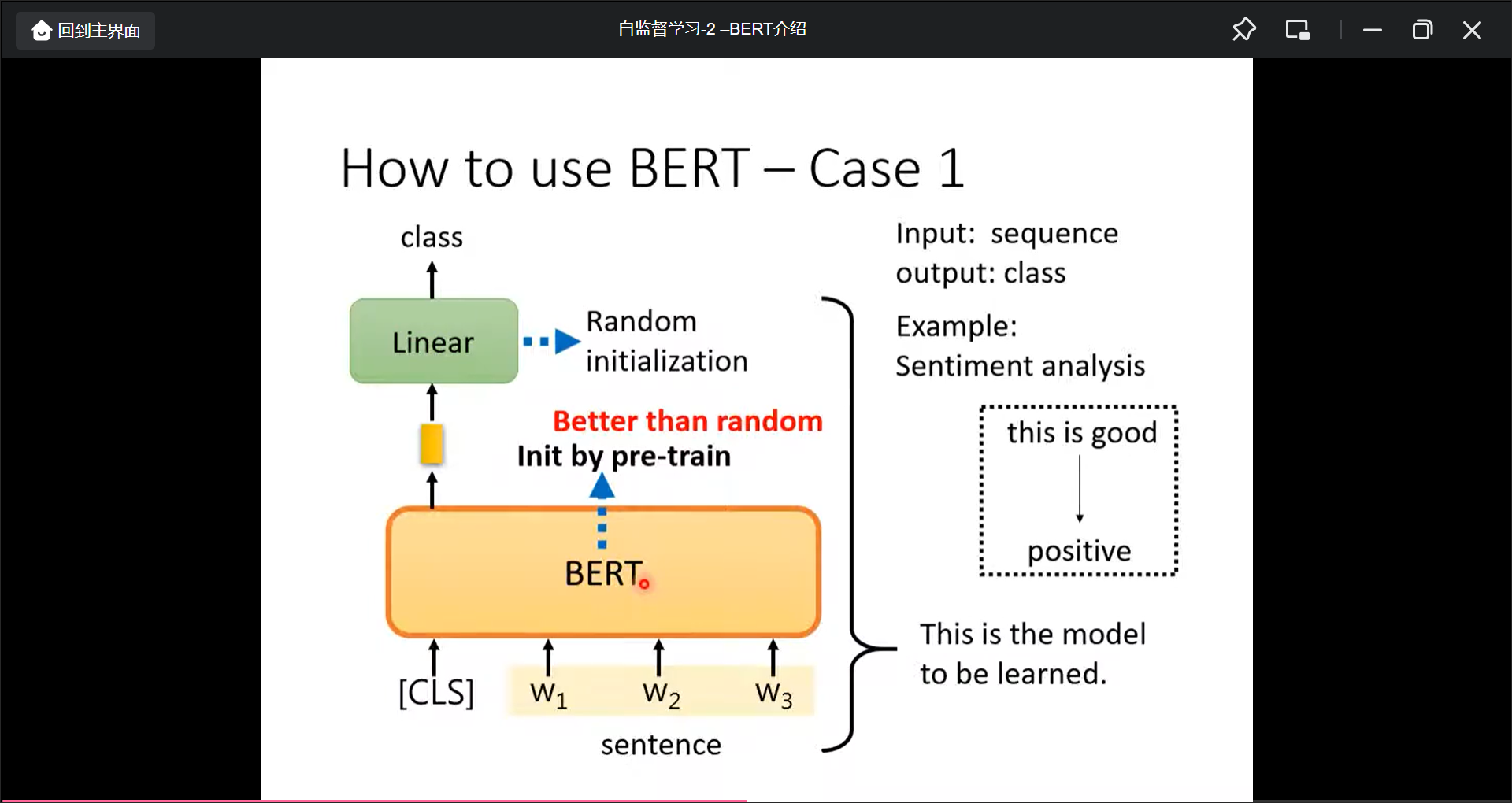
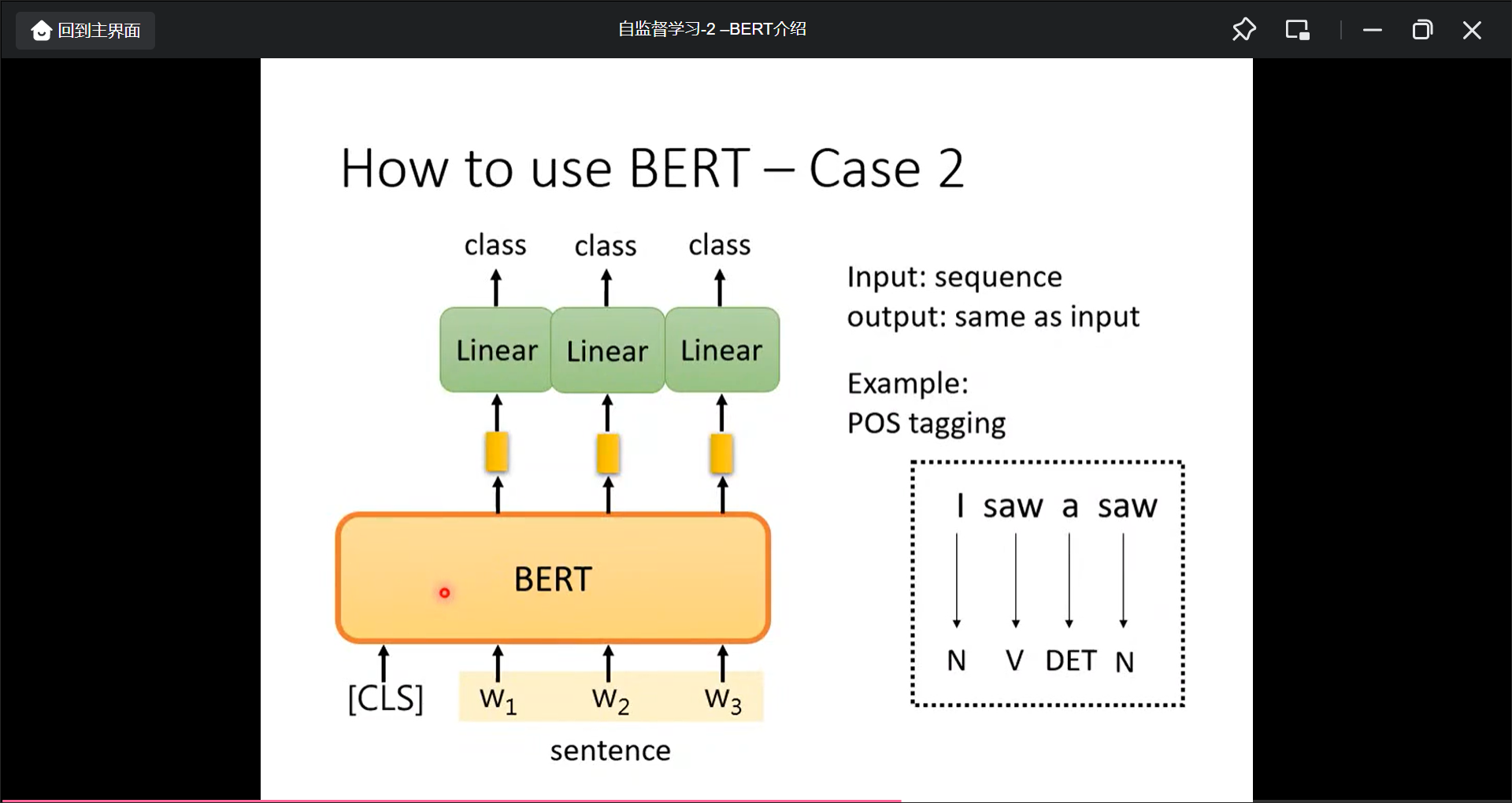
BERT的下游任务:
Input: Sequence, output: class, 比如情感分类
Input: Sequence, output: same as input, 比如词性标注
输入: 2个句子, 输出: 1个类别, 比如Natrual Language Inference(NLI).
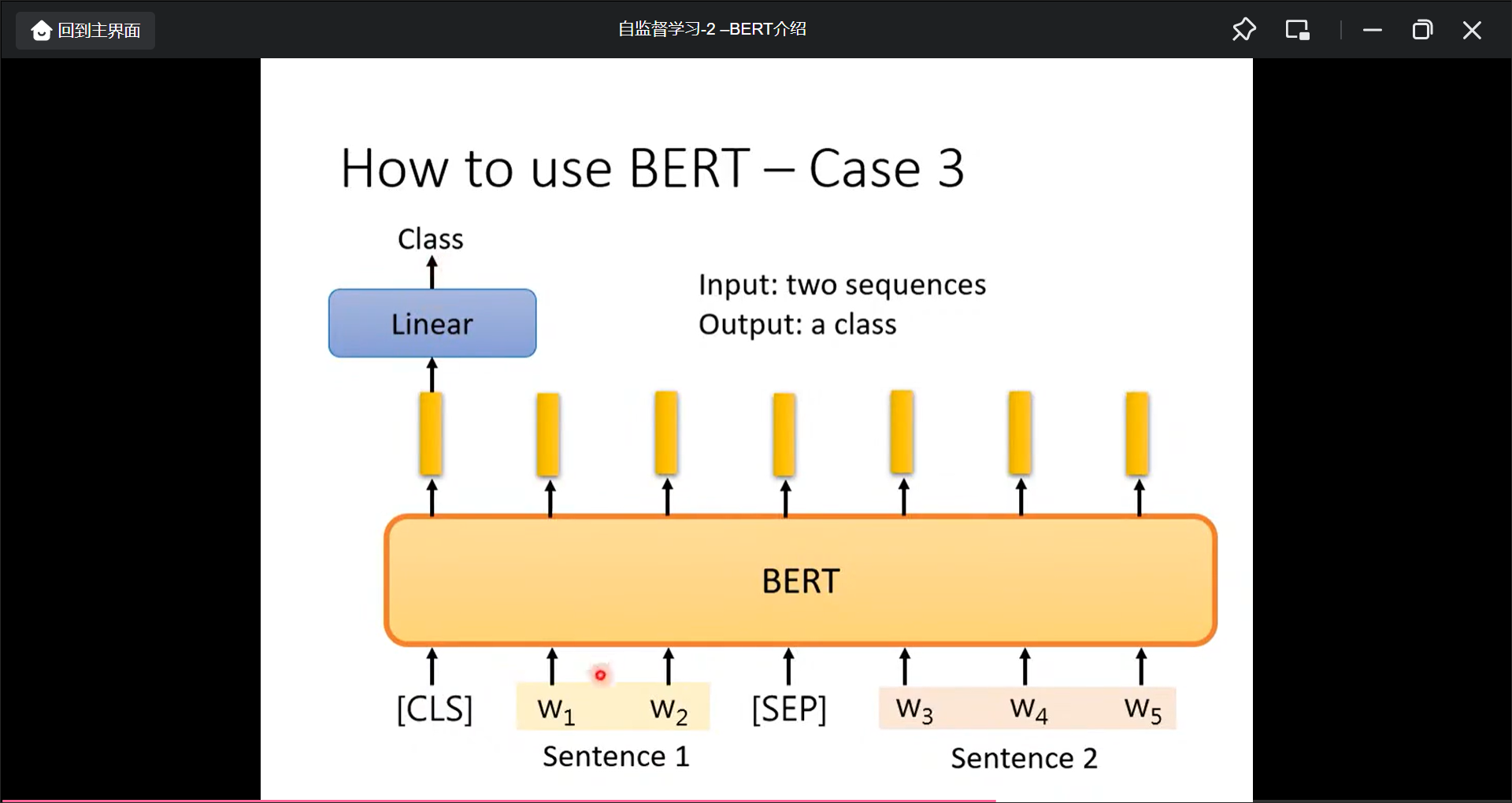
Extraction-based Question Answering(QA)

BERT的向量长度理论没有限制, 但是实际上512以内.
