论文阅读
0 摘要
作者通过seq2seq发展了两个在表格生成的新的技术:
- table constaint
- table relation embedings
实验结果展示了vanilla seq2seq模型必实体抽取和关系抽取的方法效果更好.
1 介绍
任务是这样的:
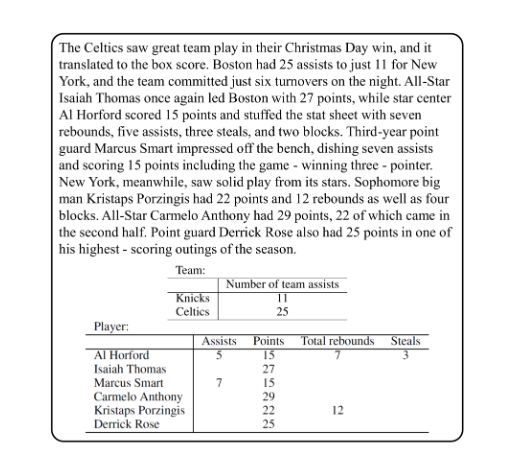
输入文本和表格对, 学习信息抽取的模型然后用来处理输入文本以形成新的一个或多个表格.
text-to-data可以分为两种级别:
- sentence-level
- document-level
但是两种界限不是很明确, 文档级别可能形成更复杂的输出: 体现在很多列和很多行, 比较复杂, 而且text-to-table不必预定义schema和annotation.
这项工作基于text-to-text/data-to-text, 后者是形成对于某个文档(数据)的描述, 所以可以把text-to-table作为table-to-text的反任务.
作者把text-to-table作为一项seq2seq2任务来做.Table constaint控制了行的生成, 而table relation embeddings影响着单元的对其以及行头和列头.
这项任务与之前信息任务抽取不同的是其他模型抽取都是从短文本而不是长文本, 另外抽取的信息结构非常简单而不是一种复杂比如表格信息.
2 相关工作
3 Problem Formulation
问题: 从文本中X中抽取T=nr*nc个单词序列.
有三种表格形式:
- 行列都有
- 只有行头
- 只有列头
text-to-table可以被转化为不同的应用比如documentation summarization 和 text mining.
text-to-table和IE不同的是抽取的目标结果是复杂的而不是被清楚定义的.
text-to-table有如下挑战:
- 同时有text和table很难, 人工构建数据很昂贵.
- 一些结构化的数据很难用表格表示, 比如知识图谱.
- 评估表格抽取不是很简单, 有很多影响因素比如表头, 内容和结构.
4 Our Method
4.1 Vanilla Seq2Seq
作者把该任务当作一个Seq2Seq的问题.输入的X是富文本, 输出的Y是序列化的表格.
模型以自回归的方式生成, 目标是减少交叉熵.
作者把他们的模型叫做 vanilla seq2seq.
模型训练好后去处理新的输入, 不会一定生成标准化的表格, 所以作者对输出序列进行了再处理来形成表格, 再处理把第一行当作已经定义好的, 把后续的行的对应列的位置都删除(也就是当作空白cell).
“The post-processing method takes the first row generated as well-defined, deletes extra cells at the end of the other rows, and inserts empty cells at the end of the other rows.” (Wu 等。, 2022, p. 4)
4.2 Techniques
作者用两种方法提升table的生成.
- Table Constraint
表格对其.计算第一行单元的数量然后用它来约束后面几行的形式.(ps:我觉得这里可以改进) - Table Relation Embedings
将表关系钱如合并到了Transformer解码器的自注意中.
5 Experiments
5.1 Datasets
用了四个现有的data-to-text数据集:
- E2E
餐饮领域,一个实例是一个短文本和自动构建的表格.因为自动构建所以表格缺少多样性. - WikiTableText
开防域数据集, 每个实例包含一个文本和一个表格, 文本是描述, 表格一行两列. - WikiBio
传记, 实例=长文本+表格. 文本是维基百科表述, 表格是有行头的两列.文本包含的信息要比表格信息多. - Rotowire
体育领域, 两个表格对应一个文本
并且过滤了出现在table但没有出现在text的数据.
5.2 Procedure
5.3 Results on Rotowire
5.4 Results on E2E, WikitiTableText and WikiBio
5.5 Additional Study
本文基于vanilla seq2seq进行了两处改进:
- Table constraint(TC)
- Table relation embeddings(TAE)
TC和TAE的改进在Rotowire上表现很好, 但是在其他三个数据集上没有改进. 说明两处改进当任务比较难的时候会更有效.
利用预训练模型对所有数据集都可以提升尤其是任务比较复杂和数据量比较小的情况.
vanilla seq2seq很难追踪每行所对应的列, 并且列头的对其也很难(所以作者才提出了TC和TAE).
BART和BART large相比较, 后者更有效, 所以大的预训练模型在处理这类任务更有效.
5.6 Discussion
本文用了四个数据集然后有五种挑战
- Text Diversity
Rotowire数据有不同的名词指代同一个事物. - Text Redundancy
WikiBio有很多信息冗余, 所以需要整合信息的能力 - Large Table
Rotowire的表格非常大, 列很多. - Background Knowlege
WikiTableText和WikiBio是开防域知识, 所以需要一些背景知识.
解决办法是用预训练模型或者额外的知识库. - Reasoning
推理知识, 一些知识需要推理才能得出, 比如A和B大比赛, A第一节以31-14领先, 隐含A-B第一节.31:14
6 Conclusion
- 提出了新的IE任务text-to-table
- 方法可以从短/长文本中抽取简单/复杂表格.
- 把文本-表格形式化为在预训练模型之上的序列到序列问题.
- 提出了改进的seq2seq以及Table constraint和Table relation embeddings技术
- 将改进用于4个数据集上, 比已存在的传统IE技术表现都好.
- 有5个问题/挑战.
data
展示data的具体形式
e2e
train.text instance1
The Vaults pub near Café Adriatic has a 5 star rating. Prices start at £30.
train.data instance1
| Name | The vaults |
|---|---|
| Price range | More than £30 |
| Customer rating | 5 out of 5 |
| Near | Café adriatic |
Rotowire
train.text instance2
The Phoenix Suns (39 - 38) escaped with an 87 - 85 win over the Utah Jazz (34 - 42). Rodney Hood missed the game - winning three - pointer at the buzzer. He was potentially fouled, but the official ruled otherwise. The Suns moved to three and a half games behind the Oklahoma City Thunder for the final playoff spot with five games remaining. Gerald Green scored 24 points in just 22 minutes for the first time since November 26th. After three straight double - figure scoring games, rookie T.J. Warren was limited to four points with Green putting on a show. Brandan Wright continues to start for the injured Alex Len, supplying 14 points, three rebounds, four blocks, three steals and one assist in 33 minutes. Trey Burke was dealing with back issues and didn’t play. Dante Exum was joined in the starting lineup by fellow rookie Rodney Hood, who was cleared of concussion symptoms after missing the previous game. Hood replaced Joe Ingles in the starting lineup and scored 17 points. He entered the game shooting 47 percent from the field since the All-Star break. Gordon Hayward scored 21 points on 18 shots and Rudy Gobert, potential Defensive Player of the Year, provided eight points, 15 rebounds, two assists, one steal and one block in 38 minutes. The Suns engage in a four - game road trip Tuesday beginning against the Atlanta Hawks. The Jazz conclude a two - game, two - day road trip when they play the Sacramento Kings on Sunday before hosting them three days later.
