参数高效微调方法综述
LLM的规模很大, 因为完全微调模型所花费的时间越来越多, 虽然也有小样本学习方向的尝试降低学习的成本同时保证训练的效果, 但是使用更多数据仍然是最可靠的提升效果的方式。 因此无论学界还是业界都需要一种高效的方法在下游任务数据上训练,这就为参数高效微调(Parameter-efficient fine-tuning,PEFT)带来了研究空间。PEFT的目的是只训练一小部分参数(可以是大模型自身的,也可以是额外引入的)就能提升模型在下游任务的效果。
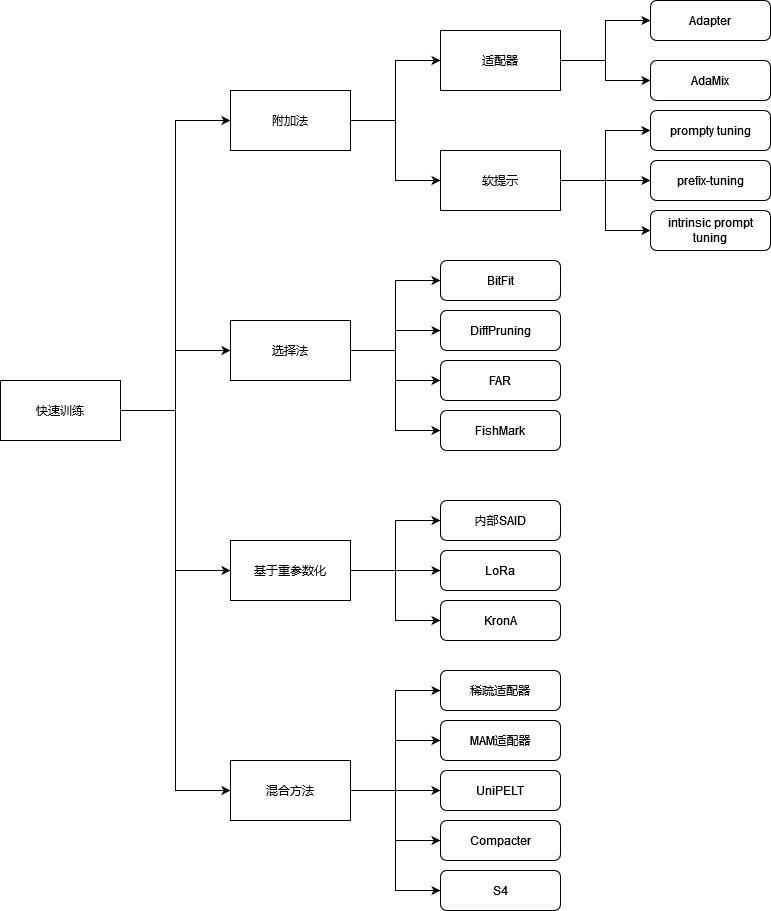
对参数高效微调方法进行分类的话, 大体可以分为以下几类:
一、附加法(additive method)
主要思路是使用额外参数或层增强现有预训练模型,也只训练这些新加入的参数。目前这是最大、最广为应用的PEFT方法。附加法有两种主要实现方式:
- 适配器(adapter),在Transformer子层后面加入小的全连接网络。变种包括修改其位置、裁剪以及使用重参数减少可训练参数量
- 软提示(soft prompt),语言模型的提示(prompt)目的是通过修改输入文本控制语言模型的行为。修改后的文本一般包括任务描述,后面跟一些上下文样例,但是这种方法难以优化,而且因为输入长度有限制,可利用的样例数量不多。为了弥补缺陷,软提示通过梯度下降来微调模型输入嵌入的一部分,因此将在离散空间中的问题转化为了连续优化问题。软提示可以只用在输入层,也可以用在所有层。最近的工作尝试预训练软提示,或者对不同任务做提示来减少新任务到来时软提示所需要微调的参数量
二、选择法(selective method)
对于选择法(selective method),最早的一批工作是只微调网络的最上面几层。另外一些方法包括只微调模型偏置项或者某些行。极端版本是稀疏更新模型,无视模型结构,只更新某些参数,但是这种方法在工程和效率上都带来了一些挑战。
三、基于重参数化的方法
基于重参数化的PEFT方法(reparametrization-based PEFT)利用的是低秩矩阵表示来减少可训练参数数量。Aghajanyan et al. (2020) 的研究表明在低秩子空间可以有效微调,而且需要适配的子空间大小比大模型或长时间预训练的模型空间要小。目前使用最多的基于重参数化的方法是低秩适配(Low-Rank Adaptation, LoRa),将权重更新做一个低秩矩阵分解。另一些工作探索使用Kronecker乘积重参数化,可以在秩和参数数量间找到更好的平衡。
四、混合法
另一些工作混杂了上述方法,例如MAM Adapter同时使用适配器和提示微调,UniPELT使用LoRa,Compacter和对适配器做重参数化。S4则是将所有PEFT方法组合起来形成一个自动算法
当前工作存在的问题
- 参数量不一致 参数数量可以分为三类:可训练参数的数量、微调模型与原始模型相比改变了的参数的数量、以及微调模型和原始模型之间差异的秩。例如,DiffPruning更新0.5%的参数,但是实际参与训练的参数量是200%。这为比较带来了困难。尽管可训练的参数量是最可靠的存储效率指标,但是也不完美。梯侧调整的使用一个单独的小网络,参数量高于LoRa或BitFit,但是因为反向传播不经过主网络,其消耗的内存反而更小
- 模型大小 已有工作表明大模型在微调中需要更新的参数量更小(无论是以百分比相对而论还是以绝对数量而论),因此(基)模型大小在比较不同PEFT方法时也要考虑到
- 缺乏测量基准和评价标准 不同方法所使用的的模型/数据集组合都不一样,评价指标也不一样,难以得到有意义的结论
- 实现问题 很多开源代码都是简单拷贝Transformer代码库然后小修小补。这些拷贝也不使用git fork,难以找出改了哪里。即便是能找到,可复用性也比较差(通常指定某个Transformer版本,没有说明如何脱离已有代码库复用这些方法)
欢迎在评论区中进行批评指正,转载请注明来源,如涉及侵权,请联系作者删除。