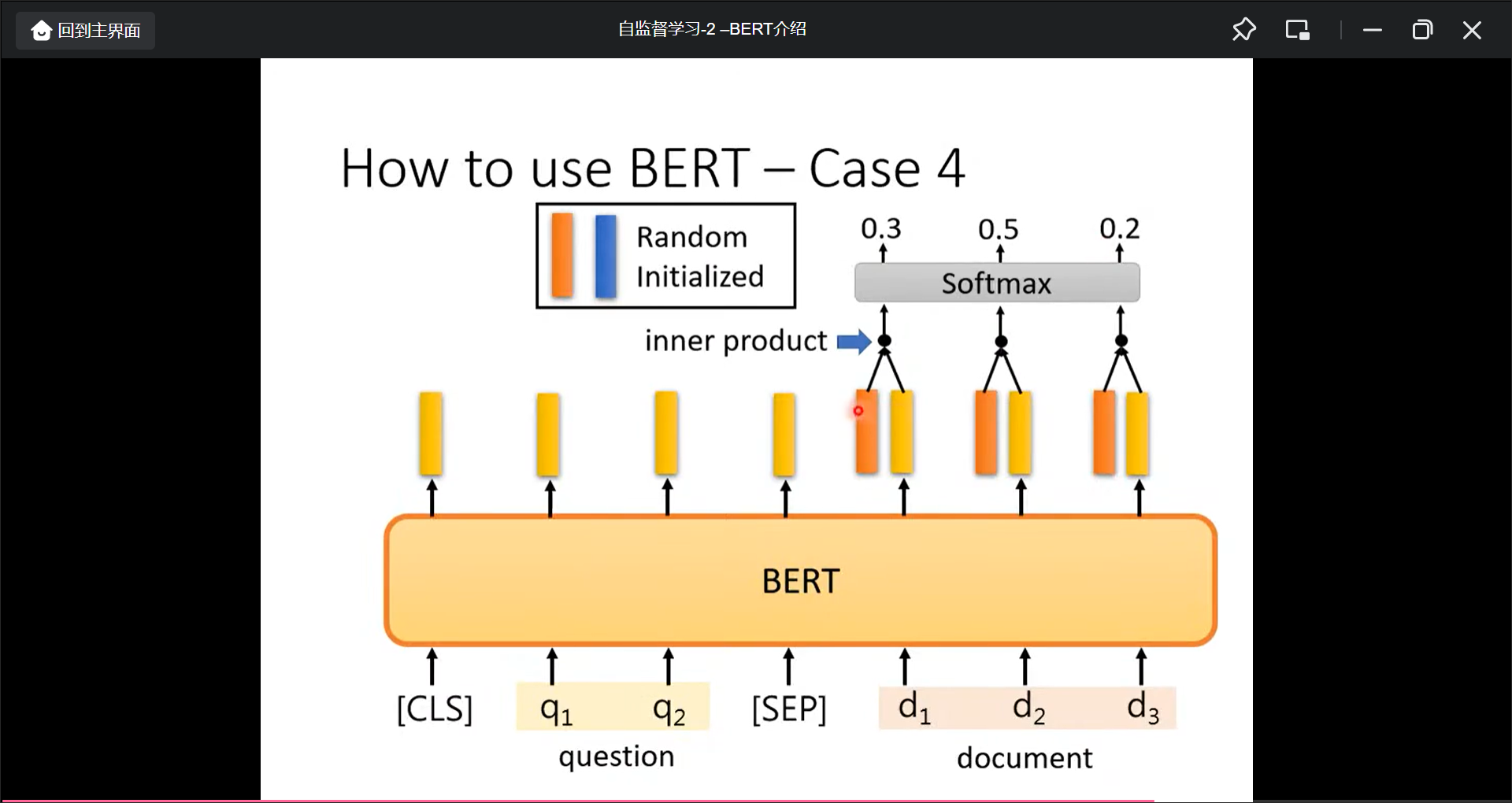
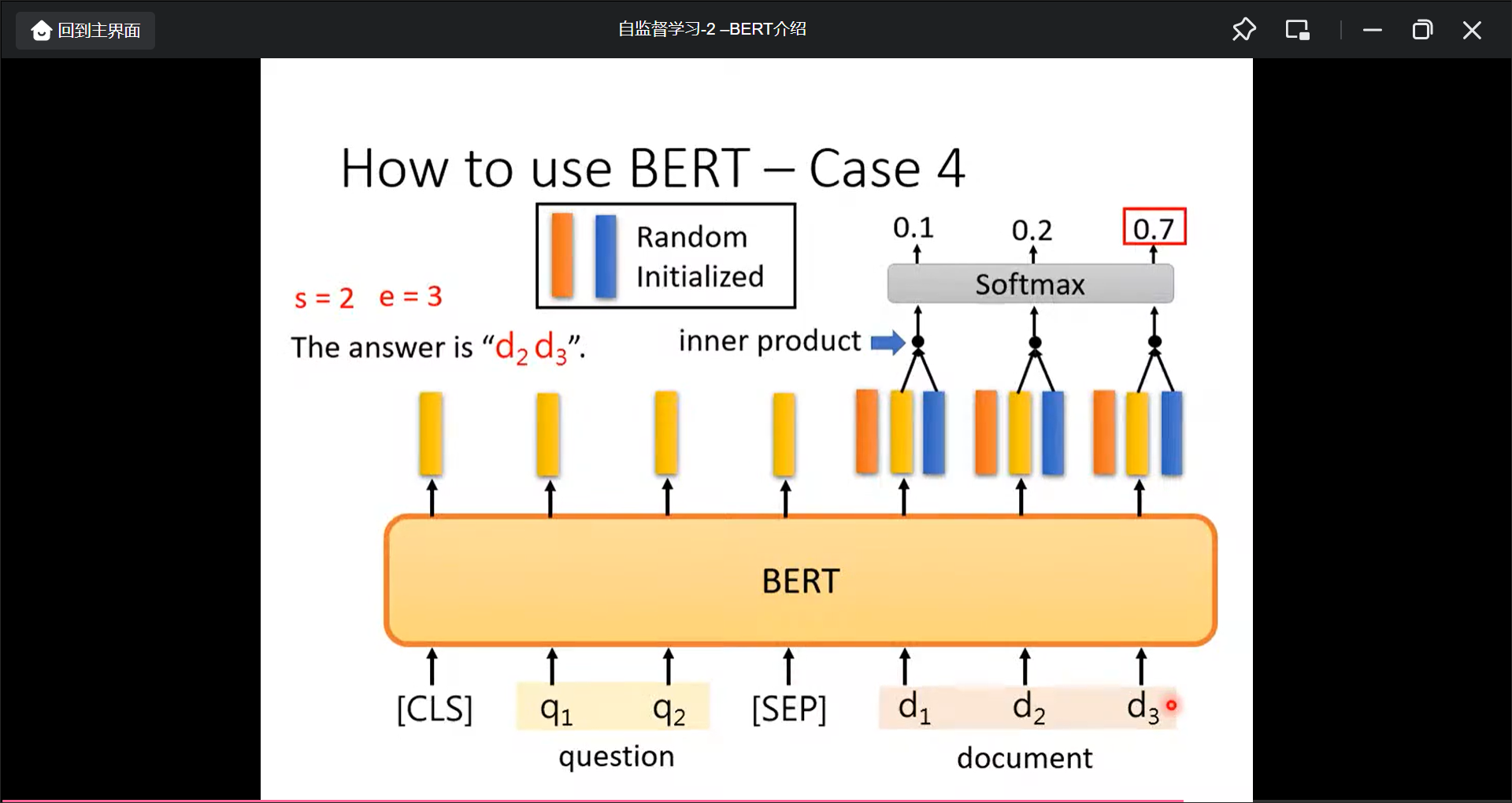
那如何将BERT运用到seq2seq中的任务中呢?
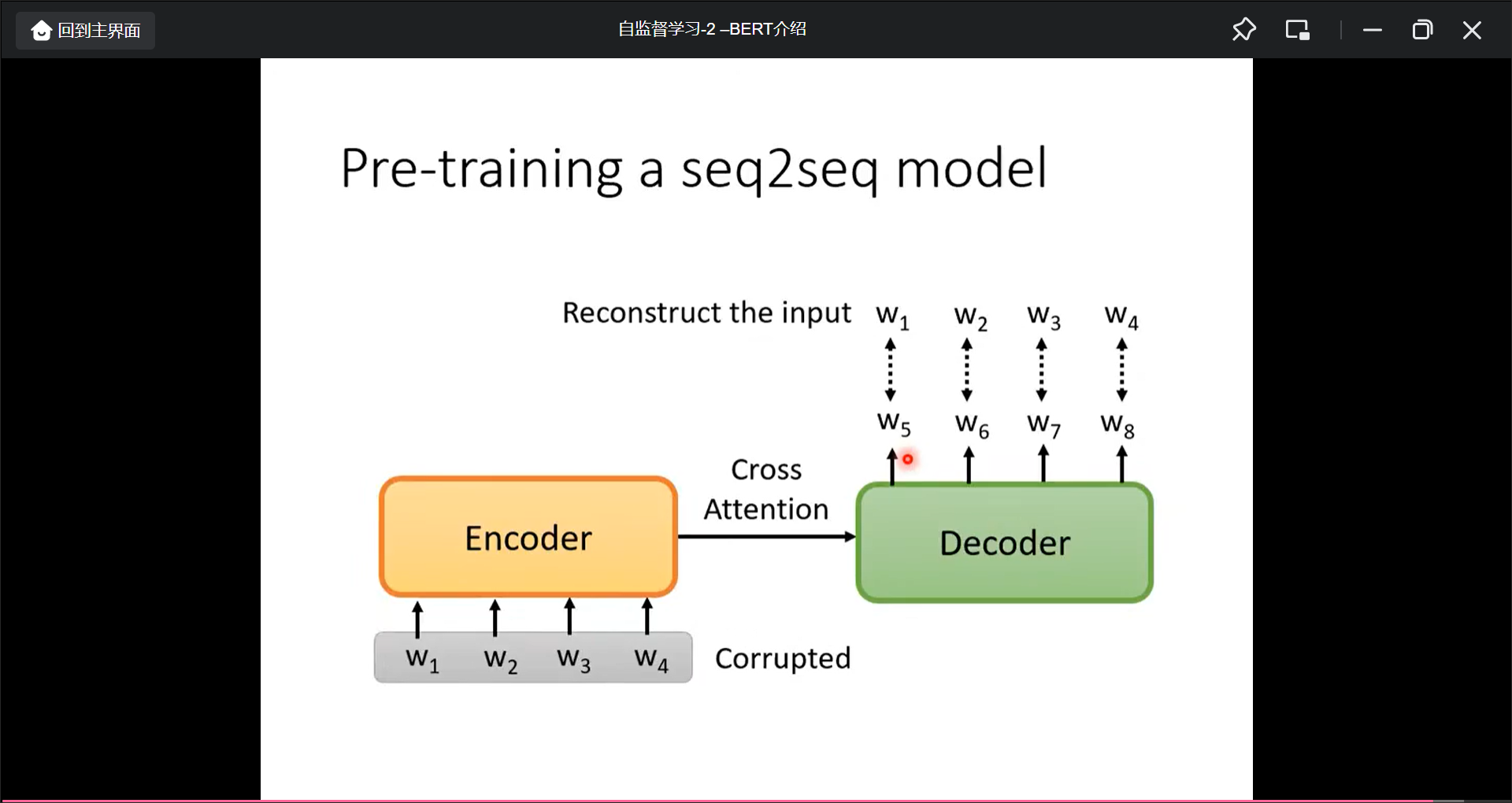
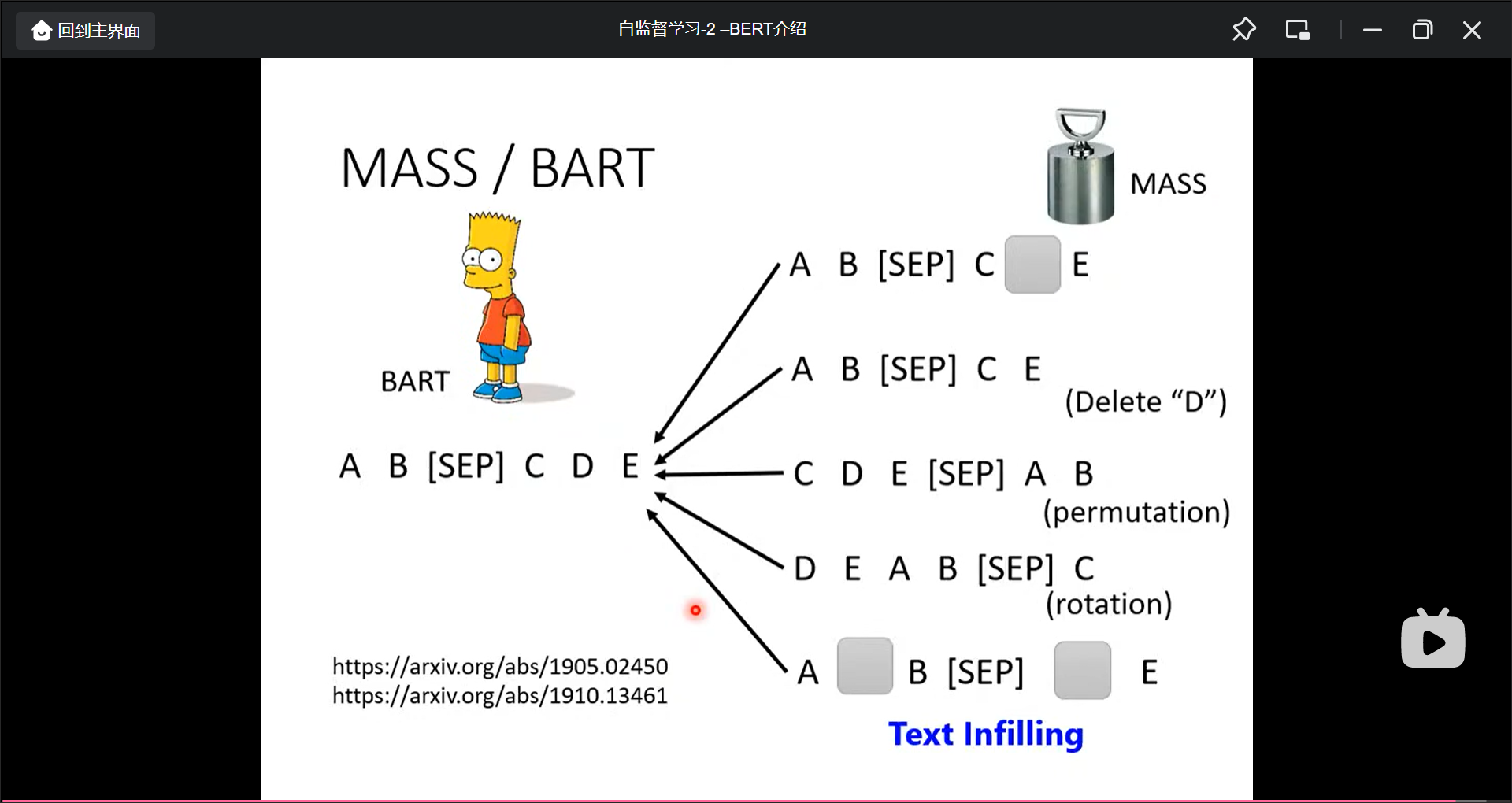
自监督学习-3-BERT的奇闻异事
BERT的工作方式(做填空题):
虽然BERT是从文字来训练出来的, 但是BERT用到protein, DNA, music, 都可以, 比如DNA sequece, 把A G A C分别对应某个单词, 然后再输入BERT, 再进行分类, 也有比较好的效果.