train.data instance2
| Team | Losses | Total points | Wins |
|---|---|---|---|
| Suns | 38 | 87 | 39 |
| Jazz | 42 | 85 | 34 |
| Player | Assists | Blocks | 3-pointers made | Field goals attempted | Minutes played | Points | Total rebounds | Steals |
|---|---|---|---|---|---|---|---|---|
| Gordon Hayward | 18 | 21 | ||||||
| Rudy Gobert | 2 | 1 | 38 | 8 | 15 | 1 | ||
| Rodney Hood | 17 | |||||||
| Brandan Wright | 1 | 4 | 33 | 14 | 3 | 3 | ||
| TJ Warren | 4 | |||||||
| Gerald Green | 3 | 22 | 24 | |||||
wikibio
train.text
walter extra is a german award-winning aerobatic pilot, chief aircraft designer and founder of extra flugzeugbau (extra aircraft construction), a manufacturer of aerobatic aircraft. extra was trained as a mechanical engineer. he began his flight training in gliders, transitioning to powered aircraft to perform aerobatics. he built and flew a pitts special aircraft and later built his own extra ea-230. extra began designing aircraft after competing in the 1982 world aerobatic championships. his aircraft constructions revolutionized the aerobatics flying scene and still dominate world competitions. the german pilot klaus schrodt won his world championship title flying an aircraft made by the extra firm. walter extra has designed a series of performance aircraft which include unlimited aerobatic aircraft and turboprop transports.
train.data
| occupation | aircraft designer and manufacturer |
|---|---|
| name | walter extra |
| nationality | german |
wikitabletext
train.text
philippines won thailand with 3–0 during 1978 federation cup.
train.data
| subtitle | qualifying round |
|---|---|
| winning team | philippines |
| score | 3–0 |
| losing team | thailand |
Training
训练部分log
bart.base custom_train.py LICENSE scripts
bart.base.tar.gz data README.md src
checkpoints data_realease.zip requirements.txt table_utils.py
mkdir: cannot create directory ‘checkpoints’: File exists
2022-07-25 10:17:54 | INFO | fairseq_cli.train | Namespace(activation_fn='gelu', adam_betas='(0.9, 0.999)', adam_eps=1e-08, adaptive_softmax_cutoff=None, adaptive_softmax_dropout=0, all_gather_list_size=16384, arch='bart_ours_base', attention_dropout=0.1, batch_size=None, batch_size_valid=None, best_checkpoint_metric='loss', bf16=False, bpe=None, broadcast_buffers=False, bucket_cap_mb=25, checkpoint_shard_count=1, checkpoint_suffix='', clip_norm=0.1, cpu=False, criterion='label_smoothed_cross_entropy', cross_self_attention=False, curriculum=0, data='data/rotowire//bins', data_buffer_size=10, dataset_impl=None, ddp_backend='c10d', decoder_attention_heads=12, decoder_embed_dim=768, decoder_embed_path=None, decoder_ffn_embed_dim=3072, decoder_input_dim=768, decoder_layerdrop=0, decoder_layers=6, decoder_layers_to_keep=None, decoder_learned_pos=True, decoder_normalize_before=False, decoder_output_dim=768, device_id=0, disable_validation=False, distributed_backend='nccl', distributed_init_method=None, distributed_no_spawn=False, distributed_num_procs=1, distributed_port=-1, distributed_rank=0, distributed_world_size=1, distributed_wrapper='DDP', dropout=0.1, empty_cache_freq=0, encoder_attention_heads=12, encoder_embed_dim=768, encoder_embed_path=None, encoder_ffn_embed_dim=3072, encoder_layerdrop=0, encoder_layers=6, encoder_layers_to_keep=None, encoder_learned_pos=True, encoder_normalize_before=False, eval_bleu=False, eval_bleu_args=None, eval_bleu_detok='space', eval_bleu_detok_args=None, eval_bleu_print_samples=False, eval_bleu_remove_bpe=None, eval_tokenized_bleu=False, fast_stat_sync=False, find_unused_parameters=True, finetune_from_model=None, fix_batches_to_gpus=False, fixed_validation_seed=None, fp16=True, fp16_init_scale=128, fp16_no_flatten_grads=False, fp16_scale_tolerance=0.0, fp16_scale_window=None, gen_subset='test', ignore_prefix_size=0, keep_best_checkpoints=3, keep_interval_updates=-1, keep_last_epochs=-1, label_smoothing=0.1, layernorm_embedding=True, left_pad_source='True', left_pad_target='False', load_alignments=False, localsgd_frequency=3, log_format=None, log_interval=100, lr=[3e-05], lr_scheduler='inverse_sqrt', max_epoch=0, max_source_positions=1024, max_target_positions=1024, max_tokens=4096, max_tokens_valid=4096, max_update=8000, maximize_best_checkpoint_metric=False, memory_efficient_bf16=False, memory_efficient_fp16=False, min_loss_scale=0.0001, min_lr=-1.0, model_parallel_size=1, newline_token='\n', no_cross_attention=False, no_epoch_checkpoints=False, no_last_checkpoints=False, no_progress_bar=False, no_save=False, no_save_optimizer_state=False, no_scale_embedding=True, no_seed_provided=False, no_token_positional_embeddings=False, nprocs_per_node=1, num_batch_buckets=0, num_shards=1, num_workers=16, optimizer='adam', optimizer_overrides='{}', patience=-1, pipeline_balance=None, pipeline_checkpoint='never', pipeline_chunks=0, pipeline_decoder_balance=None, pipeline_decoder_devices=None, pipeline_devices=None, pipeline_encoder_balance=None, pipeline_encoder_devices=None, pipeline_model_parallel=False, pooler_activation_fn='tanh', pooler_dropout=0.0, profile=False, quant_noise_pq=0, quant_noise_pq_block_size=8, quant_noise_scalar=0, quantization_config_path=None, relu_dropout=0.0, report_accuracy=False, required_batch_size_multiple=1, required_seq_len_multiple=1, reset_dataloader=True, reset_lr_scheduler=False, reset_meters=True, reset_optimizer=True, restore_file='bart.base//model.pt', return_relative_column_strs=['row_head', 'col_head'], save_dir='checkpoints', save_interval=10, save_interval_updates=0, scoring='bleu', seed=1, sentence_avg=False, shard_id=0, share_all_embeddings=True, share_decoder_input_output_embed=True, skip_invalid_size_inputs_valid_test=True, slowmo_algorithm='LocalSGD', slowmo_momentum=None, source_lang='text', split_token='|', stop_time_hours=0, table_max_columns=38, target_lang='data', task='text_to_table_task', tensorboard_logdir=None, threshold_loss_scale=None, tokenizer=None, tpu=False, train_subset='train', truncate_source=True, unconstrained_decoding=False, update_freq=[1], upsample_primary=1, use_bmuf=False, use_old_adam=False, user_dir='src/', valid_subset='valid', validate_after_updates=0, validate_interval=10, validate_interval_updates=0, warmup_init_lr=1e-07, warmup_updates=400, weight_decay=0.01, zero_sharding='none')
2022-07-25 10:17:56 | INFO | fairseq.tasks.translation | [text] dictionary: 51200 types
2022-07-25 10:17:56 | INFO | fairseq.tasks.translation | [data] dictionary: 51200 types
2022-07-25 10:17:56 | INFO | fairseq.file_utils | https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/encoder.json not found in cache, downloading to /tmp/tmp5cizzf_c
1042301B [00:00, 5309702.05B/s]2022-07-25 10:17:57 | INFO | fairseq.file_utils | copying /tmp/tmp5cizzf_c to cache at /root/.cache/torch/pytorch_fairseq/e2aab4d600e7568c2d88fc7732130ccc815ea84ec63906cb0913c7a3a4906a2e.0f323dfaed92d080380e63f0291d0f31adfa8c61a62cbcb3cb8114f061be27f7
2022-07-25 10:17:57 | INFO | fairseq.file_utils | creating metadata file for /root/.cache/torch/pytorch_fairseq/e2aab4d600e7568c2d88fc7732130ccc815ea84ec63906cb0913c7a3a4906a2e.0f323dfaed92d080380e63f0291d0f31adfa8c61a62cbcb3cb8114f061be27f7
2022-07-25 10:17:57 | INFO | fairseq.file_utils | removing temp file /tmp/tmp5cizzf_c
2022-07-25 10:17:57 | INFO | fairseq.file_utils | https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/vocab.bpe not found in cache, downloading to /tmp/tmpxj__5h9y
456318B [00:00, 6455663.61B/s]2022-07-25 10:17:57 | INFO | fairseq.file_utils | copying /tmp/tmpxj__5h9y to cache at /root/.cache/torch/pytorch_fairseq/b04a6d337c09f464fe8f0df1d3524db88a597007d63f05d97e437f65840cdba5.939bed25cbdab15712bac084ee713d6c78e221c5156c68cb0076b03f5170600f
2022-07-25 10:17:57 | INFO | fairseq.file_utils | creating metadata file for /root/.cache/torch/pytorch_fairseq/b04a6d337c09f464fe8f0df1d3524db88a597007d63f05d97e437f65840cdba5.939bed25cbdab15712bac084ee713d6c78e221c5156c68cb0076b03f5170600f
2022-07-25 10:17:57 | INFO | fairseq.file_utils | removing temp file /tmp/tmpxj__5h9y
2022-07-25 10:17:58 | INFO | fairseq.data.data_utils | loaded 727 examples from: data/rotowire//bins/valid.text-data.text
2022-07-25 10:17:58 | INFO | fairseq.data.data_utils | loaded 727 examples from: data/rotowire//bins/valid.text-data.data
2022-07-25 10:17:58 | INFO | src.tasks.text_to_table_task | data/rotowire//bins valid text-data 727 examples
2022-07-25 10:18:02 | INFO | fairseq_cli.train | BARTOurs(
(encoder): TransformerEncoder(
(dropout_module): FairseqDropout()
(embed_tokens): Embedding(51200, 768, padding_idx=1)
(embed_positions): LearnedPositionalEmbedding(1026, 768, padding_idx=1)
(layernorm_embedding): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(layers): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(self_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout_module): FairseqDropout()
(activation_dropout_module): FairseqDropout()
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(1): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(self_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout_module): FairseqDropout()
(activation_dropout_module): FairseqDropout()
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(2): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(self_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout_module): FairseqDropout()
(activation_dropout_module): FairseqDropout()
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(3): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(self_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout_module): FairseqDropout()
(activation_dropout_module): FairseqDropout()
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(4): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(self_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout_module): FairseqDropout()
(activation_dropout_module): FairseqDropout()
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(5): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(self_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout_module): FairseqDropout()
(activation_dropout_module): FairseqDropout()
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
)
(decoder): TransformerOursDecoder(
(dropout_module): FairseqDropout()
(embed_tokens): Embedding(51200, 768, padding_idx=1)
(embed_positions): LearnedPositionalEmbedding(1026, 768, padding_idx=1)
(layernorm_embedding): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(layers): ModuleList(
(0): TransformerRelativeEmbeddingsDecoderLayer(
(dropout_module): FairseqDropout()
(self_attn): RelativeEmbeddingsMultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(relation_k_emb): Embedding(3, 64, padding_idx=0)
(relation_v_emb): Embedding(3, 64, padding_idx=0)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(activation_dropout_module): FairseqDropout()
(self_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(encoder_attn): MultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(encoder_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(1): TransformerRelativeEmbeddingsDecoderLayer(
(dropout_module): FairseqDropout()
(self_attn): RelativeEmbeddingsMultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(relation_k_emb): Embedding(3, 64, padding_idx=0)
(relation_v_emb): Embedding(3, 64, padding_idx=0)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(activation_dropout_module): FairseqDropout()
(self_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(encoder_attn): MultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(encoder_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(2): TransformerRelativeEmbeddingsDecoderLayer(
(dropout_module): FairseqDropout()
(self_attn): RelativeEmbeddingsMultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(relation_k_emb): Embedding(3, 64, padding_idx=0)
(relation_v_emb): Embedding(3, 64, padding_idx=0)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(activation_dropout_module): FairseqDropout()
(self_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(encoder_attn): MultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(encoder_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(3): TransformerRelativeEmbeddingsDecoderLayer(
(dropout_module): FairseqDropout()
(self_attn): RelativeEmbeddingsMultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(relation_k_emb): Embedding(3, 64, padding_idx=0)
(relation_v_emb): Embedding(3, 64, padding_idx=0)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(activation_dropout_module): FairseqDropout()
(self_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(encoder_attn): MultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(encoder_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(4): TransformerRelativeEmbeddingsDecoderLayer(
(dropout_module): FairseqDropout()
(self_attn): RelativeEmbeddingsMultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(relation_k_emb): Embedding(3, 64, padding_idx=0)
(relation_v_emb): Embedding(3, 64, padding_idx=0)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(activation_dropout_module): FairseqDropout()
(self_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(encoder_attn): MultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(encoder_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(5): TransformerRelativeEmbeddingsDecoderLayer(
(dropout_module): FairseqDropout()
(self_attn): RelativeEmbeddingsMultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(relation_k_emb): Embedding(3, 64, padding_idx=0)
(relation_v_emb): Embedding(3, 64, padding_idx=0)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(activation_dropout_module): FairseqDropout()
(self_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(encoder_attn): MultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(encoder_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