Multi-lingual BERT
用多语言预训练, 并且就算是用English来Fine-tune, 但直接用chinese, 也有比较好的效果:
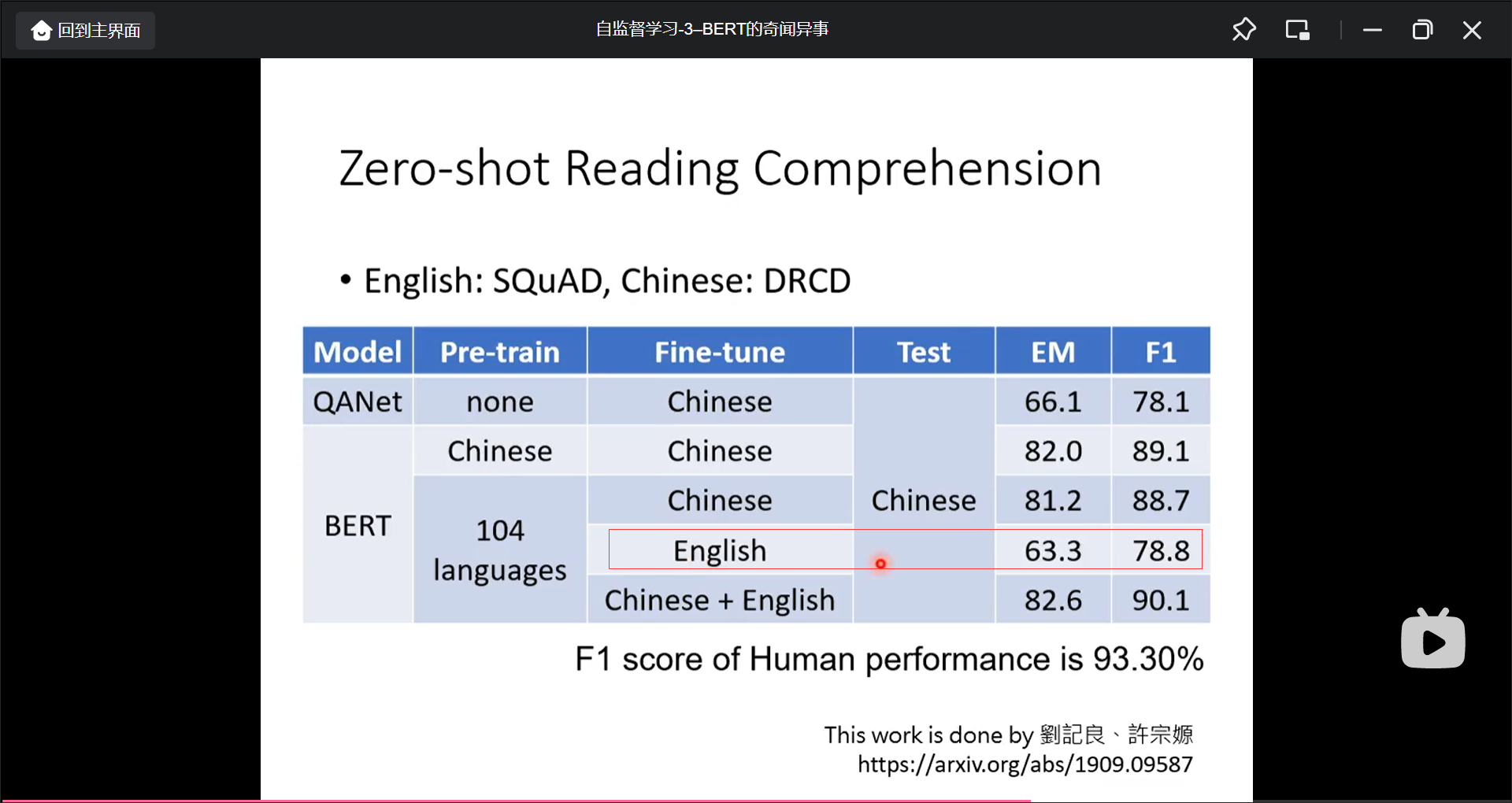
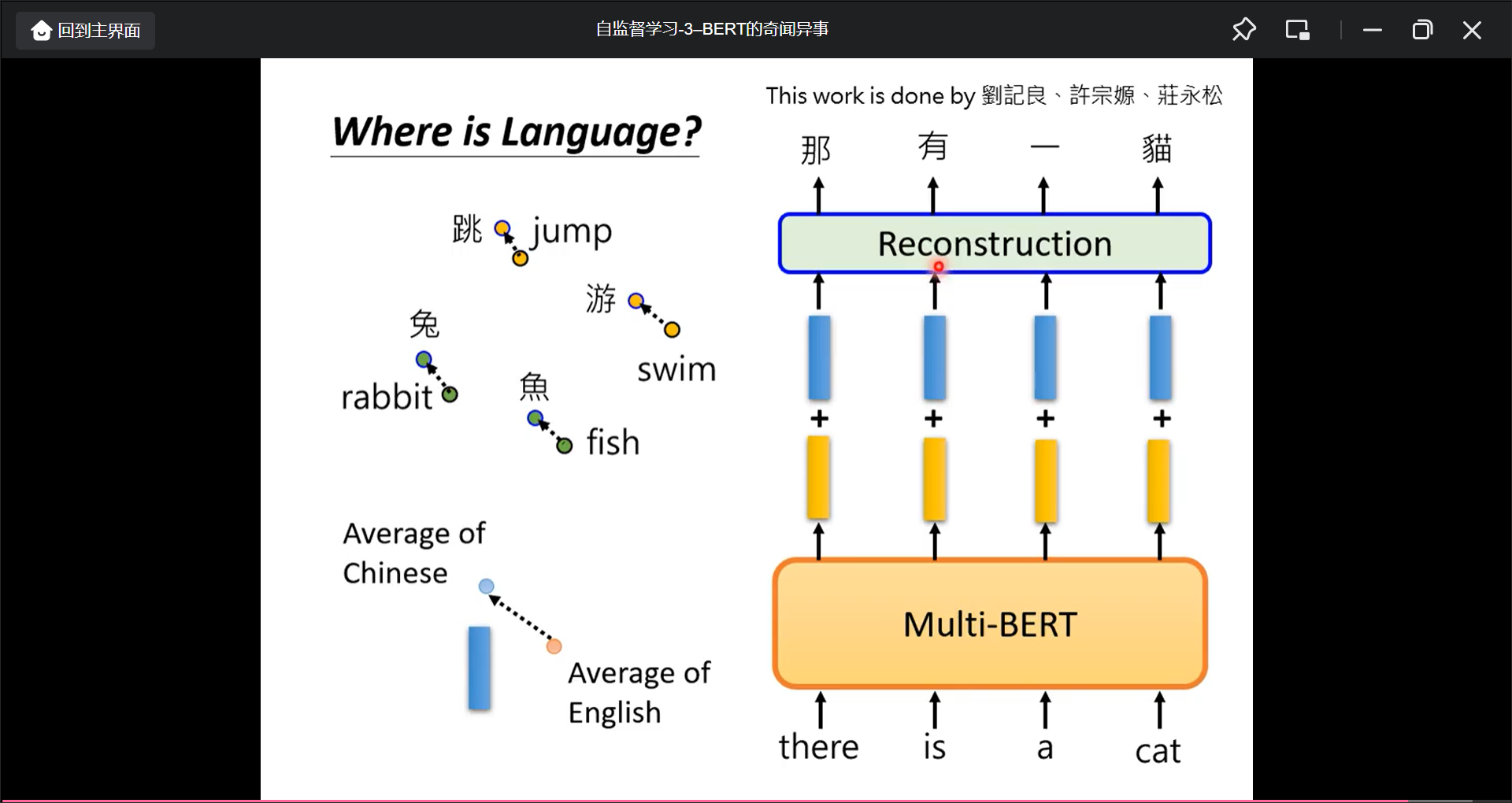
Multi-lingual BERT的中英文具体区别在哪里:
自监督学习-4-GPT的野望
GPT的Model的训练是 Predict Next Token.
GPT的使用:
BERT还是需要fine-tune的, 但是使用GPT时, 用Few-shot learning, 并且不用梯度下降调参数, 知识给几个例子, 然后让做相同的任务, 这种训练叫做In-context learning. 但是正确率有点低.