(output_projection): Linear(in_features=768, out_features=51200, bias=False)
)
(classification_heads): ModuleDict()
)
2022-07-25 10:18:02 | INFO | fairseq_cli.train | task: text_to_table_task (TextToDataTranslationTask)
2022-07-25 10:18:02 | INFO | fairseq_cli.train | model: bart_ours_base (BARTOurs)
2022-07-25 10:18:02 | INFO | fairseq_cli.train | criterion: label_smoothed_cross_entropy (LabelSmoothedCrossEntropyCriterion)
2022-07-25 10:18:02 | INFO | fairseq_cli.train | num. model params: 140140800 (num. trained: 140140800)
2022-07-25 10:18:06 | INFO | fairseq.trainer | detected shared parameter: encoder.embed_tokens.weight <- decoder.embed_tokens.weight
2022-07-25 10:18:06 | INFO | fairseq.trainer | detected shared parameter: encoder.embed_tokens.weight <- decoder.output_projection.weight
2022-07-25 10:18:06 | INFO | fairseq.utils | ***********************CUDA enviroments for all 1 workers***********************
2022-07-25 10:18:06 | INFO | fairseq.utils | rank 0: capabilities = 7.5 ; total memory = 14.756 GB ; name = Tesla T4
2022-07-25 10:18:06 | INFO | fairseq.utils | ***********************CUDA enviroments for all 1 workers***********************
2022-07-25 10:18:06 | INFO | fairseq_cli.train | training on 1 devices (GPUs/TPUs)
2022-07-25 10:18:06 | INFO | fairseq_cli.train | max tokens per GPU = 4096 and max sentences per GPU = None
2022-07-25 10:18:12 | INFO | fairseq.trainer | loaded checkpoint bart.base//model.pt (epoch 14 @ 0 updates)
2022-07-25 10:18:12 | INFO | fairseq.trainer | loading train data for epoch 1
2022-07-25 10:18:13 | INFO | fairseq.data.data_utils | loaded 3398 examples from: data/rotowire//bins/train.text-data.text
2022-07-25 10:18:13 | INFO | fairseq.data.data_utils | loaded 3398 examples from: data/rotowire//bins/train.text-data.data
2022-07-25 10:18:13 | INFO | src.tasks.text_to_table_task | data/rotowire//bins train text-data 3398 examples
2022-07-25 10:18:13 | INFO | fairseq.trainer | begin training epoch 1
/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py:560: UserWarning: This DataLoader will create 16 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
cpuset_checked))
2022-07-25 10:18:22 | INFO | fairseq.trainer | NOTE: overflow detected, setting loss scale to: 64.0
2022-07-25 10:18:23 | INFO | fairseq.trainer | NOTE: overflow detected, setting loss scale to: 32.0
2022-07-25 10:18:24 | INFO | fairseq.trainer | NOTE: overflow detected, setting loss scale to: 16.0
2022-07-25 10:18:25 | INFO | fairseq.trainer | NOTE: overflow detected, setting loss scale to: 8.0
2022-07-25 10:18:25 | INFO | fairseq.trainer | NOTE: overflow detected, setting loss scale to: 4.0
2022-07-25 10:18:26 | INFO | fairseq.trainer | NOTE: overflow detected, setting loss scale to: 2.0
2022-07-25 10:18:33 | INFO | fairseq.trainer | NOTE: overflow detected, setting loss scale to: 1.0
2022-07-25 10:19:40 | INFO | train_inner | epoch 001: 107 / 331 loss=5.865, nll_loss=3.995, ppl=15.95, wps=2880.7, ups=1.35, wpb=2134.3, bsz=10.1, num_updates=100, lr=7.575e-06, gnorm=11.04, clip=100, loss_scale=1, train_wall=74, wall=94
2022-07-25 10:20:58 | INFO | train_inner | epoch 001: 207 / 331 loss=3.557, nll_loss=1.568, ppl=2.97, wps=2898.6, ups=1.28, wpb=2260.2, bsz=9.8, num_updates=200, lr=1.505e-05, gnorm=3.683, clip=100, loss_scale=1, train_wall=78, wall=172
2022-07-25 10:22:15 | INFO | train_inner | epoch 001: 307 / 331 loss=3.062, nll_loss=1.116, ppl=2.17, wps=2862.8, ups=1.3, wpb=2199.1, bsz=10.6, num_updates=300, lr=2.2525e-05, gnorm=3.358, clip=100, loss_scale=1, train_wall=77, wall=249
2022-07-25 10:22:34 | INFO | fairseq_cli.train | end of epoch 1 (average epoch stats below)
2022-07-25 12:05:19 | INFO | fairseq.trainer | begin training epoch 25
2022-07-25 12:06:13 | INFO | train_inner | epoch 025: 63 / 331 loss=2.161, nll_loss=0.265, ppl=1.2, wps=2734.4, ups=1.2, wpb=2273.2, bsz=10.2, num_updates=8000, lr=6.7082e-06, gnorm=0.777, clip=100, loss_scale=1, train_wall=80, wall=6487
2022-07-25 12:06:13 | INFO | fairseq_cli.train | begin validation on "valid" subset
2022-07-25 12:06:33 | INFO | valid | epoch 025 | valid on 'valid' subset | loss 2.254 | nll_loss 0.309 | ppl 1.24 | wps 8967.9 | wpb 2200.4 | bsz 10.1 | num_updates 8000
2022-07-25 12:06:33 | INFO | fairseq_cli.train | begin save checkpoint
2022-07-25 12:07:01 | INFO | fairseq_cli.train | saved checkpoint checkpoints/checkpoint_last.pt (epoch 25 @ 8000 updates, score 2.254) (writing took 28.426666919000127 seconds)
2022-07-25 12:07:01 | INFO | fairseq_cli.train | end of epoch 25 (average epoch stats below)
2022-07-25 12:07:01 | INFO | train | epoch 025 | loss 2.163 | nll_loss 0.267 | ppl 1.2 | wps 1423.3 | ups 0.62 | wpb 2304.1 | bsz 10.5 | num_updates 8000 | lr 6.7082e-06 | gnorm 0.767 | clip 100 | loss_scale 1 | train_wall 51 | wall 6535
2022-07-25 12:07:01 | INFO | fairseq_cli.train | done training in 6527.9 seconds
-rw------- 1 root root 1.9G Jul 25 12:07 checkpoints//checkpoint_25_8000.best_2.2540.pt
-rw------- 1 root root 1.9G Jul 25 12:06 checkpoints//checkpoint_last.pt
-rw------- 1 root root 1.9G Jul 25 11:47 checkpoints//checkpoint20.best_2.2500.pt
-rw------- 1 root root 1.9G Jul 25 11:47 checkpoints//checkpoint_best.pt
-rw------- 1 root root 1.9G Jul 25 11:46 checkpoints//checkpoint20.pt
-rw------- 1 root root 1.9G Jul 25 11:02 checkpoints//checkpoint10.best_2.2760.pt
-rw------- 1 root root 1.9G Jul 25 11:02 checkpoints//checkpoint10.pt
checkpoints//checkpoint_25_8000.best_2.2540.pt checkpoints//checkpoint20.best_2.2500.pt checkpoints//checkpoint10.best_2.2760.pt
Namespace(checkpoint_upper_bound=None, inputs=['checkpoints//checkpoint_25_8000.best_2.2540.pt', 'checkpoints//checkpoint20.best_2.2500.pt', 'checkpoints//checkpoint10.best_2.2760.pt'], num_epoch_checkpoints=None, num_update_checkpoints=None, output='checkpoints//checkpoint_average_best-3.pt')
tesla T4, 7.5, 6527.9s
Inference and Evaluation
rotowire
/content/drive/MyDrive/text_to_table
/content/drive/MyDrive/text_to_table
/usr/local/lib/python3.7/dist-packages/fairseq/search.py:140: UserWarning: __floordiv__ is deprecated, and its behavior will change in a future version of pytorch. It currently rounds toward 0 (like the 'trunc' function NOT 'floor'). This results in incorrect rounding for negative values. To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'), or for actual floor division, use torch.div(a, b, rounding_mode='floor').
beams_buf = indices_buf // vocab_size
/usr/local/lib/python3.7/dist-packages/fairseq/sequence_generator.py:651: UserWarning: __floordiv__ is deprecated, and its behavior will change in a future version of pytorch. It currently rounds toward 0 (like the 'trunc' function NOT 'floor'). This results in incorrect rounding for negative values. To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'), or for actual floor division, use torch.div(a, b, rounding_mode='floor').
unfin_idx = idx // beam_size
Team table wrong format:
Args Namespace(col_header=True, hyp='checkpoints/checkpoint_average_best-3.pt.test_vanilla.out.text', row_header=True, table_name='Team', tgt='data/rotowire//test.data')
Wrong format: 1 / 687 (0.15%)
Team table E metric:
Args Namespace(col_header=True, hyp='checkpoints/checkpoint_average_best-3.pt.test_vanilla.out.text', metric='E', row_header=True, table_name='Team', tgt='data/rotowire//test.data')
0% 0/728 [00:00<?, ?it/s]scripts/eval/calc_data_f_score.py:94: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
return np.array([[calc_data_similarity(tgt, pred) for pred in pred_data] for tgt in tgt_data], dtype=np.float)
100% 728/728 [00:00<00:00, 2624.38it/s]
Row header: precision = 94.98; recall = 94.54; f1 = 94.40
Col header: precision = 89.23; recall = 85.43; f1 = 86.07
Non-header cell: precision = 84.45; recall = 84.02; f1 = 83.34
Team table c metric:
Args Namespace(col_header=True, hyp='checkpoints/checkpoint_average_best-3.pt.test_vanilla.out.text', metric='c', row_header=True, table_name='Team', tgt='data/rotowire//test.data')
0% 0/728 [00:00<?, ?it/s]scripts/eval/calc_data_f_score.py:94: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
return np.array([[calc_data_similarity(tgt, pred) for pred in pred_data] for tgt in tgt_data], dtype=np.float)
100% 728/728 [00:00<00:00, 739.09it/s]
Row header: precision = 95.16; recall = 94.74; f1 = 94.64
Col header: precision = 91.29; recall = 88.32; f1 = 88.96
Non-header cell: precision = 85.66; recall = 85.06; f1 = 84.49
Team table BS-scaled metric:
Args Namespace(col_header=True, hyp='checkpoints/checkpoint_average_best-3.pt.test_vanilla.out.text', metric='BS-scaled', row_header=True, table_name='Team', tgt='data/rotowire//test.data')
0% 0/728 [00:00<?, ?it/s]
Downloading: 100% 482/482 [00:00<00:00, 716kB/s]
Downloading: 0% 0.00/878k [00:00<?, ?B/s]
Downloading: 100% 878k/878k [00:00<00:00, 5.29MB/s]
Downloading: 0% 0.00/446k [00:00<?, ?B/s]
Downloading: 100% 446k/446k [00:00<00:00, 3.15MB/s]
Downloading: 0% 0.00/1.33G [00:00<?, ?B/s]
Downloading: 0% 4.20M/1.33G [00:00<00:32, 44.1MB/s]
Downloading: 1% 11.4M/1.33G [00:00<00:22, 62.3MB/s]
Downloading: 1% 17.8M/1.33G [00:00<00:21, 64.8MB/s]
Downloading: 2% 24.0M/1.33G [00:00<00:23, 59.9MB/s]
Downloading: 2% 29.8M/1.33G [00:00<00:23, 60.2MB/s]
Downloading: 3% 35.6M/1.33G [00:00<00:22, 60.5MB/s]
Downloading: 3% 41.4M/1.33G [00:00<00:23, 59.6MB/s]
Downloading: 4% 47.8M/1.33G [00:00<00:22, 61.9MB/s]
Downloading: 4% 54.7M/1.33G [00:00<00:21, 65.0MB/s]
Downloading: 4% 60.9M/1.33G [00:01<00:21, 64.4MB/s]
Downloading: 5% 67.7M/1.33G [00:01<00:20, 66.5MB/s]
Downloading: 5% 74.0M/1.33G [00:01<00:20, 66.2MB/s]
Downloading: 6% 80.4M/1.33G [00:01<00:21, 63.6MB/s]
Downloading: 6% 87.2M/1.33G [00:01<00:20, 65.8MB/s]
Downloading: 7% 94.4M/1.33G [00:01<00:19, 68.6MB/s]
Downloading: 7% 101M/1.33G [00:01<00:19, 68.1MB/s]
Downloading: 8% 107M/1.33G [00:01<00:20, 63.3MB/s]
Downloading: 8% 114M/1.33G [00:01<00:23, 56.7MB/s]
Downloading: 9% 120M/1.33G [00:02<00:21, 60.6MB/s]
Downloading: 9% 128M/1.33G [00:02<00:19, 64.6MB/s]
Downloading: 10% 134M/1.33G [00:02<00:19, 65.6MB/s]
Downloading: 10% 141M/1.33G [00:02<00:18, 68.4MB/s]
Downloading: 11% 148M/1.33G [00:02<00:20, 63.3MB/s]
Downloading: 11% 154M/1.33G [00:02<00:20, 62.7MB/s]
Downloading: 12% 160M/1.33G [00:02<00:22, 55.8MB/s]
Downloading: 12% 166M/1.33G [00:02<00:21, 57.4MB/s]
Downloading: 13% 173M/1.33G [00:02<00:20, 61.4MB/s]
Downloading: 13% 179M/1.33G [00:02<00:20, 61.7MB/s]
Downloading: 14% 185M/1.33G [00:03<00:20, 59.8MB/s]
Downloading: 14% 191M/1.33G [00:03<00:22, 54.5MB/s]
Downloading: 14% 196M/1.33G [00:03<00:23, 51.6MB/s]
Downloading: 15% 201M/1.33G [00:03<00:24, 50.1MB/s]
Downloading: 15% 207M/1.33G [00:03<00:22, 54.4MB/s]
Downloading: 16% 213M/1.33G [00:03<00:23, 51.5MB/s]
Downloading: 16% 219M/1.33G [00:03<00:21, 55.2MB/s]
Downloading: 17% 224M/1.33G [00:03<00:21, 56.6MB/s]
Downloading: 17% 231M/1.33G [00:04<00:20, 59.1MB/s]
Downloading: 17% 237M/1.33G [00:04<00:18, 62.5MB/s]
Downloading: 18% 244M/1.33G [00:04<00:18, 63.2MB/s]
Downloading: 18% 250M/1.33G [00:04<00:19, 60.7MB/s]
Downloading: 19% 256M/1.33G [00:04<00:19, 59.0MB/s]
Downloading: 19% 261M/1.33G [00:04<00:19, 58.9MB/s]
Downloading: 20% 267M/1.33G [00:04<00:19, 58.0MB/s]
Downloading: 20% 273M/1.33G [00:04<00:19, 59.2MB/s]
Downloading: 21% 280M/1.33G [00:04<00:18, 62.7MB/s]
Downloading: 21% 286M/1.33G [00:04<00:19, 58.7MB/s]
Downloading: 21% 292M/1.33G [00:05<00:18, 61.2MB/s]
Downloading: 22% 298M/1.33G [00:05<00:18, 61.3MB/s]
Downloading: 22% 304M/1.33G [00:05<00:17, 62.6MB/s]
Downloading: 23% 311M/1.33G [00:05<00:17, 64.0MB/s]
Downloading: 23% 317M/1.33G [00:05<00:16, 65.1MB/s]
Downloading: 24% 324M/1.33G [00:05<00:16, 66.7MB/s]
Downloading: 24% 330M/1.33G [00:05<00:16, 67.0MB/s]
Downloading: 25% 337M/1.33G [00:05<00:16, 65.5MB/s]
Downloading: 25% 344M/1.33G [00:05<00:15, 68.0MB/s]
Downloading: 26% 350M/1.33G [00:06<00:20, 51.5MB/s]
Downloading: 26% 356M/1.33G [00:06<00:19, 54.8MB/s]
Downloading: 27% 362M/1.33G [00:06<00:18, 55.7MB/s]
Downloading: 27% 369M/1.33G [00:06<00:17, 58.7MB/s]
Downloading: 28% 375M/1.33G [00:06<00:16, 60.9MB/s]
Downloading: 28% 382M/1.33G [00:06<00:16, 63.8MB/s]
Downloading: 29% 388M/1.33G [00:06<00:17, 58.4MB/s]
Downloading: 29% 394M/1.33G [00:06<00:17, 58.9MB/s]