Self-supervised learning还用再Speech , CV领域:
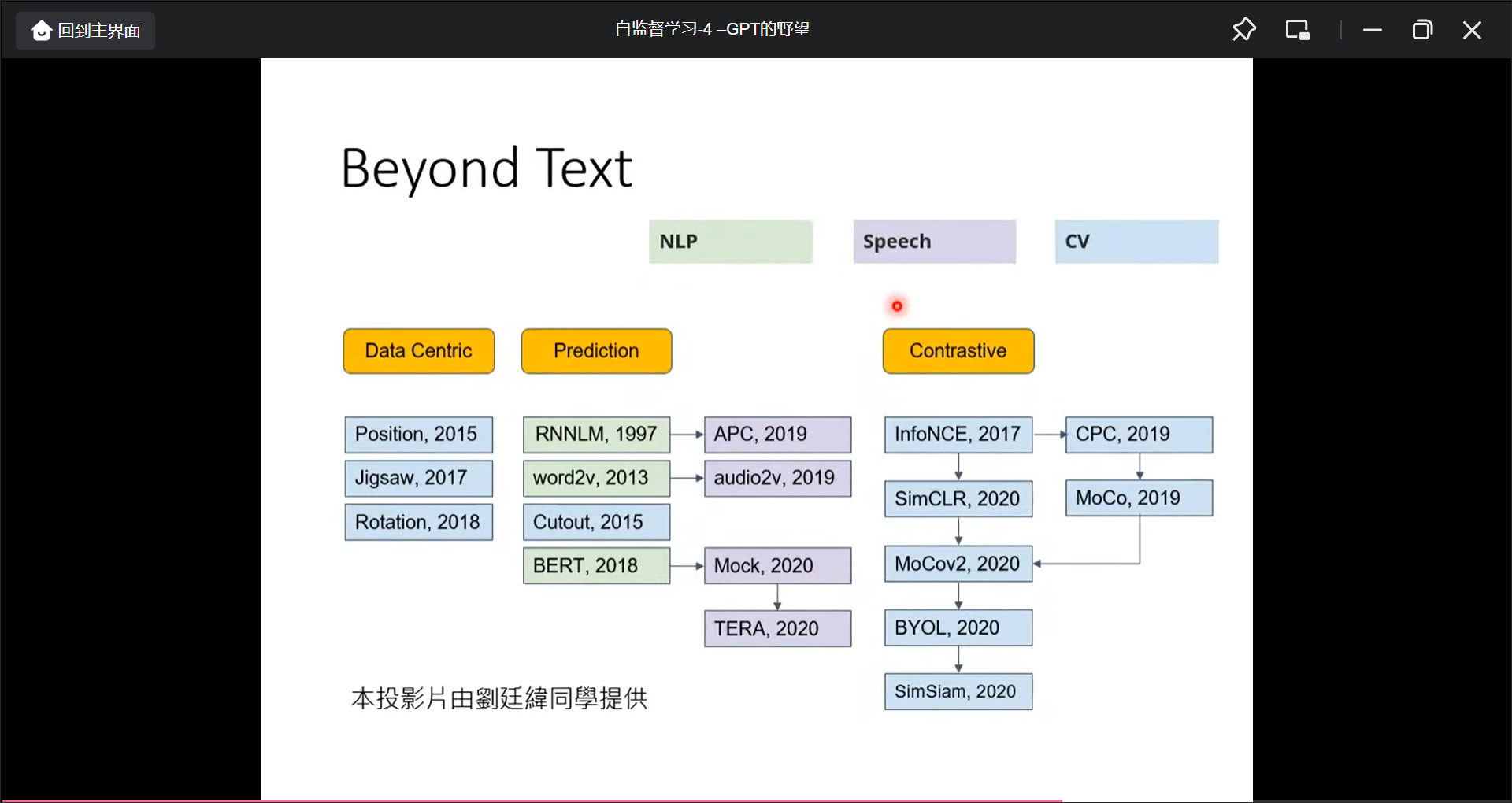
Speech GLUE - SUPERB

第8讲 Auto-encoder
自编码器(Auto-Encoder)上-基本概念
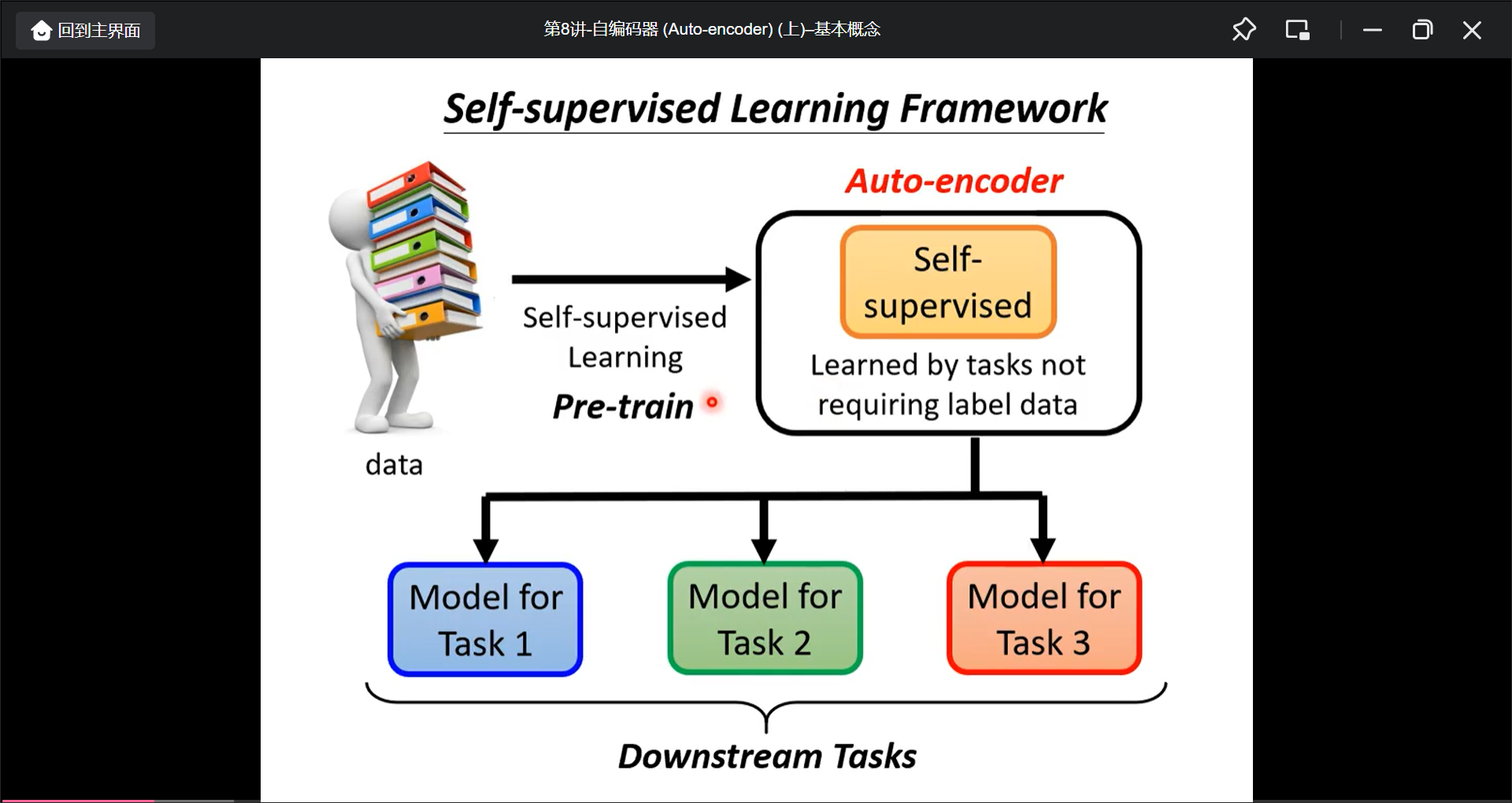
Auto-encoder是self-supervised learning的一种, 然后将pre-train model用于下游任务:
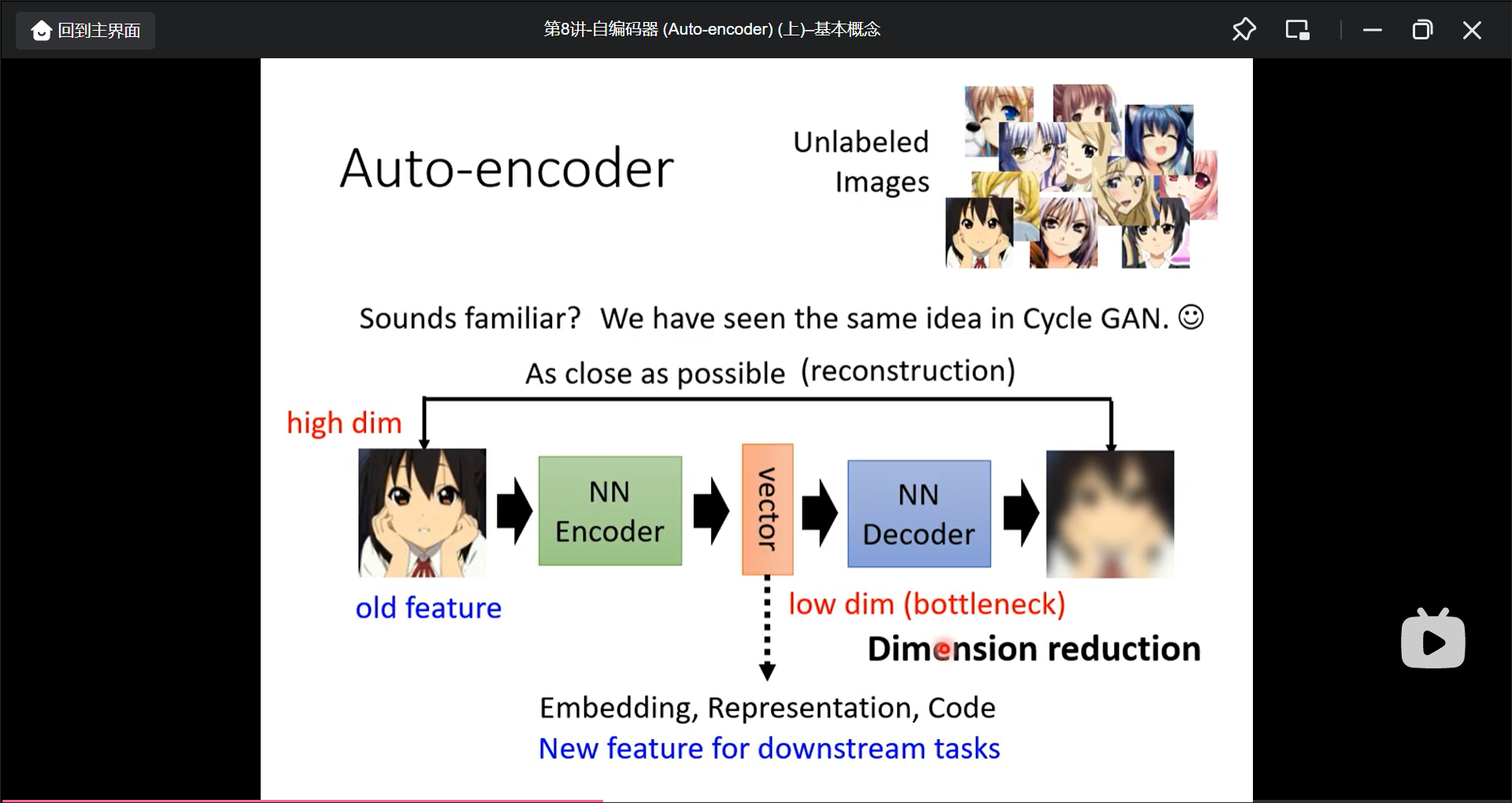
而Auto-encoder是这样的, 将生成的中间vector用做下游的feature:
Auto-encoder变形: De-noising Auto-encoder(加入杂讯, 然后还原加入杂讯前的图片):
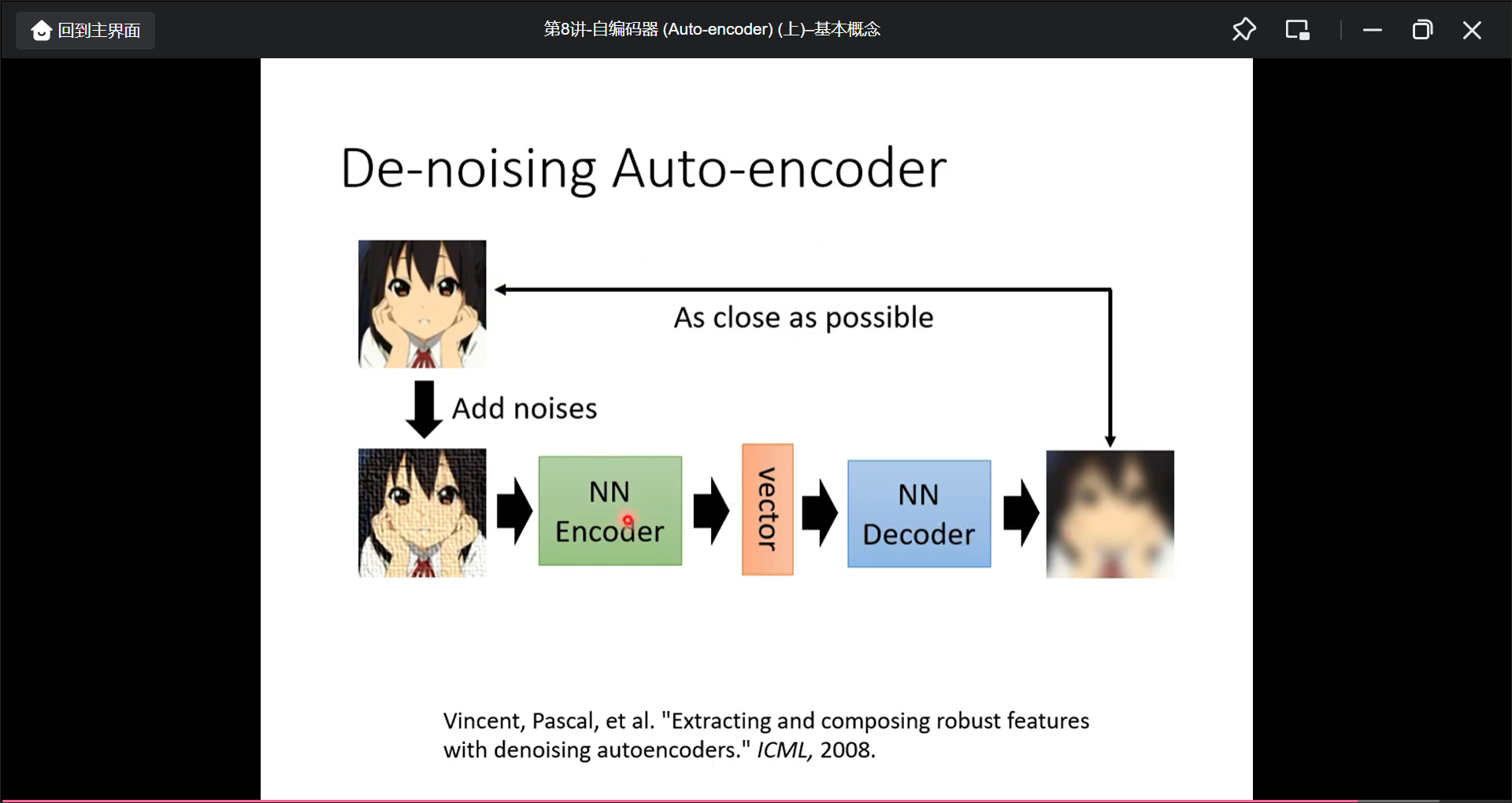
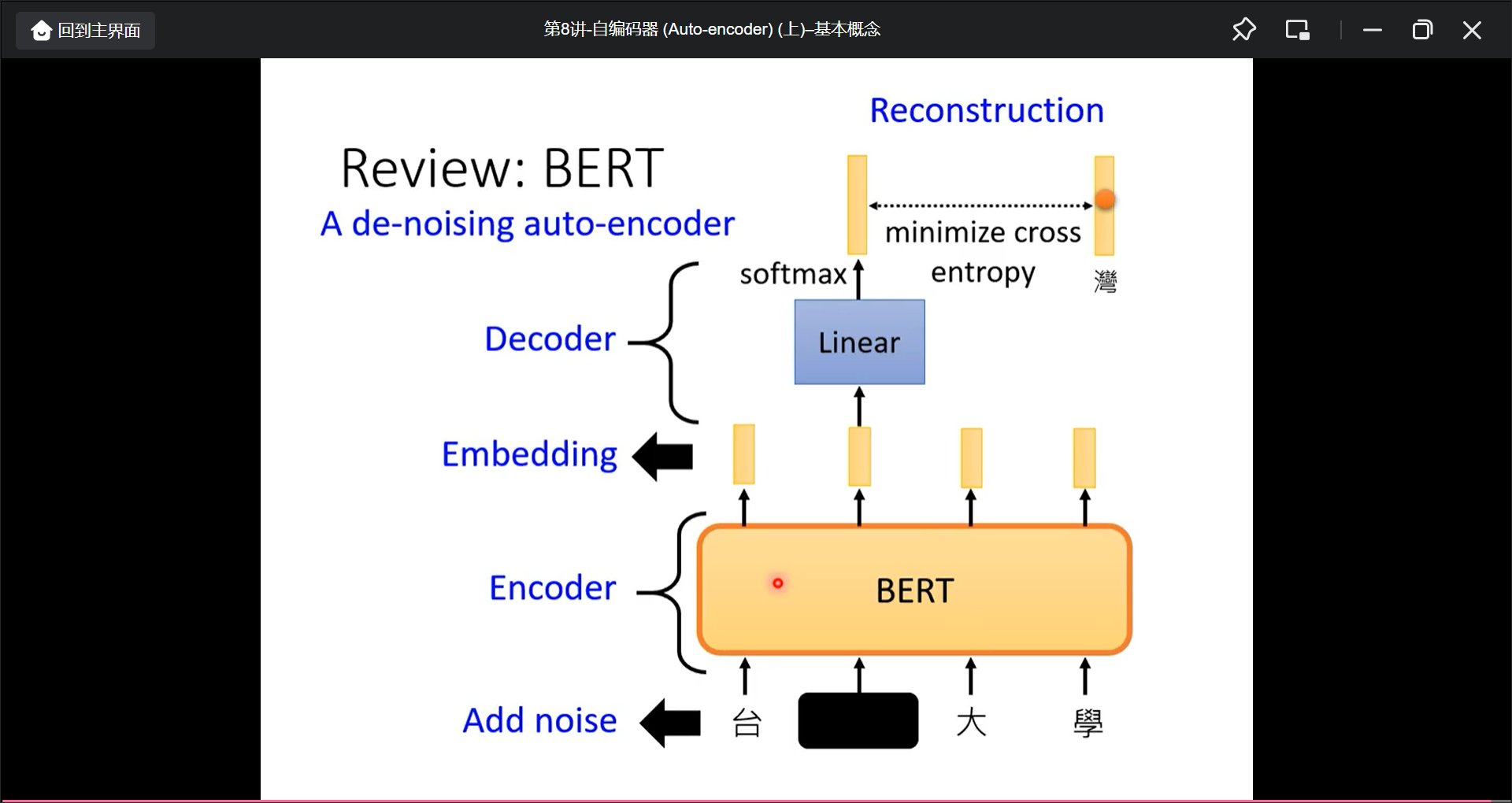
而从加入杂讯的角度, BERT也就是加入了杂讯, 所以BERT也可以看作一个de-noising auto-encoder:
自编码器(Auto-encoder)下-更多应用
Feature Disentangle:
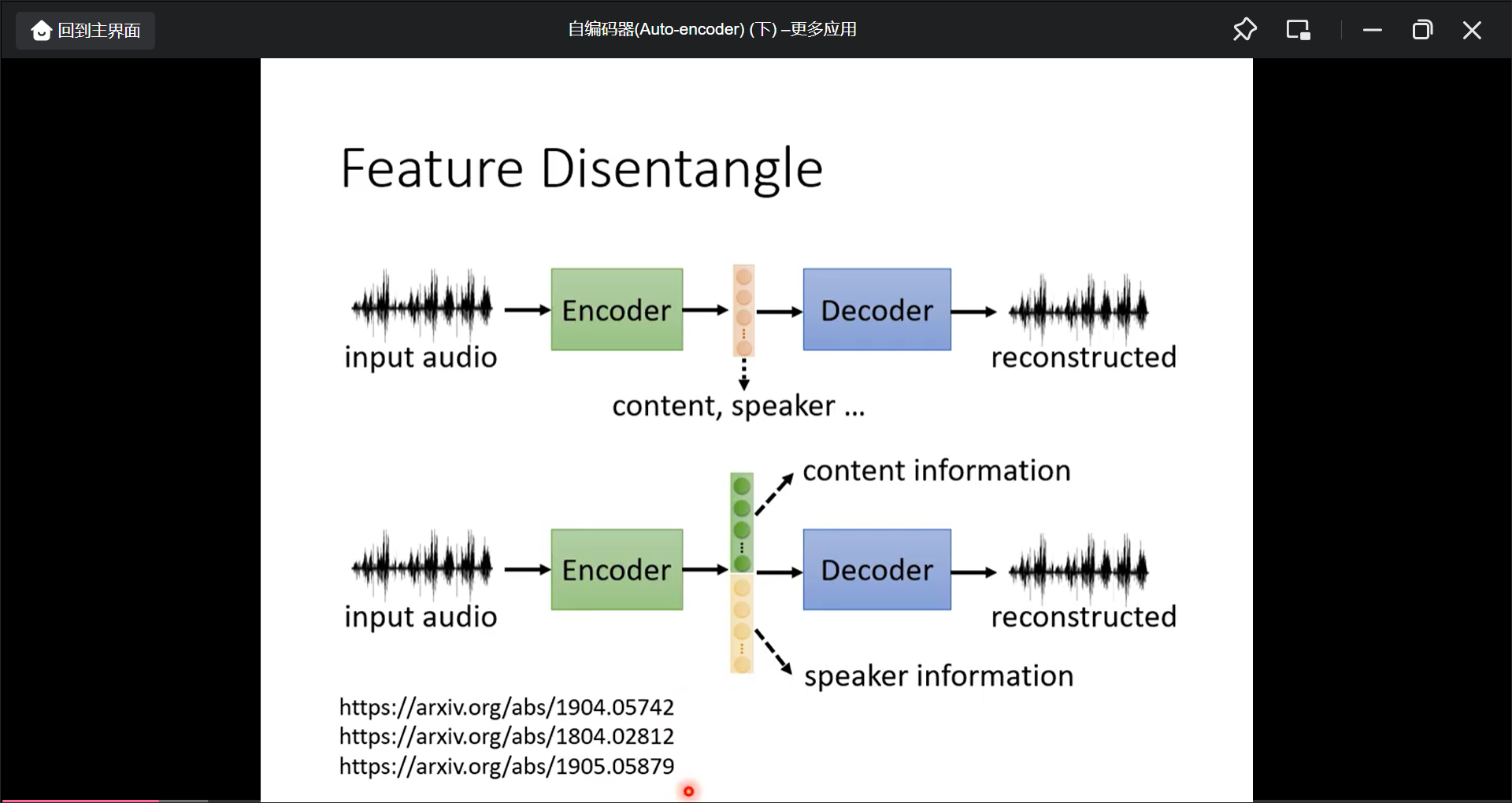
Feature Disentangle的应用: Voice Conversion.