Downloading: 29% 400M/1.33G [00:06<00:16, 61.7MB/s]
Downloading: 30% 406M/1.33G [00:07<00:17, 56.6MB/s]
Downloading: 30% 412M/1.33G [00:07<00:18, 53.3MB/s]
Downloading: 31% 417M/1.33G [00:07<00:23, 42.6MB/s]
Downloading: 31% 423M/1.33G [00:07<00:20, 47.6MB/s]
Downloading: 32% 430M/1.33G [00:07<00:18, 52.8MB/s]
Downloading: 32% 435M/1.33G [00:07<00:20, 46.6MB/s]
Downloading: 32% 441M/1.33G [00:07<00:19, 50.4MB/s]
Downloading: 33% 447M/1.33G [00:07<00:18, 52.8MB/s]
Downloading: 33% 453M/1.33G [00:08<00:16, 56.3MB/s]
Downloading: 34% 459M/1.33G [00:08<00:15, 59.1MB/s]
Downloading: 34% 465M/1.33G [00:08<00:17, 52.6MB/s]
Downloading: 35% 470M/1.33G [00:08<00:18, 50.2MB/s]
Downloading: 35% 476M/1.33G [00:08<00:17, 51.5MB/s]
Downloading: 35% 481M/1.33G [00:08<00:17, 52.8MB/s]
Downloading: 36% 487M/1.33G [00:08<00:16, 55.3MB/s]
Downloading: 36% 492M/1.33G [00:08<00:16, 56.0MB/s]
Downloading: 37% 500M/1.33G [00:08<00:14, 61.2MB/s]
Downloading: 37% 505M/1.33G [00:09<00:15, 59.1MB/s]
Downloading: 38% 512M/1.33G [00:09<00:14, 62.6MB/s]
Downloading: 38% 518M/1.33G [00:09<00:14, 61.5MB/s]
Downloading: 39% 525M/1.33G [00:09<00:13, 64.8MB/s]
Downloading: 39% 531M/1.33G [00:09<00:13, 64.0MB/s]
Downloading: 40% 538M/1.33G [00:09<00:14, 60.1MB/s]
Downloading: 40% 544M/1.33G [00:09<00:13, 62.1MB/s]
Downloading: 40% 551M/1.33G [00:09<00:13, 64.0MB/s]
Downloading: 41% 557M/1.33G [00:09<00:13, 61.4MB/s]
Downloading: 41% 563M/1.33G [00:09<00:14, 57.4MB/s]
Downloading: 42% 568M/1.33G [00:10<00:14, 58.7MB/s]
Downloading: 42% 574M/1.33G [00:10<00:13, 59.3MB/s]
Downloading: 43% 580M/1.33G [00:10<00:14, 56.5MB/s]
Downloading: 43% 586M/1.33G [00:10<00:14, 57.0MB/s]
Downloading: 44% 592M/1.33G [00:10<00:13, 58.6MB/s]
Downloading: 44% 598M/1.33G [00:10<00:12, 62.0MB/s]
Downloading: 44% 604M/1.33G [00:10<00:12, 61.1MB/s]
Downloading: 45% 610M/1.33G [00:10<00:13, 58.6MB/s]
Downloading: 45% 616M/1.33G [00:10<00:14, 55.3MB/s]
Downloading: 46% 621M/1.33G [00:11<00:14, 54.9MB/s]
Downloading: 46% 626M/1.33G [00:11<00:22, 34.2MB/s]
Downloading: 47% 633M/1.33G [00:11<00:18, 42.1MB/s]
Downloading: 47% 641M/1.33G [00:11<00:14, 50.4MB/s]
Downloading: 48% 648M/1.33G [00:11<00:13, 56.7MB/s]
Downloading: 48% 655M/1.33G [00:11<00:12, 60.8MB/s]
Downloading: 49% 662M/1.33G [00:11<00:11, 61.9MB/s]
Downloading: 49% 669M/1.33G [00:11<00:11, 65.1MB/s]
Downloading: 50% 676M/1.33G [00:12<00:10, 68.7MB/s]
Downloading: 50% 683M/1.33G [00:12<00:10, 68.4MB/s]
Downloading: 51% 690M/1.33G [00:12<00:09, 70.6MB/s]
Downloading: 51% 697M/1.33G [00:12<00:11, 60.8MB/s]
Downloading: 52% 704M/1.33G [00:12<00:10, 64.7MB/s]
Downloading: 52% 711M/1.33G [00:12<00:10, 63.5MB/s]
Downloading: 53% 717M/1.33G [00:12<00:11, 60.2MB/s]
Downloading: 53% 723M/1.33G [00:12<00:10, 61.6MB/s]
Downloading: 54% 729M/1.33G [00:12<00:10, 62.5MB/s]
Downloading: 54% 736M/1.33G [00:13<00:10, 63.1MB/s]
Downloading: 55% 742M/1.33G [00:13<00:10, 62.2MB/s]
Downloading: 55% 748M/1.33G [00:13<00:10, 63.2MB/s]
Downloading: 55% 754M/1.33G [00:13<00:11, 57.7MB/s]
Downloading: 56% 760M/1.33G [00:13<00:10, 58.9MB/s]
Downloading: 56% 767M/1.33G [00:13<00:09, 62.5MB/s]
Downloading: 57% 773M/1.33G [00:13<00:10, 58.7MB/s]
Downloading: 57% 779M/1.33G [00:13<00:10, 59.3MB/s]
Downloading: 58% 785M/1.33G [00:13<00:09, 61.1MB/s]
Downloading: 58% 792M/1.33G [00:14<00:09, 63.8MB/s]
Downloading: 59% 798M/1.33G [00:14<00:09, 64.9MB/s]
Downloading: 59% 804M/1.33G [00:14<00:09, 61.2MB/s]
Downloading: 60% 810M/1.33G [00:14<00:09, 58.7MB/s]
Downloading: 60% 816M/1.33G [00:14<00:11, 49.1MB/s]
Downloading: 60% 821M/1.33G [00:14<00:12, 45.4MB/s]
Downloading: 61% 826M/1.33G [00:14<00:12, 44.9MB/s]
Downloading: 61% 832M/1.33G [00:14<00:11, 49.5MB/s]
Downloading: 62% 838M/1.33G [00:15<00:10, 53.5MB/s]
Downloading: 62% 843M/1.33G [00:15<00:10, 49.7MB/s]
Downloading: 62% 848M/1.33G [00:15<00:10, 49.5MB/s]
Downloading: 63% 854M/1.33G [00:15<00:09, 54.1MB/s]
Downloading: 63% 860M/1.33G [00:15<00:09, 56.3MB/s]
Downloading: 64% 866M/1.33G [00:15<00:09, 52.2MB/s]
Downloading: 64% 871M/1.33G [00:15<00:10, 49.8MB/s]
Downloading: 64% 877M/1.33G [00:15<00:09, 53.5MB/s]
Downloading: 65% 883M/1.33G [00:15<00:08, 57.6MB/s]
Downloading: 65% 889M/1.33G [00:15<00:08, 59.3MB/s]
Downloading: 66% 896M/1.33G [00:16<00:07, 60.9MB/s]
Downloading: 66% 903M/1.33G [00:16<00:07, 66.4MB/s]
Downloading: 67% 909M/1.33G [00:16<00:07, 63.2MB/s]
Downloading: 67% 916M/1.33G [00:16<00:07, 63.5MB/s]
Downloading: 68% 922M/1.33G [00:16<00:09, 48.9MB/s]
Downloading: 68% 927M/1.33G [00:16<00:09, 49.6MB/s]
Downloading: 69% 933M/1.33G [00:16<00:08, 52.9MB/s]
Downloading: 69% 939M/1.33G [00:16<00:07, 55.5MB/s]
Downloading: 69% 945M/1.33G [00:17<00:07, 56.7MB/s]
Downloading: 70% 950M/1.33G [00:17<00:07, 56.5MB/s]
Downloading: 70% 956M/1.33G [00:17<00:07, 56.1MB/s]
Downloading: 71% 961M/1.33G [00:17<00:07, 56.6MB/s]
Downloading: 71% 967M/1.33G [00:17<00:07, 52.1MB/s]
Downloading: 72% 973M/1.33G [00:17<00:07, 56.9MB/s]
Downloading: 72% 980M/1.33G [00:17<00:06, 60.4MB/s]
Downloading: 73% 987M/1.33G [00:17<00:06, 63.5MB/s]
Downloading: 73% 993M/1.33G [00:17<00:05, 64.5MB/s]
Downloading: 74% 0.98G/1.33G [00:17<00:05, 65.8MB/s]
Downloading: 74% 0.98G/1.33G [00:18<00:05, 64.8MB/s]
Downloading: 74% 0.99G/1.33G [00:18<00:05, 66.1MB/s]
Downloading: 75% 1.00G/1.33G [00:18<00:05, 66.3MB/s]
Downloading: 75% 1.00G/1.33G [00:18<00:05, 65.2MB/s]