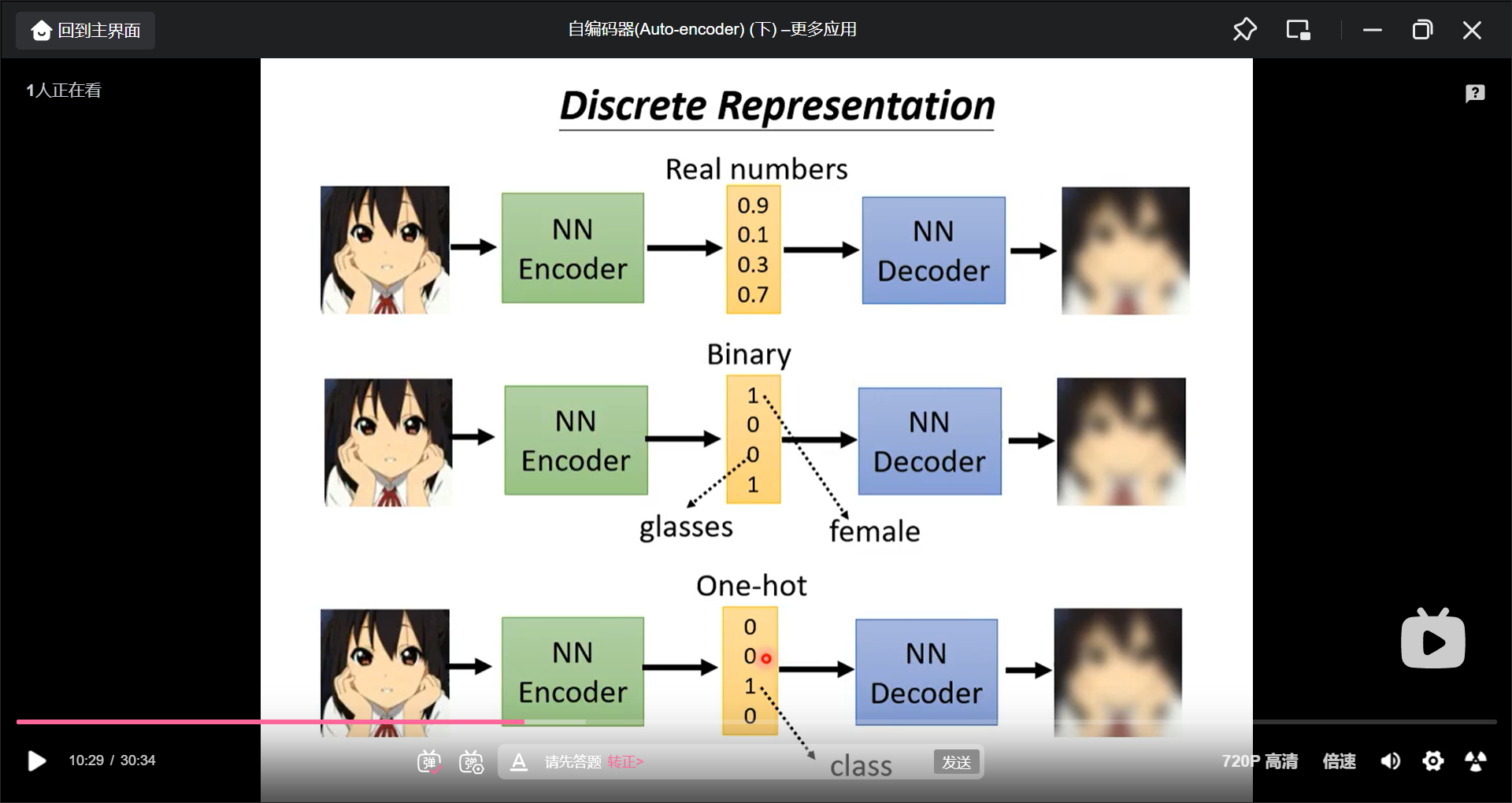
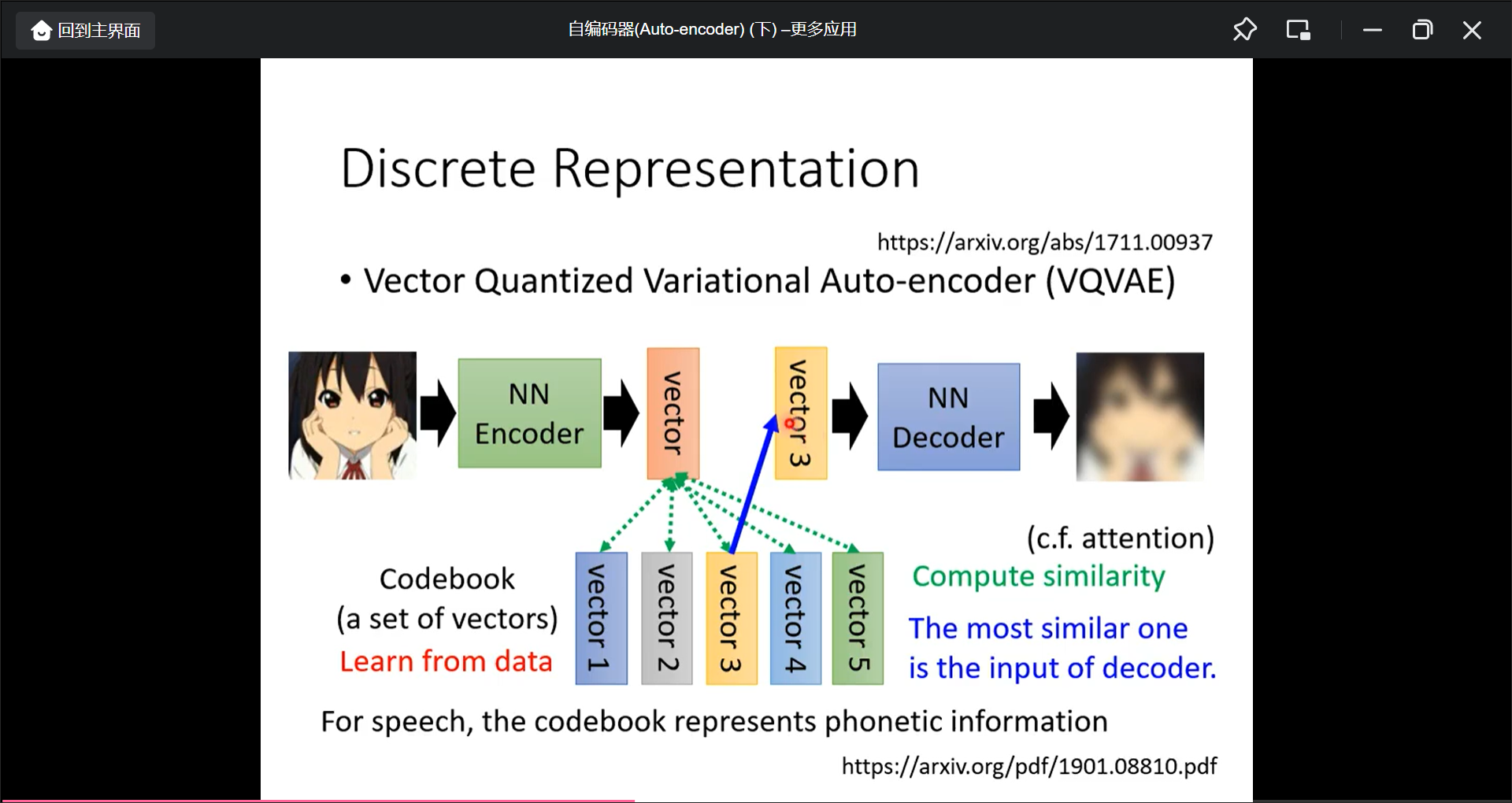
Discrete Representation
中间的向量可以强制为离散的, 也许可以用于自监督分类.
VQVAE:
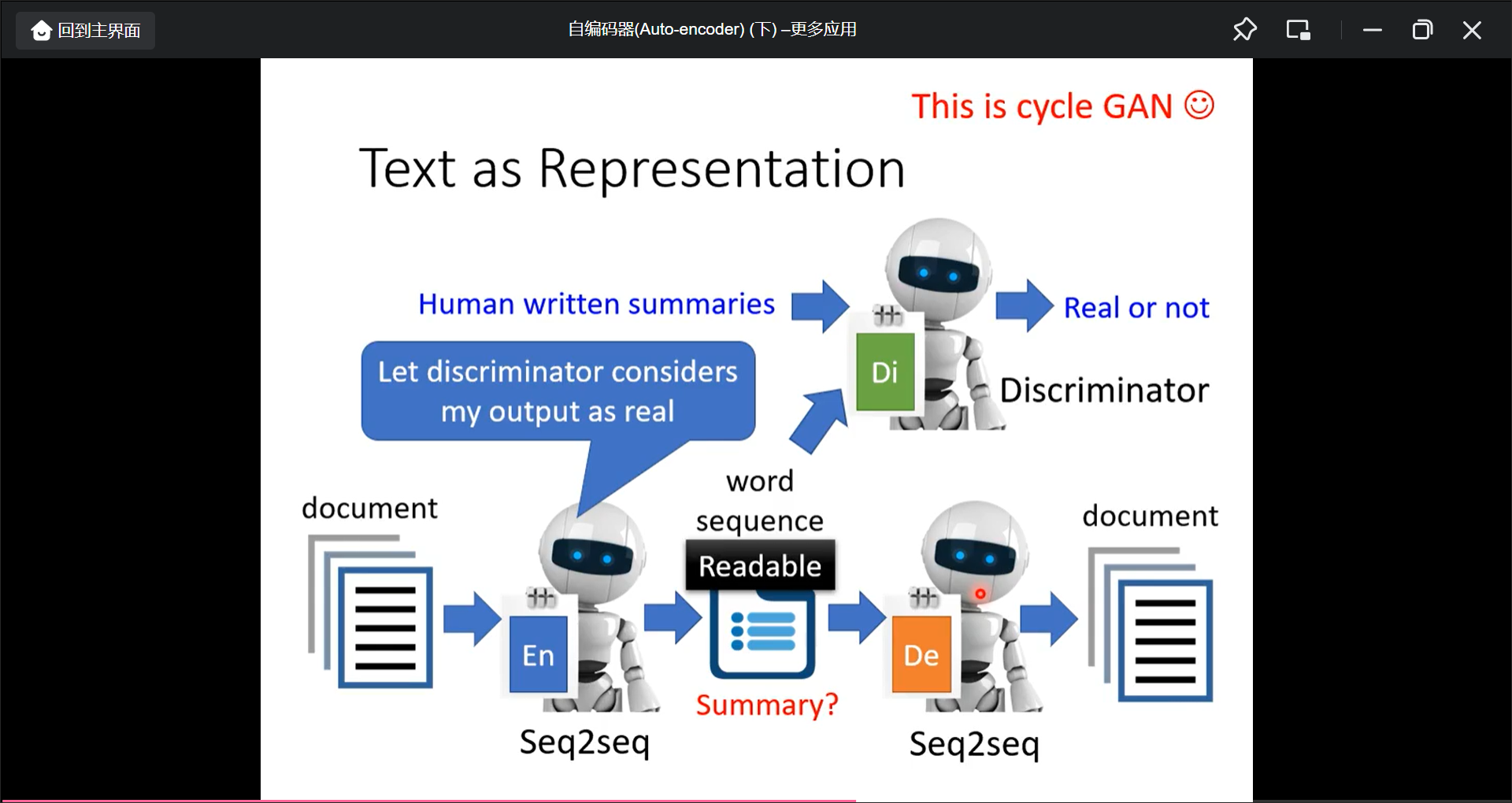
文字也可以做Auto-encoder, 中间的向量也许是Summary(但是行不通, 所以还需要GAN的概念),
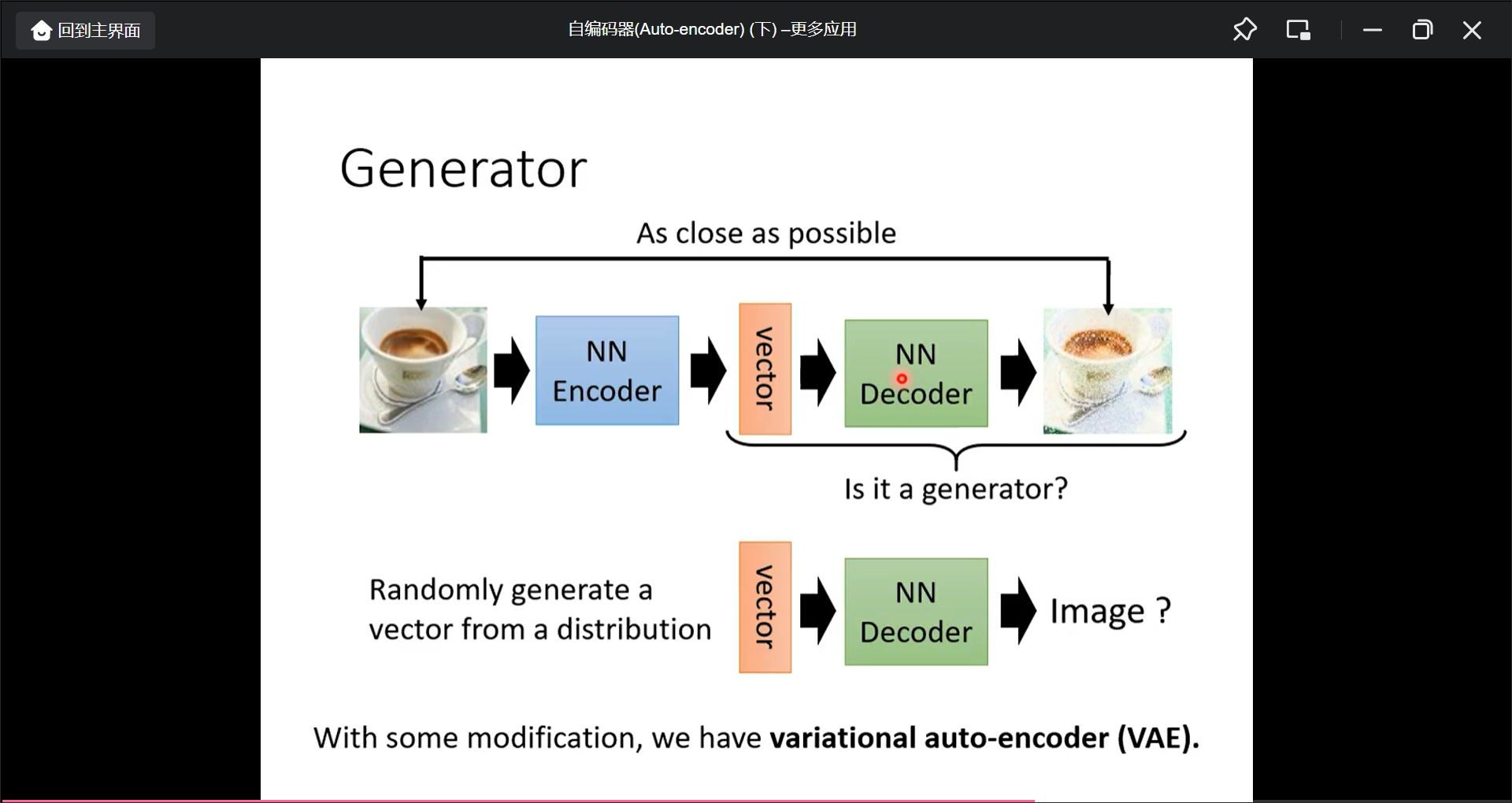
Auto-encoder更多应用
Generator(用Auto-encodeer的后半部分decoder做生成)
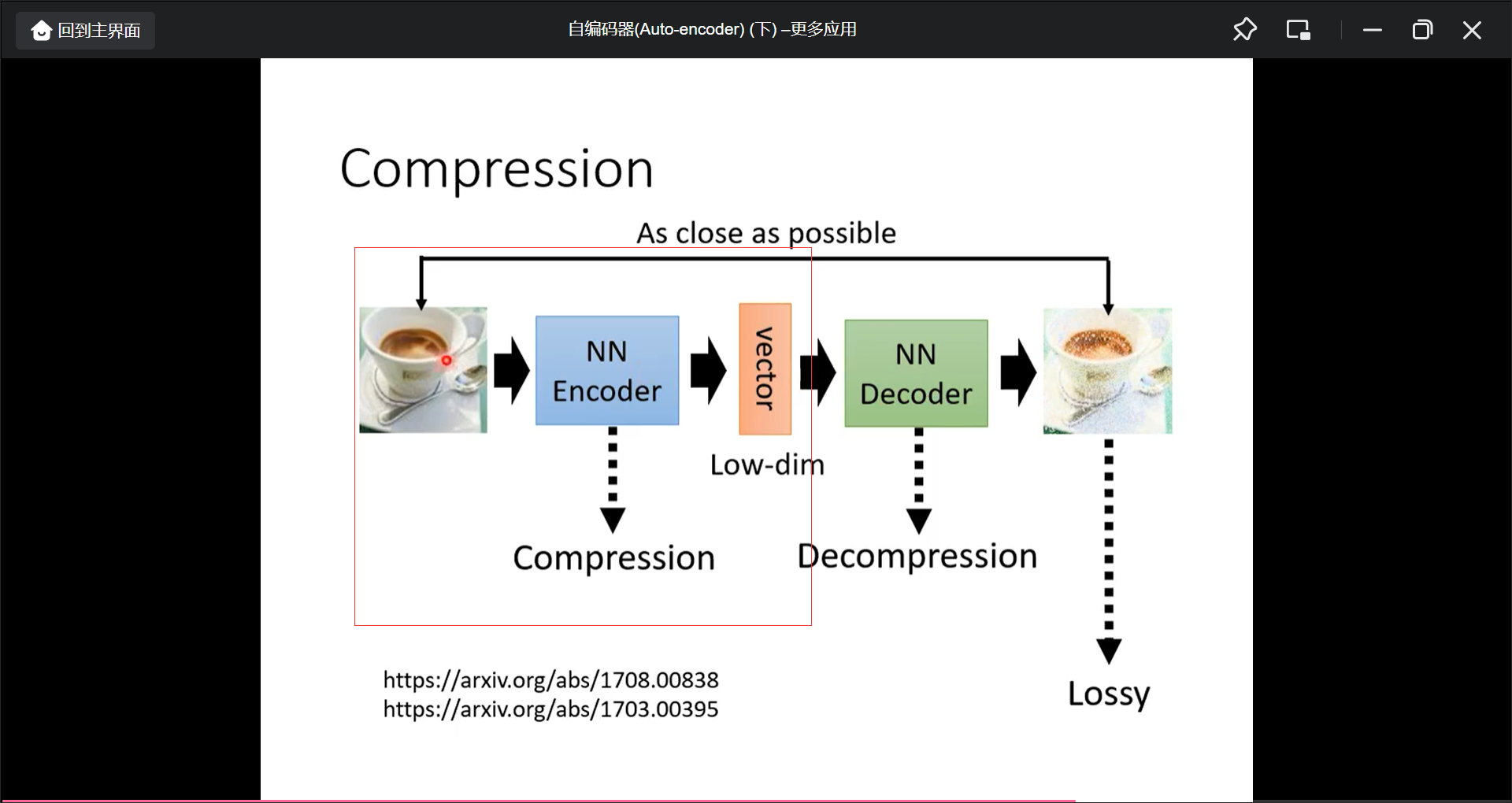
Compression
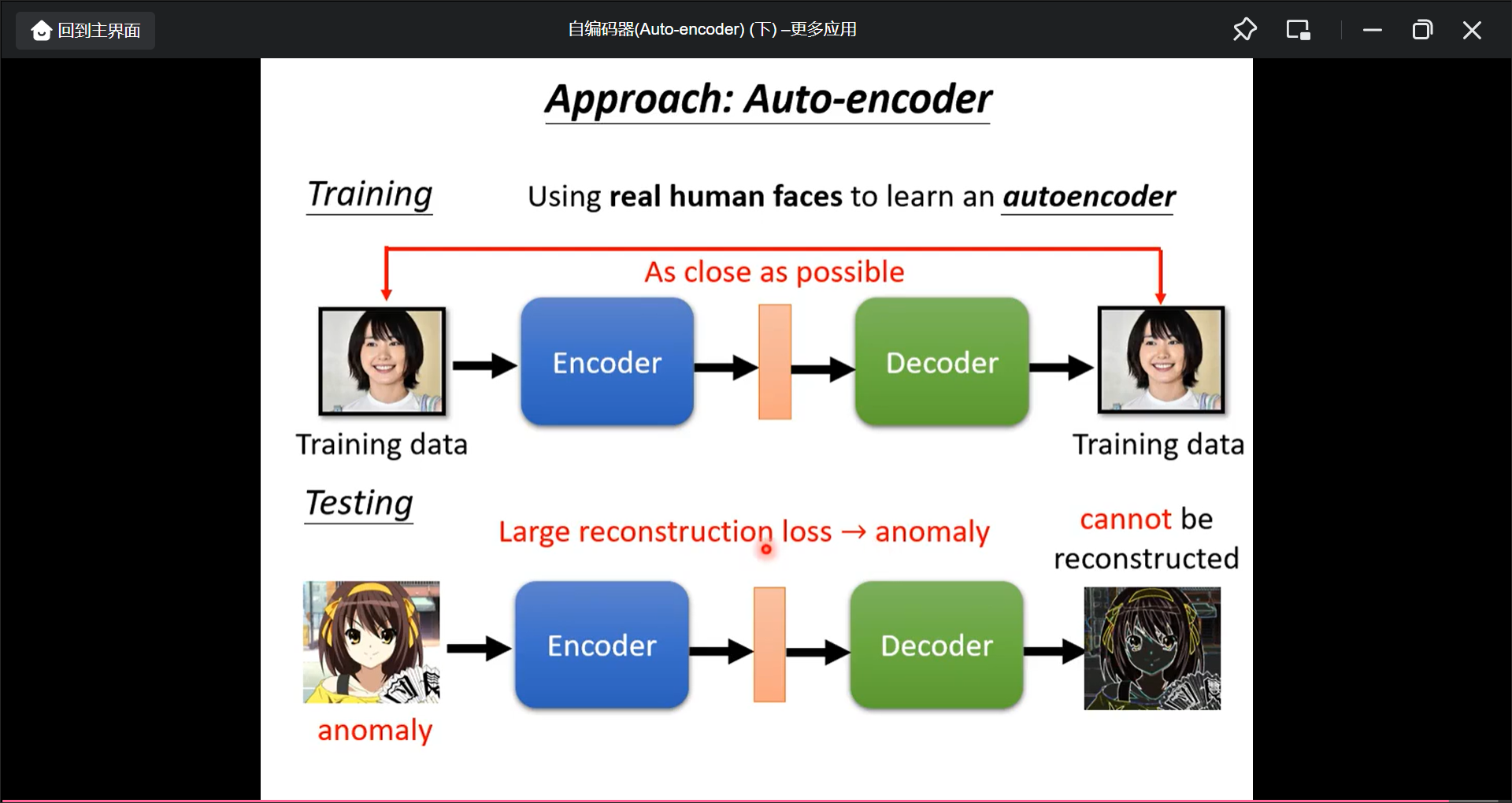
Anomaly Detection(异常检测)
比如信用卡交易欺诈侦测
第9讲 Explainable AI
机器学习的可解释性-1(Local EXPLANATION)
Goal of Explainable ML: 只需要一个解释, 能让人高兴的解释就是好的解释.