Downloading: 76% 1.01G/1.33G [00:18<00:05, 63.9MB/s]
Downloading: 76% 1.01G/1.33G [00:18<00:05, 63.4MB/s]
Downloading: 77% 1.02G/1.33G [00:18<00:05, 59.5MB/s]
Downloading: 77% 1.03G/1.33G [00:18<00:05, 58.0MB/s]
Downloading: 78% 1.03G/1.33G [00:18<00:05, 57.4MB/s]
Downloading: 78% 1.04G/1.33G [00:19<00:05, 58.7MB/s]
Downloading: 78% 1.04G/1.33G [00:19<00:05, 57.7MB/s]
Downloading: 79% 1.05G/1.33G [00:19<00:05, 54.1MB/s]
Downloading: 79% 1.05G/1.33G [00:19<00:05, 58.2MB/s]
Downloading: 80% 1.06G/1.33G [00:19<00:04, 60.7MB/s]
Downloading: 80% 1.07G/1.33G [00:19<00:04, 63.5MB/s]
Downloading: 81% 1.07G/1.33G [00:19<00:04, 63.9MB/s]
Downloading: 81% 1.08G/1.33G [00:19<00:04, 65.5MB/s]
Downloading: 82% 1.09G/1.33G [00:19<00:04, 64.9MB/s]
Downloading: 82% 1.09G/1.33G [00:19<00:03, 65.6MB/s]
Downloading: 83% 1.10G/1.33G [00:20<00:03, 64.8MB/s]
Downloading: 83% 1.10G/1.33G [00:20<00:03, 65.6MB/s]
Downloading: 84% 1.11G/1.33G [00:20<00:03, 67.4MB/s]
Downloading: 84% 1.12G/1.33G [00:20<00:03, 67.6MB/s]
Downloading: 85% 1.12G/1.33G [00:20<00:03, 67.7MB/s]
Downloading: 85% 1.13G/1.33G [00:20<00:03, 64.8MB/s]
Downloading: 86% 1.14G/1.33G [00:20<00:03, 57.9MB/s]
Downloading: 86% 1.14G/1.33G [00:20<00:03, 59.5MB/s]
Downloading: 86% 1.15G/1.33G [00:20<00:03, 63.8MB/s]
Downloading: 87% 1.15G/1.33G [00:21<00:03, 58.4MB/s]
Downloading: 87% 1.16G/1.33G [00:21<00:02, 63.0MB/s]
Downloading: 88% 1.17G/1.33G [00:21<00:02, 66.3MB/s]
Downloading: 88% 1.17G/1.33G [00:21<00:02, 63.6MB/s]
Downloading: 89% 1.18G/1.33G [00:21<00:02, 66.1MB/s]
Downloading: 89% 1.19G/1.33G [00:21<00:02, 68.6MB/s]
Downloading: 90% 1.19G/1.33G [00:21<00:02, 63.2MB/s]
Downloading: 90% 1.20G/1.33G [00:21<00:02, 60.0MB/s]
Downloading: 91% 1.21G/1.33G [00:21<00:02, 62.4MB/s]
Downloading: 91% 1.21G/1.33G [00:22<00:01, 61.7MB/s]
Downloading: 92% 1.22G/1.33G [00:22<00:01, 60.3MB/s]
Downloading: 92% 1.22G/1.33G [00:22<00:01, 60.1MB/s]
Downloading: 93% 1.23G/1.33G [00:22<00:01, 62.2MB/s]
Downloading: 93% 1.24G/1.33G [00:22<00:01, 63.4MB/s]
Downloading: 94% 1.24G/1.33G [00:22<00:01, 64.4MB/s]
Downloading: 94% 1.25G/1.33G [00:22<00:02, 39.8MB/s]
Downloading: 95% 1.26G/1.33G [00:22<00:01, 47.0MB/s]
Downloading: 95% 1.26G/1.33G [00:23<00:01, 53.4MB/s]
Downloading: 96% 1.27G/1.33G [00:23<00:01, 56.3MB/s]
Downloading: 96% 1.28G/1.33G [00:23<00:00, 61.4MB/s]
Downloading: 97% 1.28G/1.33G [00:23<00:00, 65.0MB/s]
Downloading: 97% 1.29G/1.33G [00:23<00:00, 66.0MB/s]
Downloading: 98% 1.30G/1.33G [00:23<00:00, 67.6MB/s]
Downloading: 98% 1.30G/1.33G [00:23<00:00, 58.2MB/s]
Downloading: 99% 1.31G/1.33G [00:23<00:00, 60.7MB/s]
Downloading: 99% 1.32G/1.33G [00:23<00:00, 63.2MB/s]
Downloading: 100% 1.33G/1.33G [00:24<00:00, 59.2MB/s]
Some weights of the model checkpoint at roberta-large were not used when initializing RobertaModel: ['lm_head.layer_norm.bias', 'lm_head.dense.weight', 'lm_head.bias', 'lm_head.layer_norm.weight', 'lm_head.decoder.weight', 'lm_head.dense.bias']
- This IS expected if you are initializing RobertaModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing RobertaModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
scripts/eval/calc_data_f_score.py:94: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
return np.array([[calc_data_similarity(tgt, pred) for pred in pred_data] for tgt in tgt_data], dtype=np.float)
100% 728/728 [03:21<00:00, 3.60it/s]
Row header: precision = 96.04; recall = 95.84; f1 = 95.83
Col header: precision = 93.19; recall = 90.91; f1 = 91.66
Non-header cell: precision = 89.86; recall = 89.25; f1 = 89.08
Player table wrong format:
Args Namespace(col_header=True, hyp='checkpoints/checkpoint_average_best-3.pt.test_vanilla.out.text', row_header=True, table_name='Player', tgt='data/rotowire//test.data')
Wrong format: 5 / 724 (0.69%)
Team table E metric:
Args Namespace(col_header=True, hyp='checkpoints/checkpoint_average_best-3.pt.test_vanilla.out.text', metric='E', row_header=True, table_name='Player', tgt='data/rotowire//test.data')
0% 0/728 [00:00<?, ?it/s]scripts/eval/calc_data_f_score.py:94: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
return np.array([[calc_data_similarity(tgt, pred) for pred in pred_data] for tgt in tgt_data], dtype=np.float)
100% 728/728 [00:01<00:00, 536.42it/s]
Row header: precision = 94.75; recall = 89.75; f1 = 91.60
Col header: precision = 89.32; recall = 89.03; f1 = 87.73
Non-header cell: precision = 87.18; recall = 80.58; f1 = 82.74
Team table c metric:
Args Namespace(col_header=True, hyp='checkpoints/checkpoint_average_best-3.pt.test_vanilla.out.text', metric='c', row_header=True, table_name='Player', tgt='data/rotowire//test.data')
0% 0/728 [00:00<?, ?it/s]scripts/eval/calc_data_f_score.py:94: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
return np.array([[calc_data_similarity(tgt, pred) for pred in pred_data] for tgt in tgt_data], dtype=np.float)
100% 728/728 [00:03<00:00, 218.77it/s]
Row header: precision = 96.18; recall = 91.77; f1 = 93.46
Col header: precision = 92.43; recall = 91.77; f1 = 91.23
Non-header cell: precision = 89.21; recall = 82.67; f1 = 84.88
Team table BS-scaled metric:
Args Namespace(col_header=True, hyp='checkpoints/checkpoint_average_best-3.pt.test_vanilla.out.text', metric='BS-scaled', row_header=True, table_name='Player', tgt='data/rotowire//test.data')