两类:
- Local Explanation, 对某个instance的判断给出理由
- Global Explanation, 对这个模型给出理由
在图像处理中, 用一个mask把原图遮住, 然后再做判断, 如果影响大, 就说明这个区域重要
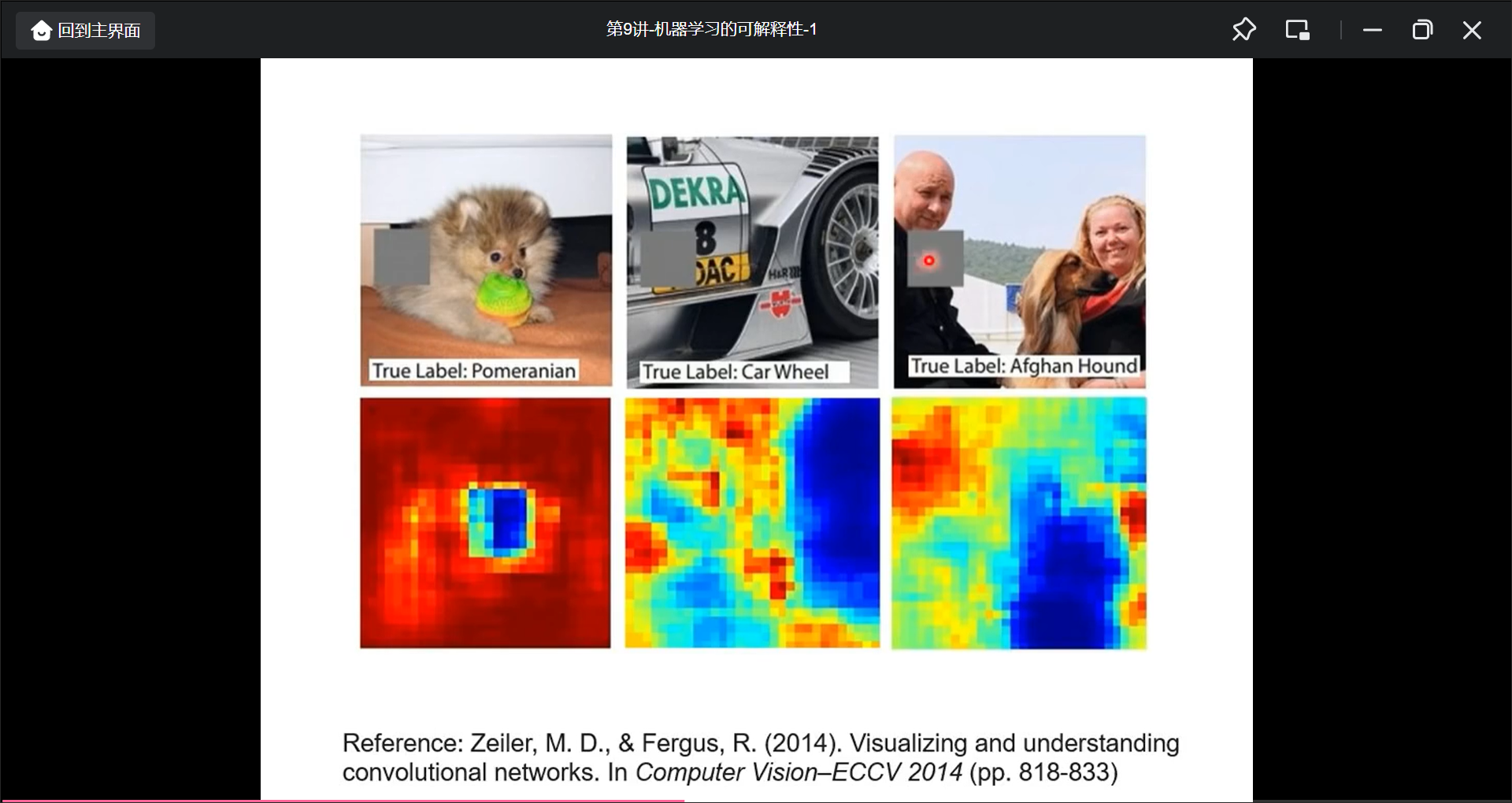
具体的来说, 对于某个像素做一些改动, 然后看loss改动的范围:

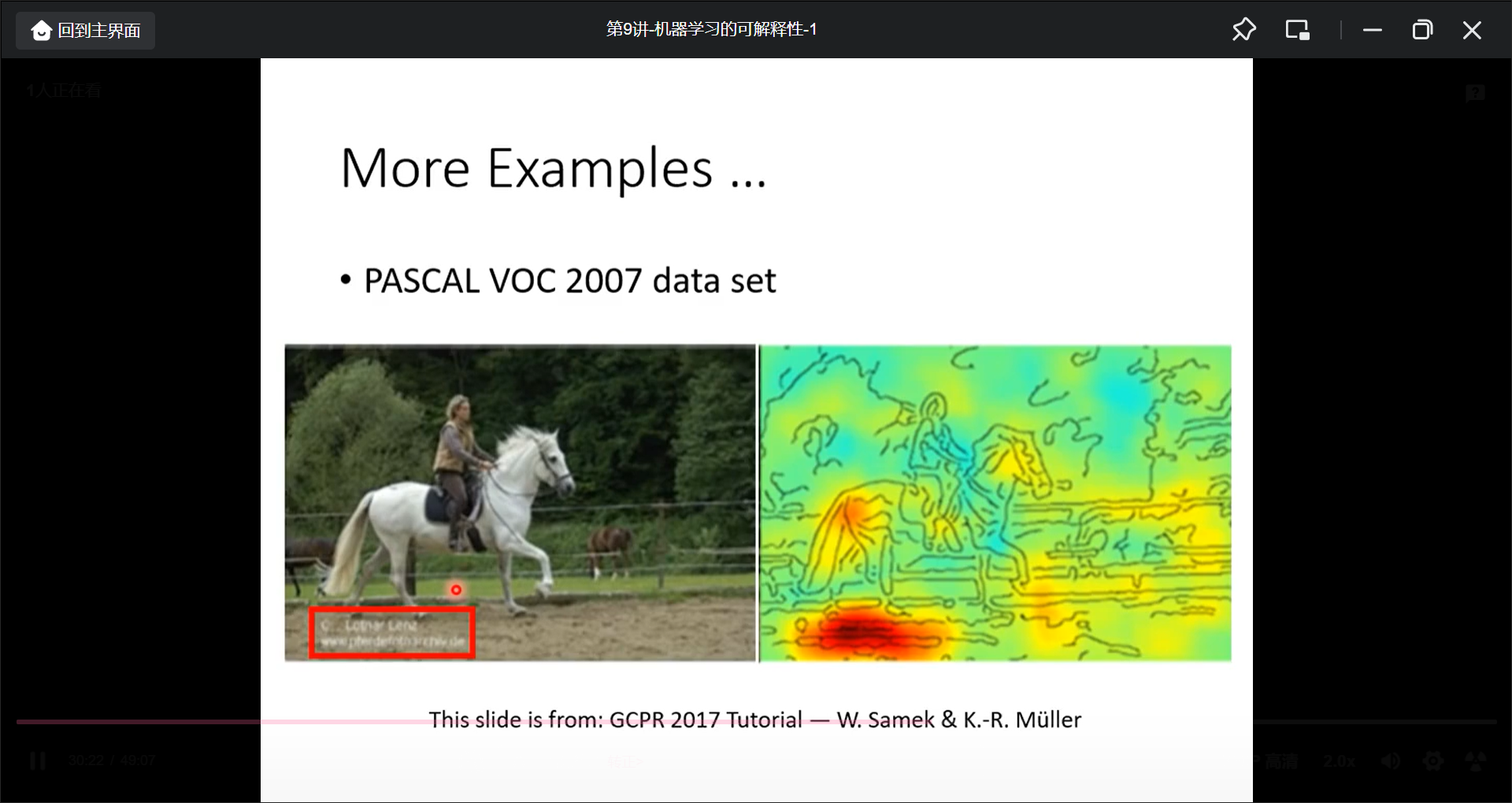
如何解释network:
- 肉眼观察
- Probing
机器学习的可解释性-2(GLOBAL EXPLANATION)

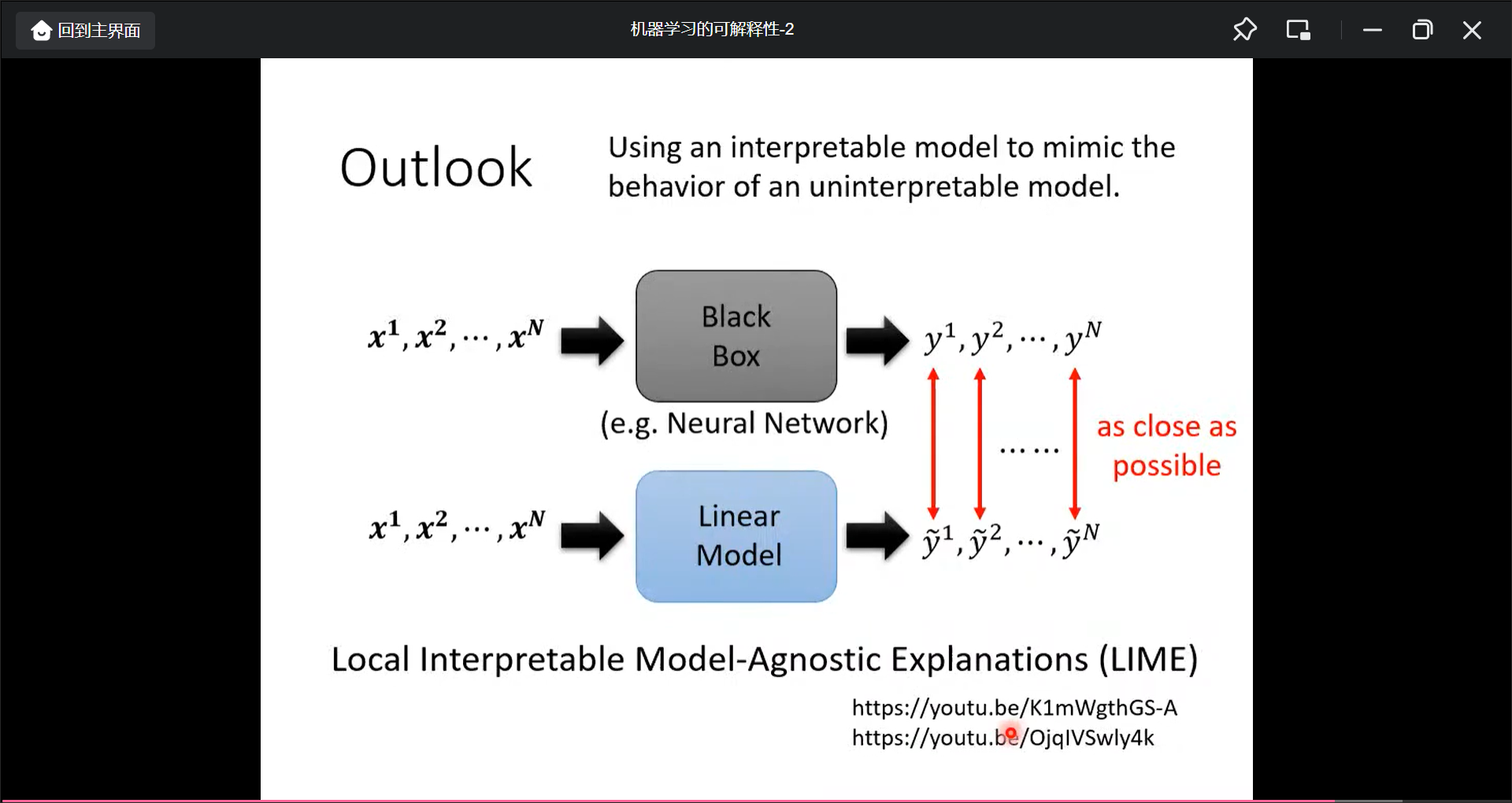
也可以用简单模型模仿复杂模型, 再解释简单模型:
思考:
输入数据是这样, 那如果应用到ibizsim-ml是如何形成训练数据呢
Decoder的结构可以完美的契合ibizsim的数据输入方式, encoder的输出就是初始信息, begin就是第九期决策. 然后第9期的决策结果就又输入网络加上encoder的初始信息再进行下一次判断.
Discriminator的训练过程是否可以用到ibiszim中
BERT的掩盖self-supervised考虑到ibizsim
冻结前半部分网络(前9轮) ,再训练第10轮, 然后再冻结, 再训练
GPT的预测下一个token的这种模型可不可以用到ibizsim.(也就是生成的能力)
06年的 RBM 是每一层都训练好, 然后接起来再微调, ibizsim似乎也可以这样做
用可解释性来评估ibizsim模型
作业
作业二: speech regogition
作业三: image recognition
作业四: sepaker recognition
作业5: Machine Translation
作业6: Generator
作业7: Fine-tune BERT
HW
Task Description
Data
Net
Hints
HW1
Task Description
Given survey results in the past 5 days in a specific state in U.S., then predict the percentage of new tested positive cases in the 5th day.
给前四天阳性病例的人数, 预测第5天的个人.
Data
# train_data size: 2699 x 118 (id + 37 states + 16 features x 5 days)
# test_data size: 1078 x 117 (without last day’s positive rate)
Train
118 X 16X8X1
MSELoss
SGD
Hints
simple : sample code
medium : Feature selection
strong : Different model architectures and optimizers
boss : L2 regularization and try more parameters
HW2
Task Description
- Data Preprocessing: Extract MFCC features from raw waveform (already done by TAs!)
- Classification: Perform framewise phoneme classification using pre-extracted MFCC features.
Task: Multiclass Classification
Framewise phoneme prediction from speech.
Data

而一个frame是39维度的向量.
Train
self.block = nn.Sequential(
nn.Linear(input_dim, output_dim),
nn.ReLU(),
nn.BatchNorm1d(output_dim),
nn.Dropout(0.2)
Input: 39 * concat_nframes(11) = 429
block(input_dim, hidden_dim)
[0-n个block(input_dim, hidden_dim)]
output: 41(种类的个数)
注意这里是一个batch, 一个btach训练的, 以batch512为举例则一次训练是这样的:
x = 512 X 429, y = 512 X 1 这个1有41个取值0-40.
CrossEntropy
AdamW
Hints
● (1%) Simple baseline: 0.45797 (sample code)
● (1%) Medium baseline: 0.69747 (concat n frames, add layers)
● (1%) Strong baseline: 0.75028 (concat n, batchnorm, dropout, add layers)
● (1%) Boss baseline: 0.82324 (sequence-labeling(using RNN))
欢迎在评论区中进行批评指正,转载请注明来源,如涉及侵权,请联系作者删除。