0% 0/728 [00:00<?, ?it/s]Some weights of the model checkpoint at roberta-large were not used when initializing RobertaModel: ['lm_head.dense.bias', 'lm_head.bias', 'lm_head.layer_norm.bias', 'lm_head.decoder.weight', 'lm_head.dense.weight', 'lm_head.layer_norm.weight']
- This IS expected if you are initializing RobertaModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing RobertaModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
scripts/eval/calc_data_f_score.py:94: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
return np.array([[calc_data_similarity(tgt, pred) for pred in pred_data] for tgt in tgt_data], dtype=np.float)
100% 728/728 [06:13<00:00, 1.95it/s]
Row header: precision = 97.31; recall = 94.66; f1 = 95.78
Col header: precision = 95.45; recall = 94.96; f1 = 94.89
Non-header cell: precision = 93.13; recall = 88.26; f1 = 90.16
data/rotowire/test.text
The Atlanta Hawks (46 - 12) beat the Orlando Magic (19 - 41) 95 - 88 on Friday. Al Horford had a good all - around game, putting up 17 points, 13 rebounds, four assists and two steals in a tough matchup against Nikola Vucevic. Kyle Korver was the lone Atlanta starter not to reach double figures in points. Jeff Teague bounced back from an illness, he scored 17 points to go along with seven assists and two steals. After a rough start to the month, the Hawks have won three straight and sit atop the Eastern Conference with a nine game lead on the second place Toronto Raptors. The Magic lost in devastating fashion to the Miami Heat in overtime Wednesday. They blew a seven point lead with 43 seconds remaining and they might have carried that with them into Friday’s contest against the Hawks. Vucevic led the Magic with 21 points and 15 rebounds. Aaron Gordon (ankle) and Evan Fournier (hip) were unable to play due to injury. The Magic have four teams between them and the eighth and final playoff spot in the Eastern Conference. The Magic will host the Charlotte Hornets on Sunday, and the Hawks with take on the Heat in Miami on Saturday.
data/rotowire/test.data
Team:
| Losses | Total points | Points in 4th quarter | Wins | |
|---|---|---|---|---|
| Hawks | 12 | 95 | 46 | |
| Magic | 41 | 88 | 21 | 19 |
Player:
| Assists | Points | Total rebounds | Steals | |
|---|---|---|---|---|
| Nikola Vucevic | 21 | 15 | ||
| Al Horford | 4 | 17 | 13 | 2 |
| Jeff Teague | 7 | 17 | 2 |
Inference
输出文件位于: checkpoints/checkpoint_average_best-3.pt.test_vanilla.out.text
Team:
| Losses | Total points | Wins | |
|---|---|---|---|
| Hawks | 12 | 95 | 46 |
| Magic | 41 | 88 | 19 |
Player:
| Assists | Points | Total rebounds | Steals | |
|---|---|---|---|---|
| Nikola Vucevic | 21 | 15 | ||
| Al Horford | 4 | 17 | 13 | 2 |
| Jeff Teague | 7 | 17 | 2 |
更改
将测试数据进行减量
The Grizzlies (50) used a strong second half to outlast the Suns (3 - 2) 102 - 91 in Phoenix on Wednesday night. Memphis found itself behind six at halftime but outscored Phoenix 30 - 19 in the third quarter and 26 - 20 in the final period. The Grizzlies shot 50 percent from the field, led by strong performances from Courtney Lee and Mike Conley. Lee scored 22 points (9 - 14 FG, 4 - 5 3Pt), while Conley led all scorers with 24 (9 - 14 FG, 3 - 4 3Pt) and 11 assists. Marc Gasol added 18 points, six assists, and five rebounds. The Suns, who beat the Lakers 112 - 106 on Tuesday, were paced by 23 points (9 - 12 FG), five rebounds and four assists from Eric Bledsoe. It was a quiet night for Goran Dragic, who scored just six points in 26 minutes. The third member of the backcourt trio, Isaiah Thomas, had 15 points and two assists off the bench, while Markieff Morris added 20 points and five rebounds. The Grizzlies out - rebounded Phoenix 37 - 35 and outscored the Suns in the paint 46 - 32. Memphis also registered 25 assists compared to only 13 - on 32 field goals - for the Suns. Memphis now heads to Oklahoma City to take on the Thunder on Friday. Phoenix, meanwhile, hosts the Kings on Friday.
正确
Team:
| Number of team assists | Percentage of field goals | Losses | Total points | Points in 3rd quarter | Points in 4th quarter | Rebounds | Wins | |
|---|---|---|---|---|---|---|---|---|
| Suns | 13 | 2 | 91 | 19 | 20 | 35 | 3 | |
| Grizzlies | 25 | 50 | 102 | 30 | 26 | 37 |
Player:
| Assists | 3-pointers attempted | 3-pointers made | Field goals attempted | Field goals made | Minutes played | Points | Total rebounds | |
|---|---|---|---|---|---|---|---|---|
| Marc Gasol | 6 | 18 | 5 | |||||
| Courtney Lee | 5 | 4 | 14 | 9 | 22 | |||
| Mike Conley | 11 | 4 | 3 | 14 | 9 | 24 | ||
| Markieff Morris | 20 | 5 | ||||||
| Goran Dragic | 26 | 6 | ||||||
| Eric Bledsoe | 4 | 12 | 9 | 23 | 5 | |||
| Isaiah Thomas | 2 | 15 |
预测
Team:
| Number of team assists | Percentage of field goals | Losses | Total points | Points in 3rd quarter | Rebounds | Wins | |
|---|---|---|---|---|---|---|---|
| Suns | 2 | 91 | 19 | 35 | 3 | ||
| Grizzlies | 25 | 50 | 102 | 30 | 37 |
Player:
| Assists | 3-pointers attempted | 3-pointers made | Field goals attempted | Field goals made | Minutes played | Points | Total rebounds | |
|---|---|---|---|---|---|---|---|---|
| Markieff Morris | 20 | 5 | ||||||
| Goran Dragic | 26 | 6 | ||||||
| Isaiah Thomas | 2 | 15 | ||||||
| Eric Bledsoe | 4 | 12 | 9 | 23 | 5 | |||
| Courtney Lee | 5 | 4 | 14 | 9 | 22 | |||
| Marc Gasol | 6 | 18 | 5 | |||||
| Mike Conley | 11 | 4 | 3 | 14 | 9 | 24 |
疑问
- 既然是没有定义schema的信息抽取, 那schema表头和行头
欢迎在评论区中进行批评指正,转载请注明来源,如涉及侵权,请联系作者删除。

